标签:
/* Class for returning a fetched block and associated metrics. */
private[spark] class BlockResult(
val data: Iterator[Any],
readMethod: DataReadMethod.Value,
bytes: Long) {
val inputMetrics = new InputMetrics(readMethod)
inputMetrics.bytesRead = bytes
}
private[spark] class BlockManager(
executorId: String,
actorSystem: ActorSystem,
val master: BlockManagerMaster,
defaultSerializer: Serializer,
maxMemory: Long,
val conf: SparkConf,
securityManager: SecurityManager,
mapOutputTracker: MapOutputTracker,
shuffleManager: ShuffleManager)
extends BlockDataProvider with Logging {
/**
* Contains all the state related to a particular shuffle. This includes a pool of unused
* ShuffleFileGroups, as well as all ShuffleFileGroups that have been created for the shuffle.
*/
private class ShuffleState(val numBuckets: Int) {
val nextFileId = new AtomicInteger(0)
val unusedFileGroups = new ConcurrentLinkedQueue[ShuffleFileGroup]()
val allFileGroups = new ConcurrentLinkedQueue[ShuffleFileGroup]()
/**
* The mapIds of all map tasks completed on this Executor for this shuffle.
* NB: This is only populated if consolidateShuffleFiles is FALSE. We don‘t need it otherwise.
*/
val completedMapTasks = new ConcurrentLinkedQueue[Int]()
}
private val shuffleStates = new TimeStampedHashMap[ShuffleId, ShuffleState]
private val metadataCleaner =
new MetadataCleaner(MetadataCleanerType.SHUFFLE_BLOCK_MANAGER, this.cleanup, conf)
/**
* Register a completed map without getting a ShuffleWriterGroup. Used by sort-based shuffle
* because it just writes a single file by itself.
*/
def addCompletedMap(shuffleId: Int, mapId: Int, numBuckets: Int): Unit = {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
val shuffleState = shuffleStates(shuffleId)
shuffleState.completedMapTasks.add(mapId)
}
/**
* Initialize the BlockManager. Register to the BlockManagerMaster, and start the
* BlockManagerWorker actor.
*/
private def initialize(): Unit = {
master.registerBlockManager(blockManagerId, maxMemory, slaveActor)
BlockManagerWorker.startBlockManagerWorker(this)
}
/**
* A short-circuited method to get blocks directly from disk. This is used for getting
* shuffle blocks. It is safe to do so without a lock on block info since disk store
* never deletes (recent) items.
*/
def getLocalFromDisk(blockId: BlockId, serializer: Serializer): Option[Iterator[Any]] = {
diskStore.getValues(blockId, serializer).orElse {
throw new BlockException(blockId, s"Block $blockId not found on disk, though it should be")
}
}
/** A group of writers for a ShuffleMapTask, one writer per reducer. */
private[spark] trait ShuffleWriterGroup {
val writers: Array[BlockObjectWriter]
/** @param success Indicates all writes were successful. If false, no blocks will be recorded. */
def releaseWriters(success: Boolean)
}
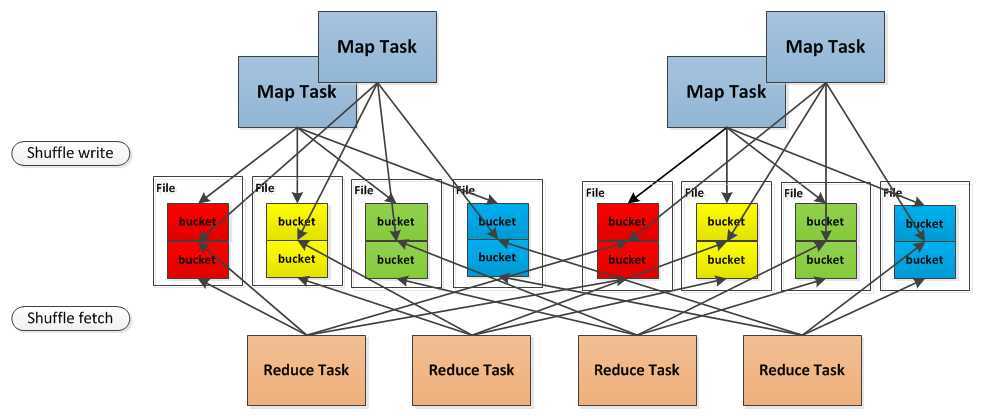
/**
* Manages assigning disk-based block writers to shuffle tasks. Each shuffle task gets one file
* per reducer (this set of files is called a ShuffleFileGroup).
*
* As an optimization to reduce the number of physical shuffle files produced, multiple shuffle
* blocks are aggregated into the same file. There is one "combined shuffle file" per reducer
* per concurrently executing shuffle task. As soon as a task finishes writing to its shuffle
* files, it releases them for another task.
* Regarding the implementation of this feature, shuffle files are identified by a 3-tuple:
* - shuffleId: The unique id given to the entire shuffle stage.
* - bucketId: The id of the output partition (i.e., reducer id)
* - fileId: The unique id identifying a group of "combined shuffle files." Only one task at a
* time owns a particular fileId, and this id is returned to a pool when the task finishes.
* Each shuffle file is then mapped to a FileSegment, which is a 3-tuple (file, offset, length)
* that specifies where in a given file the actual block data is located.
*
* Shuffle file metadata is stored in a space-efficient manner. Rather than simply mapping
* ShuffleBlockIds directly to FileSegments, each ShuffleFileGroup maintains a list of offsets for
* each block stored in each file. In order to find the location of a shuffle block, we search the
* files within a ShuffleFileGroups associated with the block‘s reducer.
*/
// TODO: Factor this into a separate class for each ShuffleManager implementation
private[spark]
class ShuffleBlockManager(blockManager: BlockManager,
shuffleManager: ShuffleManager) extends Logging {
private[spark]
object ShuffleBlockManager {
/**
* A group of shuffle files, one per reducer.
* A particular mapper will be assigned a single ShuffleFileGroup to write its output to.
*/
private class ShuffleFileGroup(val shuffleId: Int, val fileId: Int, val files: Array[File]) {
private var numBlocks: Int = 0
/**
* Stores the absolute index of each mapId in the files of this group. For instance,
* if mapId 5 is the first block in each file, mapIdToIndex(5) = 0.
*/
private val mapIdToIndex = new PrimitiveKeyOpenHashMap[Int, Int]()
/**
* Stores consecutive offsets and lengths of blocks into each reducer file, ordered by
* position in the file.
* Note: mapIdToIndex(mapId) returns the index of the mapper into the vector for every
* reducer.
*/
private val blockOffsetsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
private val blockLengthsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
def apply(bucketId: Int) = files(bucketId)
def recordMapOutput(mapId: Int, offsets: Array[Long], lengths: Array[Long]) {
assert(offsets.length == lengths.length)
mapIdToIndex(mapId) = numBlocks
numBlocks += 1
for (i <- 0 until offsets.length) {
blockOffsetsByReducer(i) += offsets(i)
blockLengthsByReducer(i) += lengths(i)
}
}
/** Returns the FileSegment associated with the given map task, or None if no entry exists. */
def getFileSegmentFor(mapId: Int, reducerId: Int): Option[FileSegment] = {
val file = files(reducerId)
val blockOffsets = blockOffsetsByReducer(reducerId)
val blockLengths = blockLengthsByReducer(reducerId)
val index = mapIdToIndex.getOrElse(mapId, -1)
if (index >= 0) {
val offset = blockOffsets(index)
val length = blockLengths(index)
Some(new FileSegment(file, offset, length))
} else {
None
}
}
}
}
标签:
原文地址:http://www.cnblogs.com/zwCHAN/p/4253287.html