标签:
根据mapjoin的计算原理,MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
mapjoin的应用场景如下:
1.有一个极小的表<1000行
2: 需要做不等值join的where操作(a.x < b.y 或者 a.x like b.y等,注:目前版本join下不支持不等值操作,不等值需加到where条件里)
如果把不等于写到where里会造成笛卡尔积,如果数据量很大,笛卡尔积的后果不可想象,速度可能慢的惊人!
根据mapjoin的计算原理,MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
如此看来,使用MAPJOIN开发的程序仅仅使用map一个过程就可以完成不等值join操作,效率还会有很大的提升。
案例讲解:
老板要显示会员每天的交易记录,没有记录的要显示0,数据库中没有交易的根本不会显示这条,怎么会显示为0呢,没办法,只能用会员每天汇总信息关联时间维表了。
测试数据请下载:会员每天交易信息汇总,16万左右数据: http://pan.baidu.com/s/1qWjp4ok
时间维表信息: 亲~ 自己构建吧。
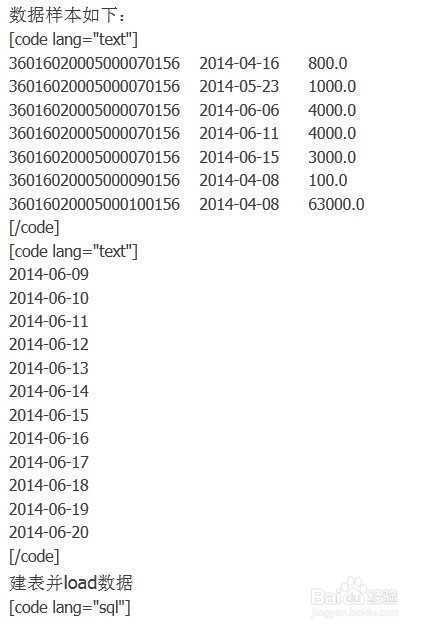
create table hive_mapjoin (id string,dt string,amt double)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ LINES TERMINATED BY ‘\n‘;
create table hive_dt (dt string);
load data local inpath ‘/lab/testdata/hive_mapjoin.txt‘ overwrite into table hive_mapjoin;
load data local inpath ‘/lab/testdata/hive_dt.txt‘ overwrite into table hive_dt;
--无mapjoin
create table hive_no_mapjoin as
--求会员有交易以来的连续时间
select f.id,f.dt, coalesce(k.amt,0.0) amt from(
--求会员交易最小时间
select a.id,t.dt from hive_dt t join (select id, min(dt) min_dt from hive_mapjoin group by id) a
where t.dt>= a.min_dt) f
left outer join hive_mapjoin k on f.dt = k.dt and f.id = k.id;
--有mapjoin
create table hive_ok_mapjoin as select f.id,f.dt, coalesce(k.amt,0.0) amt from(
--求会员有交易以来的连续时间
select /*+ mapjoin(t) */ a.id,t.dtfrom hive_dt t
join (
--求会员交易最小时间
select id, min(dt) min_dt from hive_mapjoin group by id) a
where t.dt>= a.min_dt) f
left outer join tmp.tst1 kon f.dt = k.dt and f.id = k.id;
测试结果:无mapjoin执行3分钟,有mapjoin执行2分钟
结果分析:样本数据太少,不到20万数据,小表数据不足200条,最终结果只有200多万。hive处理这点数据还是很轻松的,大家如果测试,建议数据量要大些,至少执行结果千万条以上才能看出效果
标签:
原文地址:http://www.cnblogs.com/xiejin/p/4250858.html