标签:
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 7365 | Accepted: 2130 |
Description
RJ Freight, a Japanese railroad company for freight operations has recently constructed exchange lines at Hazawa, Yokohama. The layout of the lines is shown in Figure 1.
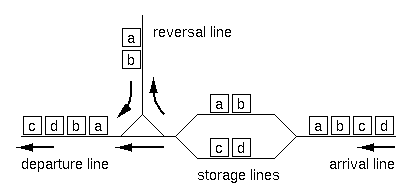
Figure 1: Layout of the exchange lines
A freight train consists of 2 to 72 freight cars. There are 26 types of freight cars, which are denoted by 26 lowercase letters from "a" to "z". The cars of the same type are indistinguishable from each other, and each car‘s direction doesn‘t matter either. Thus, a string of lowercase letters of length 2 to 72 is sufficient to completely express the configuration of a train.
Upon arrival at the exchange lines, a train is divided into two sub-trains at an arbitrary position (prior to entering the storage lines). Each of the sub-trains may have its direction reversed (using the reversal line). Finally, the two sub-trains are connected in either order to form the final configuration. Note that the reversal operation is optional for each of the sub-trains.
For example, if the arrival configuration is "abcd", the train is split into two sub-trains of either 3:1, 2:2 or 1:3 cars. For each of the splitting, possible final configurations are as follows ("+" indicates final concatenation position):
[3:1]
abc+d cba+d d+abc d+cba
[2:2]
ab+cd ab+dc ba+cd ba+dc cd+ab cd+ba dc+ab dc+ba
[1:3]
a+bcd a+dcb bcd+a dcb+a
Excluding duplicates, 12 distinct configurations are possible.
Given an arrival configuration, answer the number of distinct configurations which can be constructed using the exchange lines described above.
Input
The entire input looks like the following.
the number of datasets = m
1st dataset
2nd dataset
...
m-th dataset
Each dataset represents an arriving train, and is a string of 2 to 72 lowercase letters in an input line.
Output
For each dataset, output the number of possible train configurations in a line. No other characters should appear in the output.
Sample Input
4 aa abba abcd abcde
Sample Output
1 6 12 18
Source
题意:将一个字符串可以任意分成两节,任意颠倒顺序,问最终会得到几个字符串。
hash储存下字符串,字符串长度为72,每一次分开后,最多有8种情况,所以最多不会超过72*8种。
遍历分开的节点的位置,hash查找
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
#include <string>
using namespace std ;
struct node{
char s[100] ;
int next ;
}p[100000];
int head[400000] , cnt ;
char str[100] , s[100] , s1[100] , s2[100] ;
int num ;
void hash1(int k)
{
int i , j ;
for(i = head[k] ; i != -1 ; i = p[i].next)
{
if( strcmp(p[i].s,s) == 0 )
break ;
}
if( i == -1 )
{
num++ ;
strcpy(p[cnt].s,s) ;
p[cnt].next = head[k] ;
head[k] = cnt++;
}
return ;
}
void solve(char *s1,char *s2)
{
int j , k , l1 = strlen(s1) , l2 = strlen(s2) ;
for(j = 0 , k = 0 ; j < l1+l2 ; j++)
{
if( j < l1 )
s[j] = s1[j] ;
else
s[j] = s2[j-l1] ;
k += s[j]*j ;
}
s[l1+l2] = '\0' ;
hash1(k) ;
for(j = 0 , k = 0 ; j < l1+l2 ; j++)
{
if( j < l1 )
s[j] = s1[j] ;
else
s[j] = s2[l2-1-(j-l1)] ;
k += s[j]*j ;
}
s[l1+l2] = '\0' ;
hash1(k) ;
for(j = 0 , k = 0 ; j < l1+l2 ; j++)
{
if( j < l1 )
s[j] = s1[l1-1-j] ;
else
s[j] = s2[j-l1] ;
k += s[j]*j ;
}
s[l1+l2] = '\0' ;
hash1(k) ;
for(j = 0 , k = 0 ; j < l1+l2 ; j++)
{
if( j < l1 )
s[j] = s1[l1-1-j] ;
else
s[j] = s2[l2-1-(j-l1)] ;
k += s[j]*j ;
}
s[l1+l2] = '\0' ;
hash1(k) ;
return ;
}
int main()
{
int m , i , j , l ;
scanf("%d", &m) ;
while( m-- )
{
memset(head,-1,sizeof(head)) ;
cnt = 0 ;
num = 0 ;
scanf("%s", str) ;
l = strlen(str) ;
for(i = 0 ; i < l-1 ; i++)
{
for(j = 0 ; j <= i ; j++)
s1[j] = str[j] ;
s1[j] = '\0' ;
for(j = i+1 ; j < l ; j++)
s2[j-i-1] = str[j] ;
s2[j-i-1] = '\0' ;
solve(s1,s2) ;
solve(s2,s1) ;
}
printf("%d\n", num) ;
}
return 0 ;
}
poj3007--Organize Your Train part II(hash)
标签:
原文地址:http://blog.csdn.net/winddreams/article/details/43268741