标签:
在经过几天的环境搭建,终于搭建成功,其中对于hadoop的具体设置倒是没有碰到很多问题,反而在hadoop各节点之间的通信遇到了问题,而且还反复了很多遍,光虚拟机就重新安装了4、5次,但是当明白了问题之后才发现这都是无用功,有了问题应该找具体的解决方案,并不是完全的重装,这样不会明白问题是怎么解决的,除了费时费力没有多大的用处,接下来就把搭建的过程详细叙述一下。
环境配置:
计算机:
CPU-I7 2630QM
6G内存
256G SSD
虚拟机:
vmware workstation 11
系统:
ubuntu 14.04 LTS
节点:
192.168.1.150 master
192.168.1.151 slave1
192.168.1.151 slave2
参考:
http://www.aboutyun.com/thread-7684-1-1.html
http://my.oschina.net/u/2285247/blog/354449
http://www.aboutyun.com/thread-5738-1-1.html
http://www.aboutyun.com/thread-6446-1-1.html
安装步骤:
1、安装虚拟机系统(安装1个即可,其余的可以通过克隆),并进行准备工作
2、安装JDK,并配置环境变量
3、克隆虚拟机系统,并修改hosts、hostname
4、配置虚拟机网络,使虚拟机系统之间以及和host主机之间可以通过相互ping通。
5、配置ssh,实现节点间的无密码登录
6、master配置hadoop,并将hadoop文件传输到slave节点
7、配置环境变量,并启动hadoop,检查是否安装成功
1、安装虚拟机系统,并进行准备工作
安装虚拟机系统不用赘述,安装vmware——新建虚拟机——典型——选择镜像——设置账户密码——安装位置——配置——安装。
当虚拟机安装成功后,默认的是nat模式,不要立即将网络模式切换到桥接模式下,这时nat模式下应该可以联网,先安装几个软件,以后需要用到,当然在桥接模式下也可以联网,但是桥接模式是要设置成静态IP的,局限性比较大,下载安装完以后,接下来就不用联网了。
#切换到root模式下
#刚开始root是默认不开启的,可以利用如下命令对root密码进行设置
sudo passwd root
#现在在root模式先安装vim,命令如下:
apt-get install vim
#安装ssh
apt-get install ssh
#这个步骤是可选的,用于更新,以及将ssh相关都安装
apt-get install openssh*
apt-get update
2、安装jdk,并配置环境变量
1)从oracle下载jdk安装包,并将安装包拖入到虚拟机当中
2)通过cd命令进入到安装包的当前目录,利用如下命令进行解压缩。
tar -zxvf jdk.....(安装包名称)
3)利用如下命令将解压后的文件夹移到/usr目录下
#注意,这样移动到/usr以后就没有jdk1.8...这个目录了,是将这个目录下的所有文件全部移动到/usr/java下,
mv jdk1.8...(文件夹名称) /usr/java
4)配置环境变量
#切换到root模式下
su - root
#利用vim编辑/etc/profile(这个是对全体用户都起作用的)
vim /etc/profile
#将一下两句加入到其中,并保存退出
export PATH=$PATH:/usr/java/bin:/usr/java/jre/bin
export CLASSPATH=.:/usr/java/lib:/usr/java/jre/lib
#然后使profile生效
source /etc/profile
#试验java、javac、java -version
3、克隆虚拟机并修改三个虚拟机的hosts、hostname
1)克隆虚拟机时要注意一定要选择完整克隆
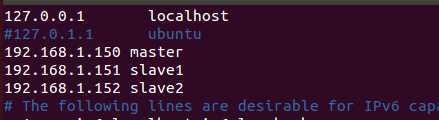
2)修改hosts(三个虚拟机都要改)
#root下用vim打开hosts
vim /etc/hosts
#将以下内容添加到hosts中
192.168.1.150 master
192.168.1.151 slave1
192.168.1.152 slave2
如图:
3)修改hostname(三个虚拟机都要改)
#root下打开hostname
vim /etc/hostname
#分别将每个虚拟机改成对应的name(master、slave1、slave2)
4、配置虚拟机网络
在安装好虚拟机后,虚拟机有三种模式分别是nat模式、仅主机模式、桥接模式,此处对于此三种模式进行简单介绍:
nat模式:这是通nat地址转换共享主机Ip的模式,在安装好虚拟机后会发现有vmnet8虚拟网卡,这个网卡默认是nat模式,这时nat模式下的虚拟机相当于又组成一个局域网,而vmnet8相当于这个局域网的网关,在这种模式下,虚拟机之间可以相互ping通,但是不能与主机通信,因为主机与虚拟机之间有有一个vmnet8网卡。当然通过配置vmnet8网卡可以实现通信。
仅主机模式:这种模式没有地址转换能力,各个虚拟机之间是相互独立的,不能相互访问,每个虚拟机只能与主机通信。
桥接模式:这种模式是将虚拟网卡直接绑定到物理网卡上,可以绑定多个地址,这里是将网卡设置成混杂模式,然后实现可以收发多个地址的消息。
本人搭建环境采用的是桥接模式,这种模式拟真性更强一些,虽然有些麻烦。
注意:要将三个虚拟机的ip与主机都处于同一个网段,然后实验是否可以Ping通
5、配置ssh,实现节点间的无密码登录 (注意关闭防火墙 ufw disable)
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
2)导入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3)试验看是否安装成功
#查看是否有sshd进程
ps -e | grep ssh
#尝试登录本地
ssh localhost
4)远程无密码登录
#进入master的.ssh目录
scp authorized_keys u0@slave1:~/.ssh/authorized_keys_master
#u0是我的用户名
#进入slave1、slave2的.ssh目录
cat authorized_keys_master >> authorized_keys
注意:第四步要在slave上重复,要使三者都能够无密码相互登录,重复完后可以利用如下命令试验,第一次需要输入密码绑定
ssh salve1(slave2)
注意:我的主机是连接的路由无线网络,我遇到了一个问题,就是在虚拟机网络重连后master可以登录slave2,但是过一会后就发现老是connection refused,就因为这个问题我还重新安装了几次,网络上的方法都试了也不管用,后来发现,原来是我的虚拟机ip与路由局域网中的其他机器Ip冲突,千万要保证局域网内的Ip不要和虚拟机的ip冲突
6、master配置hadoop,并将hadoop文件传输到slave节点
1)解包移动
#解压hadoop包
tar -zxvf hadoop...
#将安装包移到/usr目录下
mv hadoop... /usr/hadoop
2)新建文件夹
#在/usr/hadoop目录下新建如下目录(root)
mkdir /dfs
mkdir /dfs/name
mkdir /dfs/data
mkdir /tmp
3)配置文件:hadoop-env.sh(文件都在/usr/hadoop/etc/hadoop中)
修改JAVA_HOME值(export JAVA_HOME=/usr/java)
5)配置文件:slaves
将内容修改为:
slave1
slave2
6)配置文件:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.u0.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.u0.groups</name>
<value>*</value>
</property>
</configuration>
7)配置文件:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8)配置文件:mapred-site.xml
<configuration> <property>
<name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
9)配置文件:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
10)将hadoop传输到slave1和slave2根目录
scp -r /usr/hadoop u0@slave1:~/
7、配置环境变量,并启动hadoop,检查是否安装成功
1)配置环境变量
#root模式编辑/etc/profile
vim /etc/profile
#以上已经添加过java的环境变量,在后边添加就可以
export PATH=$PATH:/usr/java/bin:/usr/java/jre/bin:/usr/hadoop/bin:/usr/hadoop/sbin
2)启动hadoop
#注意最后单词带‘-’
hadoop namenode -format
start-all.sh
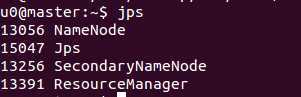
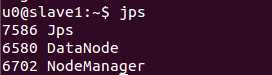
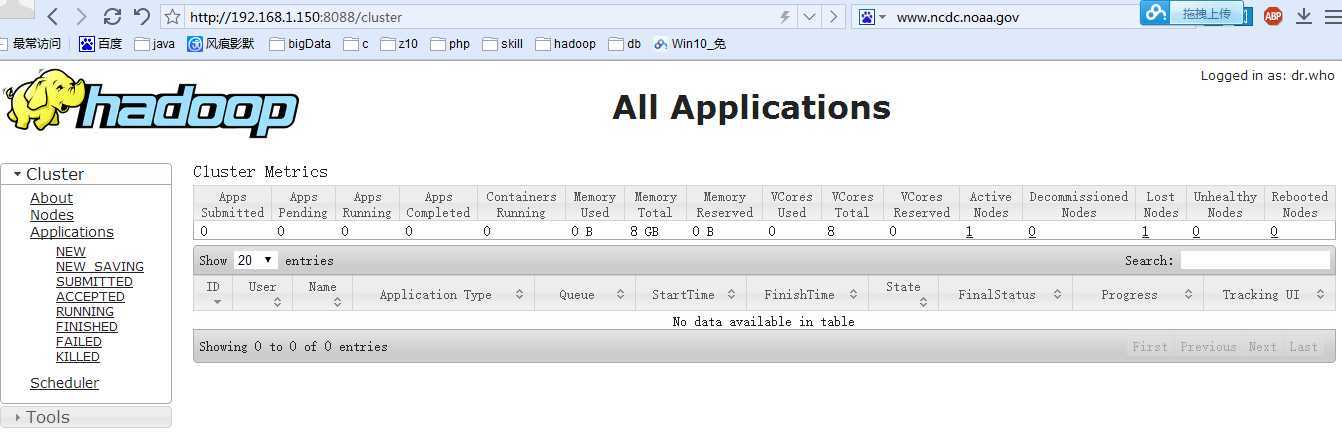
3)查看启动进程
标签:
原文地址:http://www.cnblogs.com/fantasy01/p/4256783.html