标签:c style class blog java tar
声明:
1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究。
2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好)。如不清楚配置可看《Hadoop之词频统计小实验初步配置》
3)本文由于过长,无法一次性上传。其相邻相关的博文,可参见《Hadoop的改进实验(中文分词词频统计及英文词频统计) 博文目录结构》,以阅览其余三篇剩余内容文档。
百度开放研究云平台由百度开放研究计划支持而建设的。当前已建成基于开源Hadoop 1.0.0而构建的开放数据分析平台,将逐步投入数百台服务器来支持海量数据分析。我们也将不断在平台上放置来自百度产品和系统的数据供学术研究使用。来自学术界的使用者可以在该平台上开展数据分析的研究。
网址为:http://openresearch.baidu.com/activity/platform.jspx
百度开放研究云平台是面向学术界免费使用的。有意使用者可以向campuscloud@baidu.com发信了解更多信息。为了使用户在开放研究云平台上有与通过命令行使用Hadoop一致的体验,也为了提高在开放环境下使用Hadoop平台的安全性,百度开放研究云平台提供基于WEB的使用界面,提供类似web shell的使用方式。用户通过WEB页面的输入区域提交命令,并在WEB页面上展示命令执行过程及相应的输出信息。
由于百度开放研究云平台是面向学术研究的公益性平台,该平台不保证其上数据的可靠性和持久性,请使用者在使用过程注意自己数据的安全,不要泄露隐私和商业秘密。同时,由于该平台还在不断发展中,缺陷和漏洞在所难免。请使用者随时告知您的使用意见以让我们不断改进。同时,请不要利用平台缺陷和漏洞攻击该系统或者基于该系统攻击其它系统。并协调资源利用并合理使用,以便更多的研究者可以在该平台上开展研究工作。。
开放云所开放免费的项目,可如下图所示。根据下图可知,开放云提供Hadoop平台入口,Mahout入口,HBase数据仓库等,也免费分享一些数据集。
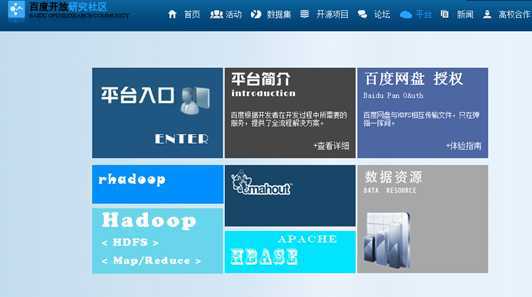
一是、基于单机配置Hadoop的学习完成之前,可以抢先体验Hadoop。
二是、基于单机配置Hadoop的学习完成之后,不满足于单机分布的云计算模式,然而又没有足够主机实现多分布节点模式的情形下,可以利用百度开放云。其性能优于单或多个主机,然而不能满足集群需要。对于有时统计较多数据的情形下,自身笔记本性能不能满足的情形下,可以尝试百度云。
三是,对于新手而言,或者对于课程入门而言,可以使用百度开放云,简化相关操作流程(Mahout或Hadoop插件配置非常复杂且占据主机硬盘),使用百度开放云可以节约时间,将重点放在多实践上。
四是、对于各互联网公司的云服务器Hadoop真实集群配置不一定掌握,且配置远程云服务器不同于单机,可能出现更多意想不到的问题。有百度开放云,可以直接利用配置开发好的资源。
我们选择百度开放云里的Hadoop入口(使用前随便注册一个账号)
clear(缩写为cls):清除web Shell的内容。
logout:退出web shell。
help:显示当前可用的命令及简短说明
hadoop: 用于访问Hadoop的功能,其使用方式与命令行使用hadoop的方式一致。对于普通用户权限,其能够使用的hadoop命令包括hadoop fs,hadoop jar,hadoop job等。相对于hadoop命令的本地文件系统的当前路径即为用户的工作目录。
为了访问hadoop系统的某些模块,平台也提供了三个变量可以直接使用,包括: $hadoop_home(hadoop系统的根目录);
$hadoop_examples(hadoop-examples-1.0.0.jar的路径);
$hadoop_streaming(hadoop-streaming-1.0.0.jar的路径)。
ls: 列举目录内容,与Linux命令ls功能和使用方法相同,但所列目录和文件限于工作目录内。
mkdir:创建子目录,限于工作目录及其子目录内。
mv:移动文件或目录,移动的文件和目录必须位于工作目录下且目标地址也在工作目录下。
rm:删除文件和目录,所删除的文件和目录必须位于工作目录内。
upload:从使用者本地通过网页上载文件到工作目录下。如图2所示。运行upload命令后会弹出一个窗口,在该窗口内选择需要上载的本地文件,点击"upload"按钮可以开始上载,而右上角的Status处会显示上载的进程及结果。当前,上载的目标目录限定为用户的工作目录,还不能选择其它目标目录。需要注意的是,上载文件限定为10MB,超过大小限制的文件将无法上载。
download:从使用者的工作目录通过网页下载文件到本地目录。运行download命令后会弹出窗口让用户选择本地保存的位置。需要注意的是,下载文件的大小限定为10MB,超过大小限制的文件将无法下载。
一、此百度开放云的Hadoop系统置于某OS系统内,个人认为是一种服务器式的操作系统。
二、不支持cd打开文件命令。所以如果想要在文件夹内放文件,必须先新建文件夹,上传文件与文件夹为平行目录,然后将平行目录下的文件mv(剪切)到文件夹内,最后删掉平行目录下的文件。这样就可以完成文件夹内有文件的操作了。很是麻烦。
三、第一次使用时,你看到Hadoop分布式目录里会有很多文件,甚至你会看到其他用户的文件。(当然你进不去其他用户的目录,你只是能看见路径而已,即便如此,隐私性还是不足,因为我看到你的路径下的文件名后,可以猜测你的工作性质与程序用途。)如下图所示。这里只展示其他用户名,没有给出其他用户的文件名路径。
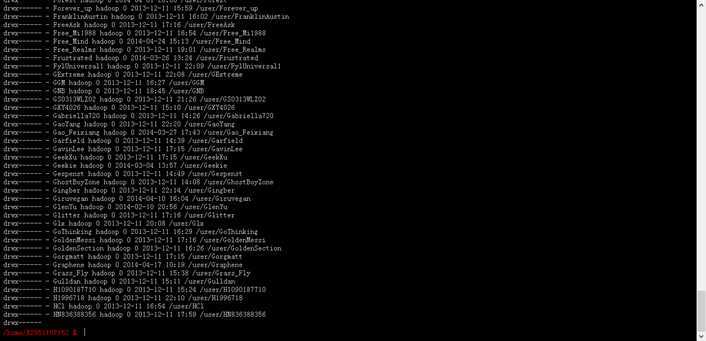
四、第一次使用时,使用hadoop shell命令查看分布式系统文件,可能会出问题,上面提到可能会看到很多文件,或不应该出现的文件。原因在于,一是你还没有向分布式系统内传文件,当你向分布式内传输文件后,自然就可以看到。二是百度为共享资源,特别在Hadoop内设置一个共享云,大家都可以使用。
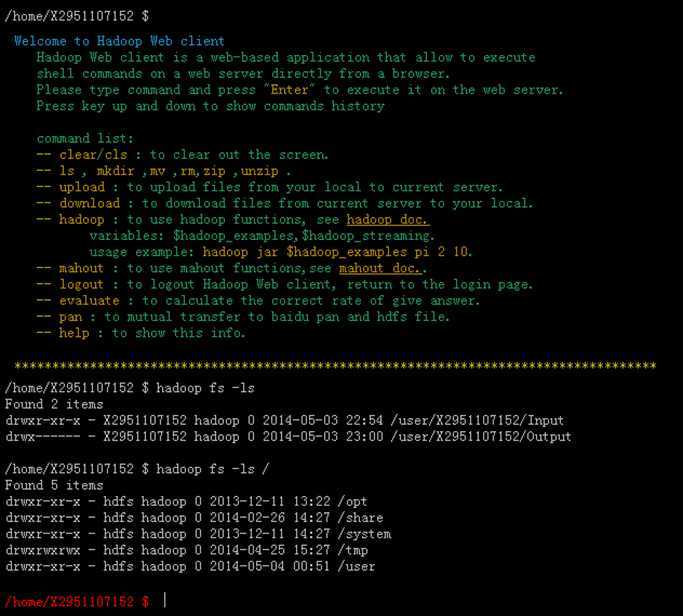
五、用过Hadoop知道,分布式目录大概都在/user/***下,可以是/user/root,也可以是/user/username。在百度开放云上,建议直接使用简化变量,即命令如下:
hadoop fs –ls Input (前提,你已上传Input目录文件)
或者
hadoop fs –ls /user/username
但无论如何,不建议使用如下命令
hadoop fs –ls /user
原因是前面提到过了,百度开放云此处还没有开发完善,这个user里面有大量的私有用户名字,你虽然看不到文件,也没有权限打开路径,但是仅打印名字路径这一项,就可以使你的电脑卡住,因为账户名字实在是太多了(由第三点,就知道我只是截图截了极少一部分打印出来的账户名)。
六、上传文件至工作目录后,再从工作目录使用hadoop shell命令将文件复制至分布式系统目录下。
七、对于文件名过长的问题,指令写起来比较麻烦,可以使用当前工作目录下所在文件名使用星号*代替后缀,这个后缀不仅仅是文件类型后缀名,还可以是自动补齐文件名,系统会自动扫描。Web shell不支持Tab补齐,所以星号补齐也是可以考虑的办法。
为能够在Hadoop环境下进行实验,必须先在系统工作目录下配置好文件,其几者之间的关系,我可以认为如下图所示。通过web shell内的upload指令,将文件上传至系统工作目录。
如果需要对文件目录进行管理,可以使用OS shell内的mv或rm或mkdir等指令管理。
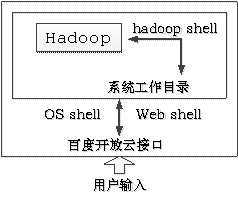
标用Hadoop shell内的fs-put或fs-ls指令,将工作目录内的文件复制到分布式系统内。本实验中,主要是两个txt文本,切记仅仅是两个txt文本,如果带入其他可读文件(例如jar包),否则词频统计也会强行读入,届时结果可能会是乱码。如下图所示,是一开始实验出现问题的图片,原因就是我将jar包也放入了txt文本平行目录,导致也强行读取了jar包的内容,统计jar包编写字符的频率,大多是乱码。
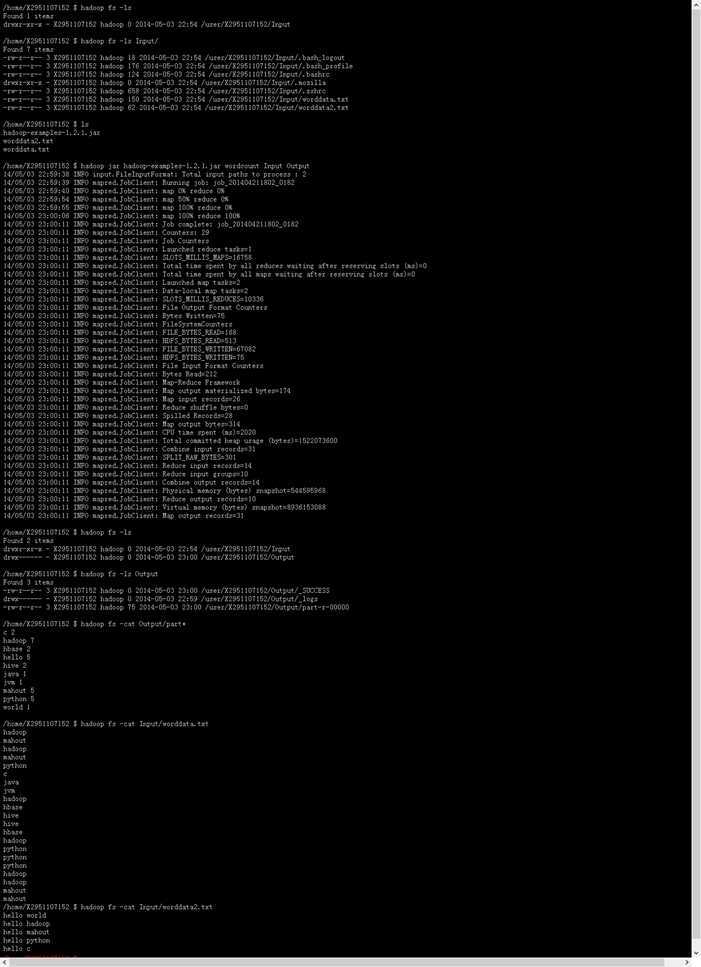
由于百度开放云平台配置好hadoop,则词频统计的过程步骤相当轻松。直接利用hadoop shell调用工作目录下的jar包例程,选择wordcount程序,并选择程序要输入的目录(在分布式系统内),设置程序输出所在目录(也在分布式系统内)。上述描述均有一条指令完成。即
hadoop jar hadoop-examples-1.2.1.jar wordcount Input Output
当程序执行完毕后,想要查看结果,使用如下指令:
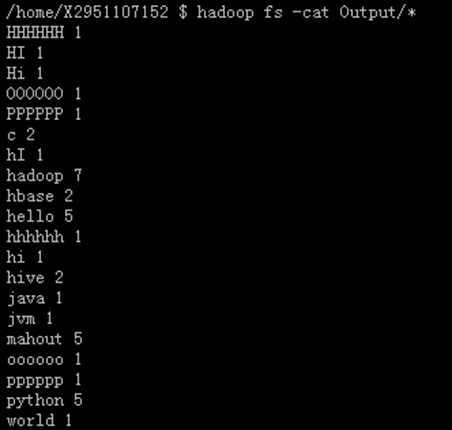
hadoop fs –cat Output/part-r-00000
或
Hadoop fs –cat Output/*
上述描述的指令过程可由下图所示。
下载文件时使用Web shell命令download即可。如在分布式系统内,可先由如下指令将分布式文件复制至工作目录下
hadoop fs –get Output/part-r-00000 /home/username
然后再利用百度开放云的web shell命令中的download指令,如下:
download /home/username/part-r-00000
测试文本由两个,内容分别如下。
|
hadoop mahout hadoop mahout python c java jvm hadoop hbase hive hive hbase hadoop python python python hadoop hadoop mahout mahout |
hello world hello hadoop hello mahout hello python hello c |
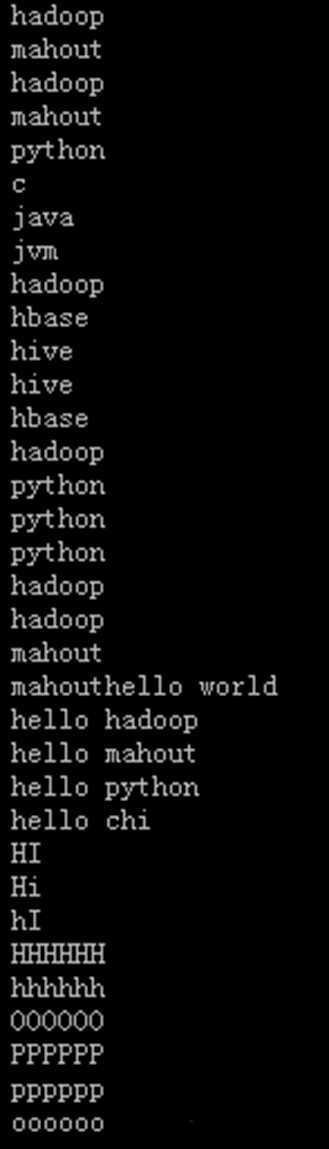
输出结果part-r-00000内容为:
c 2
hadoop 7
hbase 2
hello 5
hive 2
java 1
jvm 1
mahout 5
python 5
world 1
暂缺
测试文本由三文本,在上面的文本内容基础上,第三个文本是为了观察程序是否区分大小写(当然,通过阅读程序也可以,但此项测试为后面的改进铺垫。)
下面三图,分别是MapReduce执行流程,输入文本内容,输出统计结果。通过观察统计结果,发现原程序是区分大小写的。
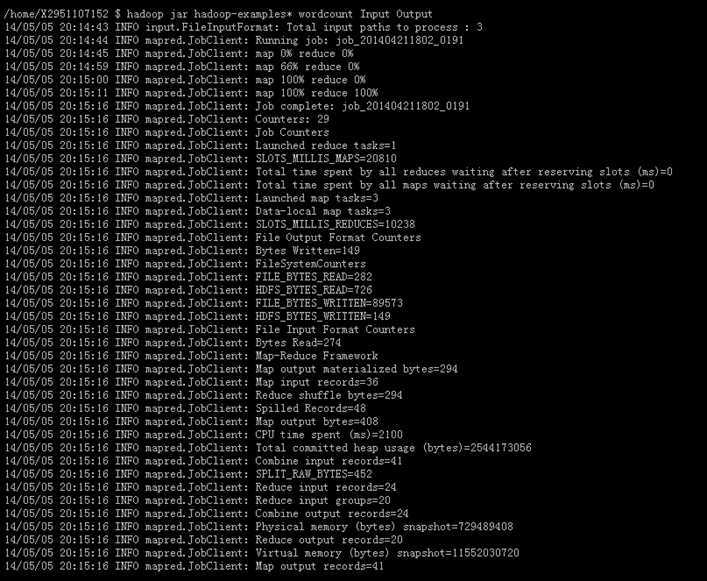
----------------------------------------------------------------------------------
---------------------------------------------------------------------------------------
工作方式有四个方面的改变:
一是、利用百度开放云去测试;
二是、不再使用hadoop-examples自带的集成jar包,而是从最基本的java程序开始操作进行打包;
三是、使用MyEclipse与MapReduce的连接框架进行测试;
四是、简单涉猎中文分词统计词频实验。
编写java程序,并实施改进。由于水平有限,不能做出太大进步,因而决定,简单改进两处。
一是、向程序内的空格或Tab划分,增加"标点符号"也成为定界符。
二是、统计单词忽略大小写,均转换成为小写状态。
注意之前利用集成jar包测试时,原程序是区分大小写的。
总环境不限,既可以在百度开放云上,也可以在单机上。(MyEclipse与MapReduce是在单机上的。)
方案一是、由基本java程序开始,使用文本进行修改编写,进行基本的打包操作,放在Hadoop上测试。(参看改进实验方案一步骤)
方案二是、由基本java程序开始,使用MyEclipse与MapReduce联合构架,进行软件与Hadoop的连接测试。(参看第四部分)
方案三是、简单涉猎中文分词背景下的词频统计改进实验。(参看第五部分)
程序中加粗加卸部分为修改代码的部分,也即两个注释行所在位置。
|
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString(),"\t\n\t\f ,.:;?![]()‘"); //多定界符,请注意逗号前有一个空格! while (itr.hasMoreTokens()) { word.set(itr.nextToken().toLowerCase());//不区分大小写 context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
我反复强调制作的新程序不同于以往的特点在于两处:
a)英文单词可以使用空格,逗号,感叹号,问号,括号等分隔,进行统计;
b)统计时,不区分大小写,只要是同一个字符内容,都会合并。
下面展示打成jar包的流程:
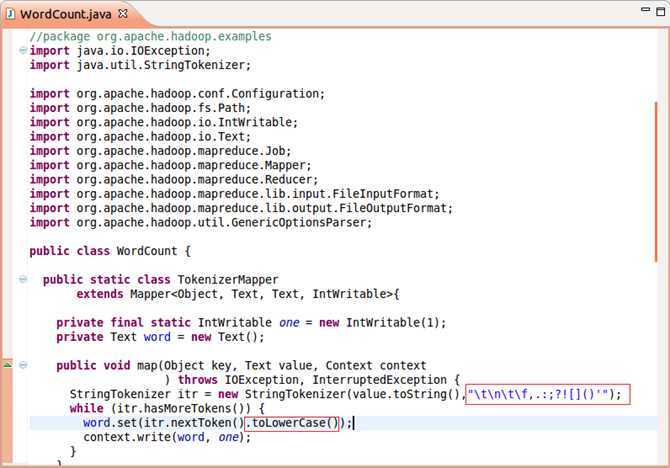
如下图所示,是展示MyEclipse修改新程序的界面,红色框内标注出来修改的部分。请注意本截图较老,也没有及时更新修正错误,本图里面没有加入空格定界,即红框里的上面那个没有加入空格。如果你需要,尤其是分割新闻时,切记在代码中加入空格!不要被本图误导!具体原因见上面的改进实验方案一步骤的代码注释。
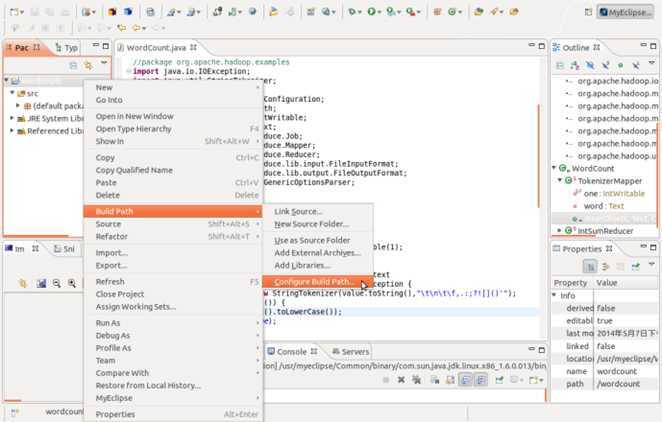
接下来进行编译,会发现很多错误,那么我们需要链接一些库,链接库的操作,如下图所示,先选中你的项目,以我为例,我选中左边资源视图中的WordCount文件夹,然后右键选择新建链接库路径。
然后弹出链接库的文件选择框,选择add external jar,如下图所示:
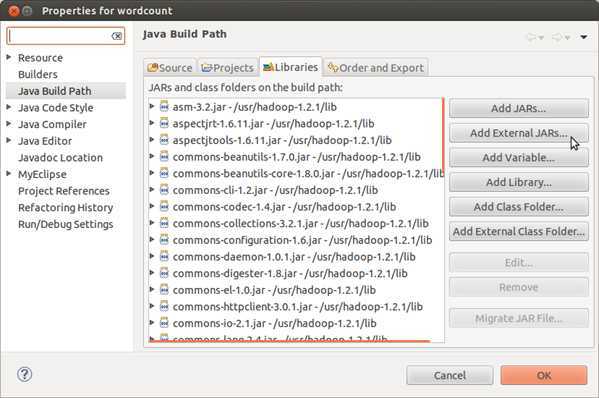
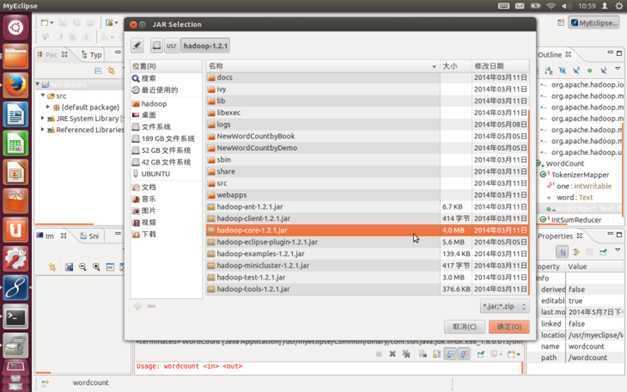
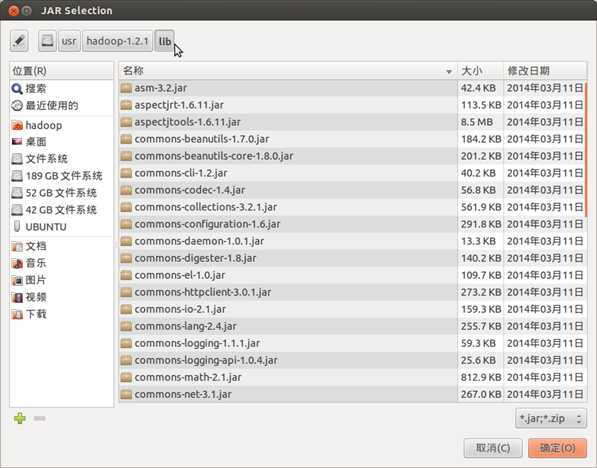
点击开后,我们要选择需要导入的包,我们打开Hadoop所在的目录,选择hadoop目录内的hadoop/usr/lib里面所有jar包,以及hadoop/hadoop-core-1.2.jar,如下图所示:
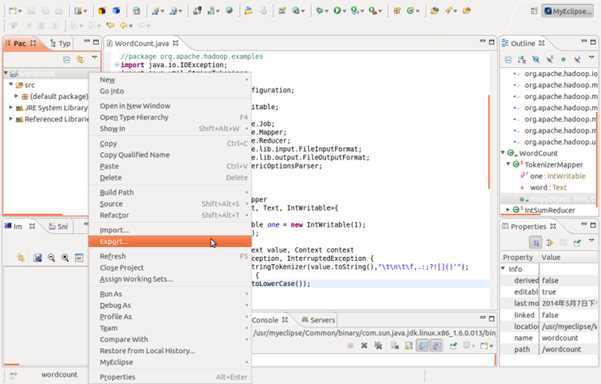
那么有上述过程,编译提示的错误基本都会消除。然后通过编译,生成jar包。生成jar包的流程如下图所示,同样选择自己的项目,右键选择Export:
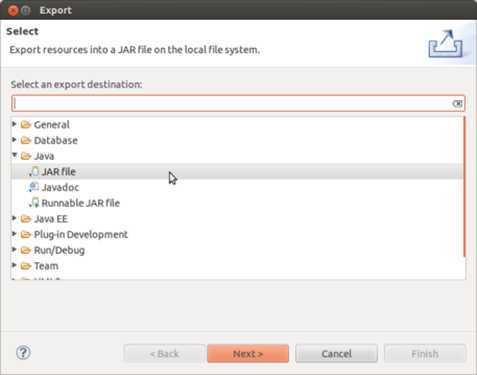
然后弹出后续界面如下,选择导出的式jar file,然后基本上点击next下一步就可以了,请在JAR File Specification对话框内把jar包的生成路径写好,点击next。
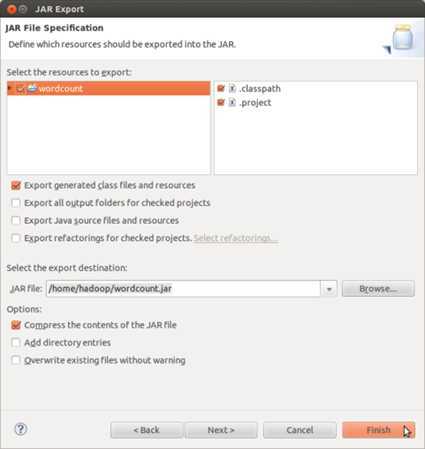
然后是在JAR Packaging Options界面,没有可填写的,点击Next。
最后是在JAR Manifest Specification界面,一定切记选中主类,否则jar包表面正常打包,但无法调用。选择Select the class下面的Browse,弹出主类的选择项,选择WordCount即可。最终点击Finish完成所有操作。
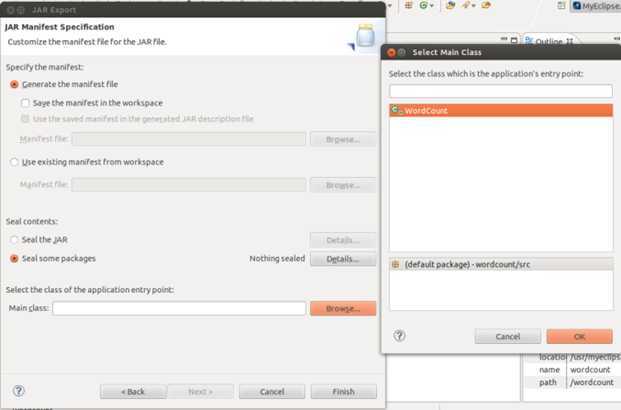
值得一提的是,打成jar包,如果是单独jar包,需要去掉package这句,且在hadoop内调用时,不再是如下格式:
$hadoop
jar wordcount.jar wordcount Input Output
而是这样的格式:
$hadoop
jar wordcount.jar Input Output
因为hadoop-examples-1.2.1.jar内含有众多class,其调用格式为
hadoop jar hadoop-examples-1.2.1.jar [demo jar name] [Input] [Output]
而我们打好的jar已经是个体户了,暂时脱离demo集体,故其调用格式为:
hadoop jar [single jar name] [Input] [Output]
以如下测试文本:
hi
HI
Hi
hI
HHHHHH
hhhhhh
OOOOOO
PPPPPP
pppppp
oooooo
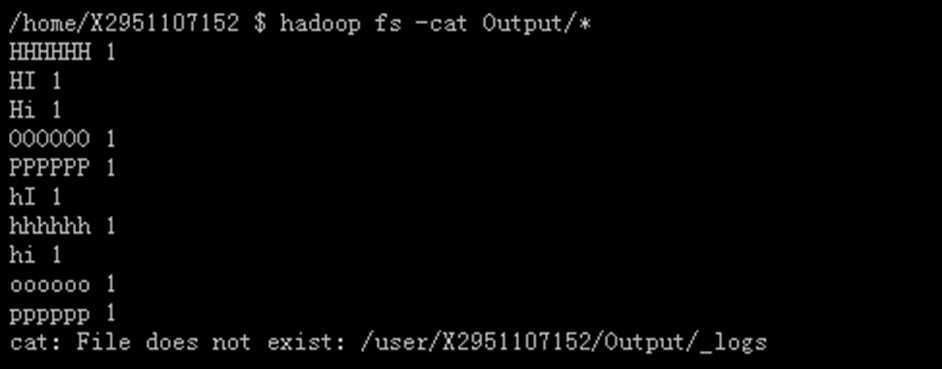
使用旧程序(即hadoop-examples1.2.1.jar),统计词频是区分大小写的,其结果如下:
HHHHHH 1
HI 1
Hi 1
OOOOOO 1
PPPPPP 1
hI 1
hhhhhh 1
hi 1
oooooo 1
pppppp 1
其图片显示的结果如下图所示:
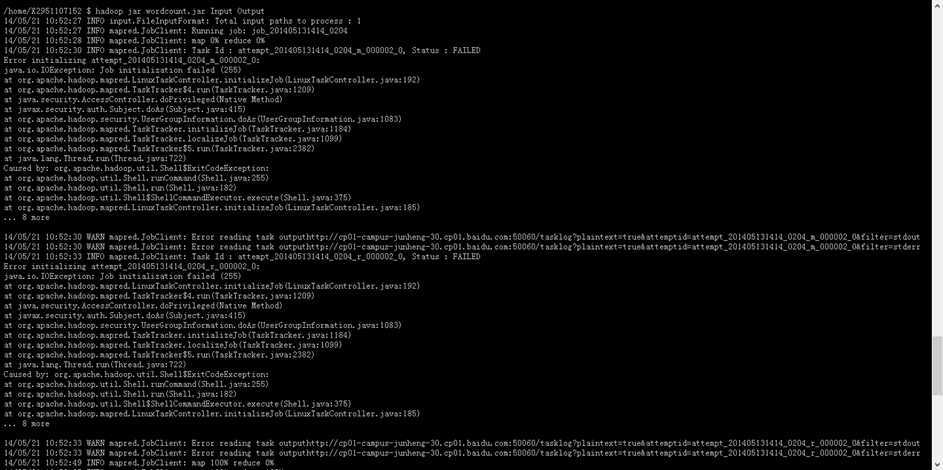
我们在修改程序得到新程序后,使用百度开放云hadoop平台,使用新的jar包。操作指令过程可下图所示(图片另存放大可看清,亲测):
其结果文字内容如下所示:
hhhhhh 2
hi 4
oooooo 2
pppppp 2
至于指令内容获取结果,如下图所示:
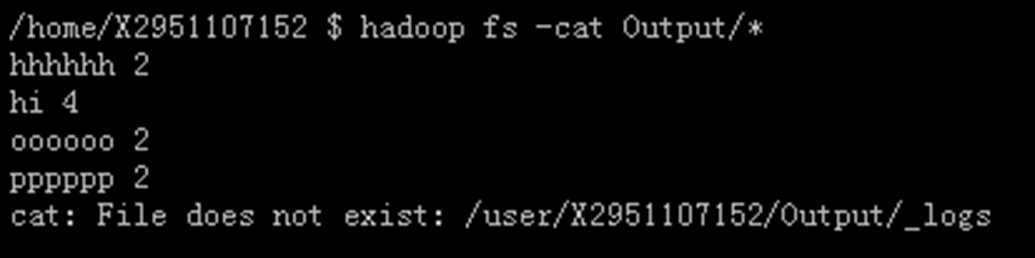
由上面结果,我们可以看到,新程序确实起了作用。那么我们进入新程序的最后一个综合阶段。
结合质的简单变化和量的简单变化,选择China Daily新闻上的昨日新闻作为测试文本,作为质的变化指单词分隔符有新内容加入,且不区分大小写。量的变化指增加样本。所谓简单变化意思就是,程序修改不大,改动规模较小甚至极小,样本量受限于个人时间和精力,而且还要处理相关格式(hadoop还是UTF8比较好),所以在量上,样本稍多一些,但没有达到一定数量级。
以一些新闻样本的内容简单示意,注意只是部分内容,完整内容可参看附件。
|
Cast member Gong Li poses on the red carpet as she arrives for the screening of the film "Coming Home" (Gui lai) out of competition at the 67th Cannes Film Festival in Cannes May 20,2014.Director Zhang Yimou (R) and cast member Zhang Huiwen pose on the red carpet as they arrive for the screening of the film "Coming Home" (Gui lai) out of competition at the 67th Cannes Film Festival in Cannes May 20, 2014.Cast member Gong Li poses on the red carpet as she arrives for the screening of the film "Coming Home" (Gui lai) out of competition at the 67th Cannes Film Festival in Cannes May 20, 2014. Picture taken with a long exposure and lens zoom effect.Cast members Gong Li (L) and Chen Daoming (R) pose on the red carpet as they arrive for the screening of the film "Coming Home" (Gui lai) out of competition at the 67th Cannes Film Festival in Cannes May 20, 2014. Picture taken with a long exposure and lens zoom effect. |
我们将制作好的新程序包上传至百度开放云。这里有些注意事项,需要注意。
Input总是放不进超过两个以上的文件,事实上是我们没有了解百度开放云接口。解决方法是在外部建立文件夹,把你想要分析的文本全部放入。然后使用Hadoop fs –put指令是将外部文件夹的目录扔进去,百度云自动会搜索目录里面的文本,然后Input里面就会出现多个文本了,其指令的流程,可参看下图。
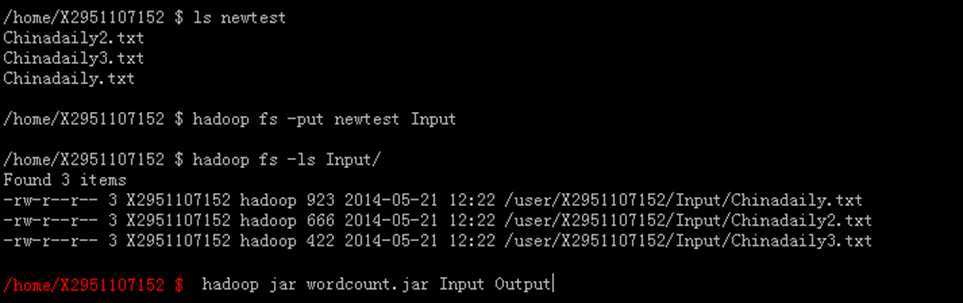
我在外部新建了newtest文件夹,把新闻样本(三个)放进目录里,然后使用分布式指令,整体扔进Input,然后Input里面就会有多个文本,所以不建议一个一个put进去。然后我们执行jar包,可以得到结果了。hadoop运行的状态可如下图所示:
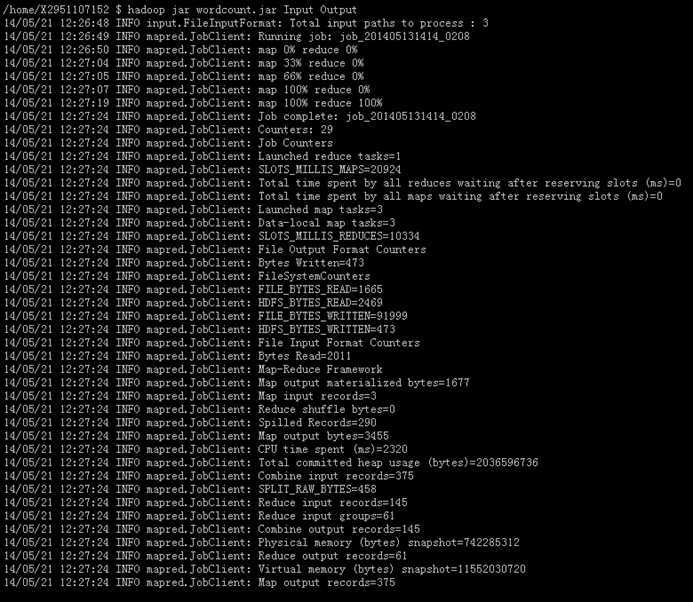
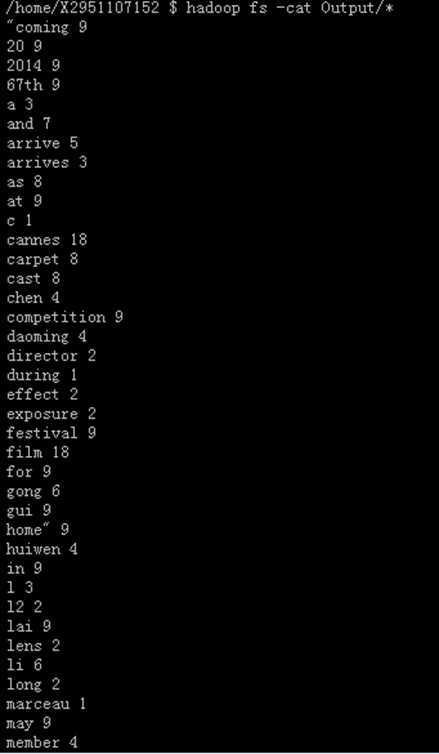
我们将结果获取,可观察内容,文字内容如下所示:
|
"coming 9 20 9 2014 9 67th 9 a 3 and 7 arrive 5 arrives 3 as 8 at 9 c 1 cannes 18 carpet 8 cast 8 chen 4 competition 9 daoming 4 director 2 during 1 effect 2 exposure 2 festival 9 film 18 for 9 gong 6 gui 9 home" 9 huiwen 4 in 9 l 3 l2 2 |
lai 9 lens 2 li 6 long 2 marceau 1 may 9 member 4 members 4 of 17 on 8 out 9 photocall 1 picture 2 pose 5 poses 4 r 5 r2 2 red 8 screening 8 she 3 sophie 1 taken 2 the 34 they 5 with 2 yimou 3 zhang 7 zoom 2 actress 1 director 1 |
图片示意的结果,由于单词行数无法截图至一张图内,故截取部分示意。
如果出现下面问题,如下图所示说明程序中的分隔符没有写入空格,可参看前面所述的代码注释,自行调整。

方案二的主要思路是,使用中文文本,然后使用中文分词程序对其进行词频统计,其中我采用传统的java程序与MapReduce构架。
方案三的主要思路是,使用英文文本,尝试使用Python程序和StreamingAPI。我在Python程序上尝试英文词频统计,不使用中文的原因,一是因为python处理中文且运用至hadoop,目前本人水平欠缺,二是中文显示问题,百度云不能显示,单机对于python又极易出错,故选择英文文本。
Hadoop的改进实验(中文分词词频统计及英文词频统计)(1/4),布布扣,bubuko.com
Hadoop的改进实验(中文分词词频统计及英文词频统计)(1/4)
标签:c style class blog java tar
原文地址:http://www.cnblogs.com/bitpeach/p/3756148.html