标签:
|
所谓c10k问题,指的是服务器同时支持成千上万个客户端的问题,也就是concurrent 10 000 connection(这也是c10k这个名字的由来)。由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器同时能够服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低,从这个角度来看,c10k问题显得非常有意义。 为了解决C10K问题,有各种各样的IO策略,它们的分歧或者说不同之处大概如下:
·
o
o
o
·
o
o
§
§
§
o
o 是否使用标准的OS 服务,更直接的方法是把部分代码放入内核中。
1. 这种方式很简单,它将所有的网络文件句柄的工作模式都设置成NON-BLOCKING,通过调用select()方法或者poll()方法来告诉应用层哪些个网络句柄有正在等待着并需要被处理的数据。这是一种非常传统的方法。通过这种机制,内核能够告诉应用层一个文件描述符是否准备好了(这里的准备好有着明确的含义,对于读描述符,准备好了意味着此时该描述符的缓冲区内数据已经准备好,读取该描述符的数据不会发生阻塞,而对于写描述符而言,准备好了意味着另外一层含义,它意味着写缓冲区已经准备好了,此时对该操作符的写操作也将不会导致任何阻塞发生),以及你是否已经利用该文件描述符作了相应的事情。因为这里的就绪通知方式是水平触发,也就说如果内核通知应用层某一个文件描述符已经就绪,而如果应用层此后一直没有完整的处理该描述符(没有读取完相应的数据或者没有写入任何数据),那么内核会不断地通知应用层该文件描述符已经就绪。这就是所谓的水平触发:只要条件满足,那内核就会触发一个事件(只要文件描述符对应的数据没有被读取或者写入,那内核就不断地通知你)。 需要注意的是:内核的就绪通知只是一个提示,提示也就意味着这个通知消息未必是100%准确的,当你读取一个就绪的读文件描述符时,实际上你有可能会发现这个描述符对应的数据并没有准备好。这就是为什么如果使用就绪通知的话一定要将文件描述符的模式设置成NOBLOCK的,因为NOBLOCK模式的读取或者写入在文件描述符没有就绪的时候会直接返回,而不是引起阻塞。如果这里发生了阻塞,那将是非常致命的,因为我们只有一个线程,唯一的线程被阻塞了的话,那我们就玩完了。 这种方式的一个缺陷就是不适用磁盘文件的IO操作。将磁盘文件的操作句柄的工作模式设置成NOBLOCK是无效的,此时对该磁盘文件进行读写依然有可能导致阻塞。对于缺乏AIO(异步IO)支持的系统,将磁盘IO操作委托给worker线程或者进程是一个好方法来绕过这个问题。一个可行的方法是使用memory mapped file,然后调用mincore(),mincore会返回一个向量来表示相应的page是否在ram缓存中,如果page不在ram缓存中,则意味着读取该页面会导致page falut,从而引起阻塞,那么就需要通过委托的worker线程来进行IO操作。这种方式的实现方法在Linux上就是select,poll这样的系统调用。
2. 所谓边沿触发是相对水平触发而言的,也就是说内核只是在文件描述符的状态发生变换的时候才进行通知。这就意味着在大多数情况下,当内核通知某个读描述符就绪后,除非该读描述符内部缓冲区的所有数据已经完全被读取从而使得就绪状态发生了变化,否则内核不会发出任何新的通知,会永远沉默下去。如果该文件描述符的receive操作返回EWOULDBLOCK错误码,这就意味着该描述符的就绪状态已经被打破,你需要等待下一次的边沿触发通知。 除了上面所说的问题,一旦使用了边沿触发,另外一个随之而来的问题就是,你需要注意一个常见的“意外事件”的问题。因为os实现边沿触发的一个常见的实现bug就是在某些情况下内核一旦收到新数据包就会通知就绪,不管你上一次的就绪通知是否被用户处理。因此你必须小心组织你的代码,你需要处理好每一个就绪通知,如果某一次就绪通知的数据没有被正确得完整得处理你就急急忙忙得开始等待下一次通知,那么下一次的就绪通知就会覆盖掉前面的数据,那么你就会永远不会恢复了。 相比之下,这种方式对于程序员编码的要求可能会更高一些,一旦应用程序错过了一次通知,那么与之对应的客户端就永远崩溃了(意外事件)或者沉默(没有读取完上一次事件产生的数据)。而方式1则会不断提醒用户缓冲区内还有数据。因此,对于边沿触发方式的就绪通知,应用层必须在每次就绪通知后读取数据,一直读到EWOULDBLOCK为止。 这种方式在Linux中主要通过epoll实现。实际上java nio采用的也是这种IO策略。Epoll和poll有一些共同之处,epoll在默认情况下也是水平触发的,此时你可以认为epoll是一个增强版的poll,它的效率更高,这是因为epoll采用了一些优化,比如只关心活跃的连接,通过共享内存空间避免了内存拷贝等等。
3. 这种IO策略实际上Linux并没有原生支持,尽管POSIX定义了它。相比之下windows就提供了很好的支持。异步IO也有内核通知,只不过这种通知不是就绪通知,而是完成通知,这就意味着一旦获得内核通知,那么IO操作就已经完成了,用户无需再调用任何操作来获取数据或者发送数据,此时数据已经好端端得放在用户定义的buffer中或者数据已经妥妥得发送出去了。与前两种方式相比,实际上aio是由内核线程或者底层线程异步地,默默得完成了IO操作,而方式1,方式2还得由用户线程来自己读取数据。相比之下,内核线程自然要高效很多。因此从IO模型的效率上来讲,windows是要优于Linux的。另外题外话再插一句,实际上微软的windows在很多概念上还是比较先进的,比如windows是微内核的,又比如这里的AIO,所以微软其实没有大家所想象的那么不堪,还是挺牛的。如果专业一点来讲,1和2这种方式一般被称之为reactor模式,3这种模式被称之为proactor模式。
4. 这种IO策略就比较老土了,也就是我们最常用的的一种IO模型,而且这种IO模型已经存在了几十年了。这种策略下,read和write调用都是阻塞的。它最大的问题就是每个线程都需要占据一个完整的栈帧,这个对内存的考验还是比较大的。而且过多的线程对OS也有很大的压力,很多OS如果有过多的线程其性能会有指数级别的下降。来算一下吧,假设栈帧的空间为2M,那么1G的内存最多服务512个线程,显然和我们的要求10K有不小的差距。当然,由于硬件的资源会越来越便宜,线程的内存开销可能不太会成为瓶颈。但多线程带来的进程切换的开销却有可能会长期存在。 这种IO策略的关键在于OS的线程要足够强大,高效。
5. 这种方式比较疯狂,如果你的team有足够的人手,而且服务器的需求量也比较大,你其实可以考虑这种方式。用专有的方法来解决问题其实也并非不可以,比如有的公司会把常用的核心算法放到FPGA或者ASIC芯片上去来解决问题,这两者的思路其实是如出一辙。对于Linux来讲,其实社区的意见还是不倾向于这么做,原因也很好理解,在内核中为应用开一个口子怎么看都不像一个好主意,一个更好的思路还是尽可能让用户空间的程序更快吧,别动不动就塞进内核里来。
好了,这就是目前为止关于解决C10K问题的一些思路,实际上思路2还是解决问题的主流方式。关于这个问题更多的资料大家可以参阅http://www.kegel.com/c10k.html#threaded,这个页面上对于C10K问题有着比较全面的分析和总结,本文实际上也只不过这个页面主要内容的一个摘要以及评注。
|
C10K problem是指如何让服务器能够支持10k并发,当然你可以买昂贵的服务器,但是还有更便宜的办法。
这是最著名的讲C10K问题的网页《The
C10K Problem》
在Linux下面,解决这个问题的技术首选当然是epoll啦,不过2.6以上kernel才支持...2.4的兄弟们打个patch吧。
epoll的接口非常简单,一共就三个函数:
1. int epoll_create(int size);
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
大家看看man就知道具体参数意思。
需要注意的是epoll有两个触发方式,类似于中断的两种触发方式:
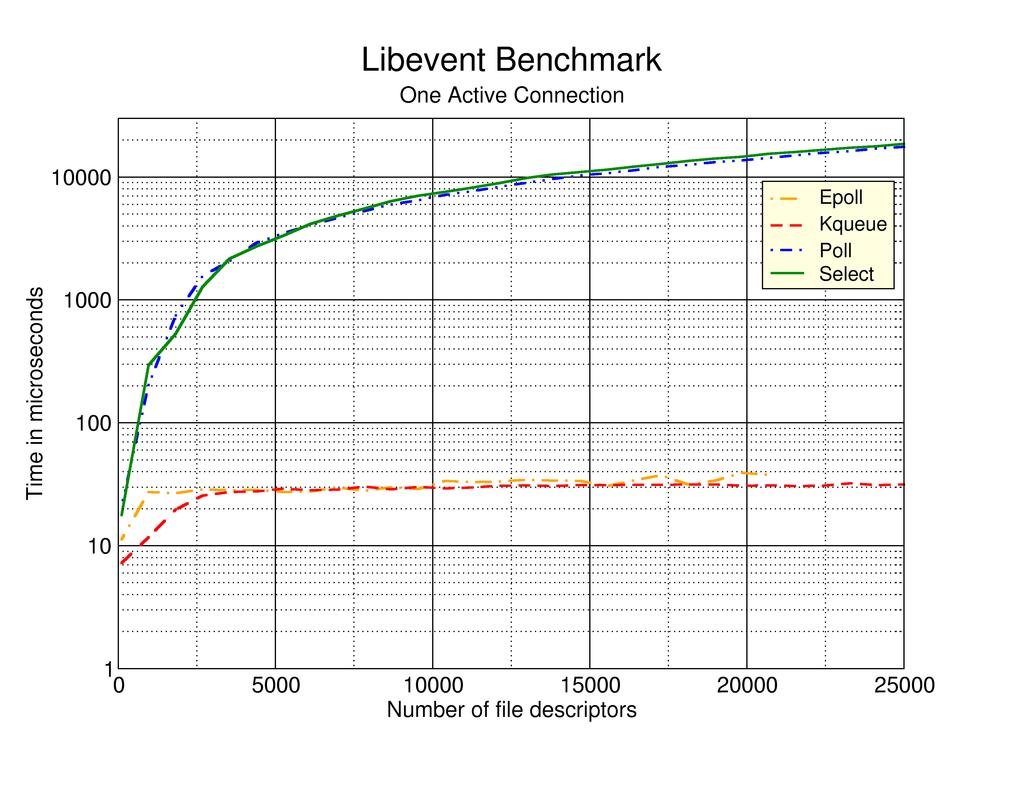
编写连接数巨大的高负载服务器程序时,经典的多线程模式和select模式都不再适用。
应当抛弃它们,采用epoll/kqueue/dev_poll来捕获I/O事件。最后简要介绍了AIO。
由来
网络服务在处理数以万计的客户端连接时,往往出现效率低下甚至完全瘫痪,这被称为
C10K问题。随着互联网的迅速发展,越来越多的网络服务开始面临C10K问题,作为大型
网站的开发人员有必要对C10K问题有一定的了解。本文的主要参考文献是
<http://www.kegel.com/c10k.html> http://www.kegel.com/c10k.htmls。
C10K问题的最大特点是:设计不够良好的程序,其性能和连接数及机器性能的关系往往
是非线性的。举个例子:如果没有考虑过C10K问题,一个经典的基于select的程序能在
旧服务器上很好处理1000并发的吞吐量,它在2倍性能新服务器上往往处理不了并发
2000的吞吐量。
这是因为在策略不当时,大量操作的消耗和当前连接数n成线性相关。会导致单个任务
的资源消耗和当前连接数的关系会是O(n)。而服务程序需要同时对数以万计的socket进
行I/O处理,积累下来的资源消耗会相当可观,这显然会导致系统吞吐量不能和机器性
能匹配。为解决这个问题,必须改变对连接提供服务的策略。
基本策略
主要有两方面的策略:1.应用软件以何种方式和操作系统合作,获取I/O事件并调度多
个socket上的I/O操作;2. 应用软件以何种方式处理任务和线程/进程的关系。前者主
要有阻塞I/O、非阻塞I/O、异步I/O这3种方案,后者主要有每任务1进程、每任务1线
程、单线程、多任务共享线程池以及一些更复杂的变种方案。常用的经典策略如下:
1. Serve one client with each thread/process, and use blocking I/O
这是小程序和java常用的策略,对于交互式的长连接应用也是常见的选择(比如BBS)。
这种策略很能难足高性能程序的需求,好处是实现极其简单,容易嵌入复杂的交互逻
辑。Apache、ftpd等都是这种工作模式。
2. Serve many clients with single thread, and use nonblocking I/O
and readiness notification
这是经典模型,datapipe等程序都是如此实现的。优点在于实现较简单,方便移植,也
能提供足够的性能;缺点在于无法充分利用多CPU的机器。尤其是程序本身没有复杂的
业务逻辑时。
3. Serve many clients with each thread, and use nonblocking I/O and
readiness notification
对经典模型2的简单改进,缺点是容易在多线程并发上出bug,甚至某些OS不支持多线程
操作readiness notification。
4. Serve many clients with each thread, and use asynchronous I/O
在有AI/O支持的OS上,能提供相当高的性能。不过AI/O编程模型和经典模型差别相当
大,基本上很难写出一个框架同时支持AI/O和经典模型,降低了程序的可移植性。在
Windows上,这基本上是唯一的可选方案。
本文主要讨论模型2的细节,也就是在模型2下应用软件如何处理Socket I/O。
select 与 poll
最原始的同步阻塞 I/O 模型的典型流程如下:
同步阻塞 I/O 模型的典型流程
从应用程序的角度来说,read 调用会延续很长时间,应用程序需要相当多线程来解决
并发访问问题。同步非阻塞I/O对此有所改进:
经典的单线程服务器程序结构往往如下:
do {
Get Readiness Notification of all sockets
Dispatch ready handles to corresponding handlers
If (readable) {
read the socket
If (read done)
Handler process the request
}
if (writable)
write response
if (nothing to do)
close socket
} while(True)
非阻塞 I/O 模型的典型流程:
异步阻塞 I/O 模型的典型流程
其中关键的部分是readiness notification,找出哪一个socket上面发生了I/O事件。
一般从教科书和例子程序中首先学到的是用select来实现。Select定义如下:
int select(int n, fd_set *rd_fds, fd_set *wr_fds, fd_set *ex_fds, struct
timeval *timeout);
在ACE环境中,ACE_Select_Reactor针对这一点特别作了保护措施,但是还是有recv_n
这样的函数间接的使用了select,这需要大家注意。
针对fd_set的问题,*nix提供了poll函数作为select的一个替代品。Poll的接口如下:
int poll(struct pollfd *ufds, unsigned int nfds, int timeout);
第1个参数ufds是用户提供的一个pollfd数组,数组大小由用户自行决定,因此避免了
FD_SETSIZE带来的麻烦。Ufds是fd_set的一个完全替代品,从select到poll的移植很方
便。到此为止,至少我们面对C10K,可以写出一个能work的程序了。
然而Select和Poll在连接数增加时,性能急剧下降。这有两方面的原因:首先操作系统
面对每次的select/poll操作,都需要重新建立一个当前线程的关心事件列表,并把线
程挂在这个复杂的等待队列上,这是相当耗时的。其次,应用软件在select/poll返回
后也需要对传入的句柄列表做一次扫描来dispatch,这也是很耗时的。这两件事都是和
并发数相关,而I/O事件的密度也和并发数相关,导致CPU占用率和并发数近似成O(n2)
的关系。
epoll, kqueue, /dev/poll
因为以上的原因,*nix的hacker们开发了epoll, kqueue, /dev/poll这3套利器来帮助
大家,让我们跪拜三分钟来感谢这些大神。其中epoll是linux的方案,kqueue是
freebsd的方案,/dev/poll是最古老的Solaris的方案,使用难度依次递增。
简单的说,这些api做了两件事:1.避免了每次调用select/poll时kernel分析参数建立
事件等待结构的开销,kernel维护一个长期的事件关注列表,应用程序通过句柄修改这
个列表和捕获I/O事件。2.避免了select/poll返回后,应用程序扫描整个句柄表的开
销,Kernel直接返回具体的事件列表给应用程序。
在接触具体api之前,先了解一下边缘触发(edge trigger)和条件触发(level trigger)
的概念。边缘触发是指每当状态变化时发生一个io事件,条件触发是只要满足条件就发
生一个io事件。举个读socket的例子,假定经过长时间的沉默后,现在来了100个字
节,这时无论边缘触发和条件触发都会产生一个read ready notification通知应用程
序可读。应用程序读了50个字节,然后重新调用api等待io事件。这时条件触发的api会
因为还有50个字节可读从而立即返回用户一个read ready notification。而边缘触发
的api会因为可读这个状态没有发生变化而陷入长期等待。
因此在使用边缘触发的api时,要注意每次都要读到socket返回EWOULDBLOCK为止,否则
这个socket就算废了。而使用条件触发的api时,如果应用程序不需要写就不要关注
socket可写的事件,否则就会无限次的立即返回一个write ready notification。大家
常用的select就是属于条件触发这一类,以前本人就犯过长期关注socket写事件从而
CPU 100%的毛病。
epoll的相关调用如下:
int epoll_create(int size)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int
timeout)
epoll_create创建kernel中的关注事件表,相当于创建fd_set。
epoll_ctl修改这个表,相当于FD_SET等操作
epoll_wait等待I/O事件发生,相当于select/poll函数
epoll完全是select/poll的升级版,支持的事件完全一致。并且epoll同时支持边缘触
发和条件触发,一般来讲边缘触发的性能要好一些。这里有个简单的例子:
struct epoll_event ev, *events;
int kdpfd = epoll_create(100);
ev.events = EPOLLIN | EPOLLET; // 注意这个EPOLLET,指定了边缘触发
ev.data.fd =listener;
epoll_ctl(kdpfd, EPOLL_CTL_ADD, listener, &ev);
for(;;) {
nfds = epoll_wait(kdpfd, events, maxevents, -1);
for(n = 0; n < nfds; ++n) {
if(events[n].data.fd == listener) {
client = accept(listener, (struct sockaddr *) &local,
&addrlen);
if(client < 0){
perror("accept");
continue;
}
setnonblocking(client);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = client;
if (epoll_ctl(kdpfd, EPOLL_CTL_ADD, client, &ev) < 0) {
fprintf(stderr, "epoll set insertion error: fd=%d0,
client);
return -1;
}
}
else
do_use_fd(events[n].data.fd);
}
}
简单介绍一下kqueue和/dev/poll
kqueue是freebsd的宠儿,kqueue实际上是一个功能相当丰富的kernel事件队列,它不
仅仅是select/poll的升级,而且可以处理signal、目录结构变化、进程等多种事件。
Kqueue是边缘触发的
/dev/poll是Solaris的产物,是这一系列高性能API中最早出现的。Kernel提供一个特
殊的设备文件/dev/poll。应用程序打开这个文件得到操纵fd_set的句柄,通过写入
pollfd来修改它,一个特殊ioctl调用用来替换select。由于出现的年代比较早,所以
/dev/poll的接口现在看上去比较笨拙可笑。
C++开发:ACE 5.5以上版本提供了ACE_Dev_Poll_Reactor封装了epoll和/dev/poll两种
api,需要分别在config.h中定义ACE_HAS_EPOLL和ACE_HAS_DEV_POLL来启用。
Java开发: JDK 1.6的Selector提供了对epoll的支持,JDK1.4提供了对/dev/poll的支
持。只要选择足够高的JDK版本就行了。
异步I/O以及Windows
和经典模型不同,异步I/O提供了另一种思路。和传统的同步I/O不同,异步I/O允许进
程发起很多 I/O 操作,而不用阻塞或等待任何操作完成。稍后或在接收到 I/O 操作完
成的通知时,进程就可以检索 I/O 操作的结果。
异步非阻塞 I/O 模型是一种处理与 I/O 重叠进行的模型。读请求会立即返回,说明
read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操
作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成
这次 I/O 处理过程。异步I/O 模型的典型流程:
异步非阻塞 I/O 模型的典型流程
对于文件操作而言,AIO有一个附带的好处:应用程序将多个细碎的磁盘请求并发的提
交给操作系统后,操作系统有机会对这些请求进行合并和重新排序,这对同步调用而言
是不可能的——除非创建和请求数目同样多的线程。
Linux Kernel 2.6提供了对AIO的有限支持——仅支持文件系统。libc也许能通过来线
程来模拟socket的AIO,不过这对性能没意义。总的来说Linux的aio还不成熟
Windows对AIO的支持很好,有IOCP队列和IPCP回调两种方式,甚至提供了用户级异步调
用APC功能。Windows下AIO是唯一可用的高性能方案,详情请参考MSDN。
标签:
原文地址:http://blog.csdn.net/g__hk/article/details/43164247