标签:des c style class blog code
本文参考MDU系列某产品OMCI模块现有代码,提取若干实例以说明目前的代码质量。
本文旨在就事论事,而非否定前人(没有前人的努力也难有后人的进步)。希望以史为鉴,不破不立,最终产出高质量的代码。
不考虑业务实现,现有的OMCI模块代码质量不甚理想。无论是理解上手、修改扩展和测试排障,可以用举步维艰形容。尤其是二层通道计算相关代码,堪比令史前动物无法自拔的“焦油坑”。
本节将不考虑流程设计,仅就函数粒度列举目前存在的较为突出的代码质量问题。
通过Source Monitor度量代码复杂度,如下图所示:
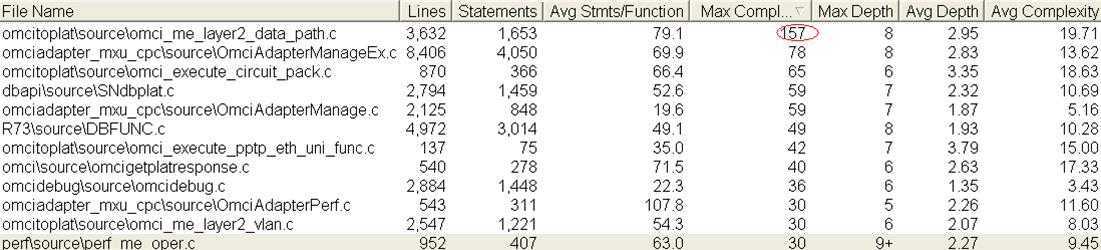
可见,相比业界推荐的5以下,OMCI模块代码复杂度非常之高。
复杂度最高(157)的函数位于Omci_me_layer2_data_path.c二层通道计算文件,选取其中一段函数调用链分析:
→OMCI_Me_Layer2_Calculate_TCI_List(复杂度:67,行数:282)
→OMCI_Me_Layer2_Calculate_TCI_According_VlanRuleList(复杂度:28,行数:182)
该函数对扩展Vlan存在递归调用。
→OMCI_Me_Layer2_Compare_TCI(复杂度:6,行数:38)
该函数位于三级while循环各级内,如下(原循环77行,为突出重点已删除次要细节):

更具震撼性的是,OMCI_Me_Layer2_Compare_TCI调用下面三个巨型函数:
→→OMCI_Me_Layer2_Compare_EthType(复杂度:26,行数:90)
→→OMCI_Me_Layer2_Compare_Vid(复杂度:149,行数:450)
→→OMCI_Me_Layer2_Compare_Pri(复杂度:157,行数:468)
以上仅示出调用链上的关键函数,且调用链自身仅隶属于通道计算的一环。评估其全局复杂度,这样的代码实际上是不可维护的。
此外,当Compare处理耗时超过直接Set时,将严重违背设计本意。
事实上,诸如此类的巨型函数在模块内随处可见。单论函数行数,目前发现的最巨型的函数参见Sub_SNGetMeValueFromAdapter(复杂度:59,行数:538行)。
代码中存在较多设计欠佳之处,在此举例若干。

1 /********************************************************************** 2 * 函数名称: Omci_List_Pop_Front 3 * 功能描述: 从链表头部弹出一个节点 4 * 输入参数: OMCI_LIST *pList 链表指针 5 * 输出参数: void *pOutData 链表节点的数据 6 * 返 回 值: 7 ***********************************************************************/ 8 INT32U Omci_List_Pop_Front(OMCI_LIST *pList, void *pNodeData) 9 { 10 OMCI_LIST_NODE *pHeadNode = NULL; 11 12 if (pList == NULL || pNodeData == NULL) 13 { 14 return OMCI_FUNC_RETURN_FAILURE; 15 } 16 17 pHeadNode = pList->pHead; 18 if (NULL != pHeadNode) 19 { 20 if (NULL != pHeadNode->pNodeData) 21 { 22 memcpy(pNodeData, pHeadNode->pNodeData, pList->dwNodeDataSize); 23 } 24 else 25 { 26 return OMCI_FUNC_RETURN_FAILURE; 27 } 28 } 29 else 30 { 31 return OMCI_FUNC_RETURN_FAILURE; 32 } 33 34 Omci_List_Remove(pList, pHeadNode); 35 36 return OMCI_FUNC_RETURN_SUCCESS; 37 }
Omci_List_Pop_Front函数和Omci_List_Push_Back函数成对出现,其代码风格在OMCI模块内属于比较优秀的。此处仅分析其设计缺陷:
1)从函数名称看其功能应为弹出栈元素,从“功能描述”看应为队列行为,从函数体看既不是栈也不是队列;
2)函数兼具取值和删除功能,但通常取值时不应删除,删除时无需取值。
上述问题直接导致Omci_List_Pop_Front函数接近于废弃,无处可用。
其实我们需要的不是Omci_List_Pop_Front函数,而是Locate或称Query函数。基于后者,删除链表节点时先Locate后Remove;而不是目前由调用者遍历链表后调用Omci_List_Remove,从而将链表细节暴露在外。
后来在XGPON代码里新增了Omci_List_Query函数,定义如下:
1 OMCI_LIST_NODE* Omci_List_Query(OMCI_LIST *pList, ...) 2 { 3 OMCI_LIST_NODE_KEY aKeyGroup[MAX_LIST_NODE_KEYS_NUM]; 4 OMCI_LIST_NODE *pNode=NULL; 5 INT8U *pData=NULL, *pKeyValue=NULL; 6 INT8U ucKeyNum=0, i; 7 INT32U iKeyOffset=0, iKeyLen=0; 8 VA_LIST tArgList; 9 10 if(NULL==pList) 11 return NULL; 12 memset((INT8U*)aKeyGroup, 0, sizeof(OMCI_LIST_NODE_KEY)*MAX_LIST_NODE_KEYS_NUM); 13 VA_START(tArgList, pList); 14 while(TRUE) 15 { 16 pKeyValue=VA_ARG(tArgList, INT8U*); 17 if(LIST_END==pKeyValue) 18 break; 19 iKeyOffset=VA_ARG(tArgList, INT32U); 20 iKeyLen=VA_ARG(tArgList, INT32U); 21 if(0==iKeyLen) 22 { 23 VA_END(tArgList); 24 return NULL; 25 } 26 if(ucKeyNum>=MAX_LIST_NODE_KEYS_NUM) 27 { 28 VA_END(tArgList); 29 return NULL; 30 } 31 aKeyGroup[ucKeyNum].pKeyValue=pKeyValue; 32 aKeyGroup[ucKeyNum].iKeyOffset=iKeyOffset; 33 aKeyGroup[ucKeyNum++].iKeyLen=iKeyLen; 34 } 35 VA_END(tArgList); 36 37 pNode=Omci_List_First(pList); 38 while(NULL!=pNode) 39 { 40 pData=(INT8U*)pNode->pNodeData; 41 for(i=0; i<ucKeyNum; i++) 42 { 43 if(0!=memcmp(&pData[aKeyGroup[i].iKeyOffset], aKeyGroup[i].pKeyValue, aKeyGroup[i].iKeyLen)) 44 break; 45 } 46 if(i>=ucKeyNum) 47 { 48 break; 49 } 50 pNode=pNode->pNext; 51 } 52 return pNode; 53 }
使用示例如下:
1 OMCI_LIST_NODE* pGemPortNode = Omci_List_Query(g_pIgmpUpAction, &tIGMPVlanAction, 0, sizeof(OMCI_ADAPTER_MulticastPort_vlan_EX), LIST_END); 2 if(NULL != pGemPortNode) 3 { 4 Omci_List_Remove(g_pIgmpUpAction, pGemPortNode); 5 }
可见,该函数有效地隐藏了链表细节,但变参函数易用性和可读性比较差(注意原函数没有注释)。对比下面的查找函数:
1 /********************************************************************** 2 * 函数名称: OmciLocateListNode 3 * 功能描述: 查找链表首个与pData满足函数fCompareNode判定关系的结点 4 * 输入参数: T_OMCI_LIST* pList :链表指针 5 * VOID* pData :待比较数据指针 6 * CompareNodeFunc fCompareNode :比较回调函数指针 7 * 输出参数: NA 8 * 返 回 值: T_OMCI_LIST_NODE* 链表结点指针(未找到时返回NULL) 9 ***********************************************************************/ 10 T_OMCI_LIST_NODE* OmciLocateListNode(T_OMCI_LIST *pList, VOID *pData, CompareNodeFunc fCompareNode) 11 { 12 CHECK_TRIPLE_POINTER(pList, pData, fCompareNode, NULL); 13 CHECK_SINGLE_POINTER(pList->pHead, NULL); 14 CHECK_SINGLE_POINTER(pList->pHead->pNext, NULL); 15 16 T_OMCI_LIST_NODE *pListNode = pList->pHead->pNext; 17 while(pListNode != pList->pHead) 18 { 19 if(0 == fCompareNode(pListNode->pNodeData, pData, pList->dwNodeDataSize)) 20 return pListNode; 21 22 pListNode = pListNode->pNext; 23 } 24 25 return NULL; 26 }
两个函数由不同作者分别实现,互不知情。但对比之下,易用性和可读性可窥一斑。
举例如下:
1 INT8U ONUMACDRV_get_omci(ONUMAC_OMCI* vpOut , INT8U* vpIn) 2 { 3 //static INT16U wTci; 4 INT8U * buffer ; 5 INT32U index, crc_result = 0, crc_trans = 0; 6 char omcilog[300] = {0}; 7 8 buffer = ( INT8U * ) OMCI_MALLOC ( OMCI_MESSAGE_LENGTH ) ; 9 if ( NULL == buffer ) 10 { 11 OmciPrint_error("[%s]OMCI OMCI_MALLOC buffer is NULL!\n\r", FUNCTION_NAME); 12 return OMCI_FUNC_RETURN_FAILURE; 13 } 14 memmove(buffer,vpIn,OMCI_MESSAGE_LENGTH); 15 16 /*升级过程中,若出现crc出错时,是需要应答OLT的,故需要继续取值*/ 17 vpOut->omci_header.wtranscorrelationid = (buffer [ 0 ]<<8 ) | (buffer [ 1 ]); 18 vpOut->omci_header.ucar = (buffer [ 2 ]& 0x40)>>6; 19 vpOut->omci_header.ucak = (buffer [ 2 ]& 0x20)>>5; 20 vpOut->omci_header.ucmsgtype = buffer [ 2 ]& 0x1f; 21 vpOut->omci_header.ucdevid = buffer [ 3 ]; 22 vpOut->omci_header.wmeclass = (buffer [ 4 ]<< 8) | (buffer [ 5 ]); 23 vpOut->omci_header.wmeid = (buffer [ 6 ]<< 8) | (buffer [ 7 ]); 24 25 /*crc 校验*/ 26 crc_result = OMCI_crc32(buffer,OMCI_CRC_SIZE); 27 crc_trans =( buffer [ 44 ] << 24) |(buffer [ 45] << 16)|(buffer [ 46] << 8)|(buffer [ 47]); 28 if(crc_result != crc_trans) 29 { 30 OmciPrint_error("[%s]ZTE----OMCI CRC error!crc_trans = %ud,crc_result = %ud \n\r", FUNCTION_NAME, crc_trans,crc_result); 31 OMCI_FREE ( buffer ) ; 32 return OMCI_FUNC_RETURN_PARAMETER_ERROR; 33 } 34 35 for(index = 0;index < 32; index++) 36 { 37 vpOut->auccontent[index] = buffer [index+8]; 38 } 39 40 if((0!=(dwPrintSwitch & 0x00000001))||(0!=(dwPrintSwitch & OMCI_PRINT_SWITCH_OMCIFRAME))) 41 { 42 memset(&omcilog[0],0,300); 43 if(vpOut->omci_header.ucmsgtype == OMCIMETYPE_MIB_UPLOAD_NEXT) 44 sprintf(&omcilog[strlen(omcilog)],"Recv MIB upload next Msg, TCI=%d, SequenceNum=%d", 45 vpOut->omci_header.wtranscorrelationid, (vpOut->auccontent[0]<<8) | vpOut->auccontent[1]); 46 else 47 sprintf(&omcilog[strlen(omcilog)],"Recv omci Msg, MsgType=%d, MeClass=%d, MeId=0x%04x, TCI=%d", 48 vpOut->omci_header.ucmsgtype,vpOut->omci_header.wmeclass,vpOut->omci_header.wmeid, vpOut->omci_header.wtranscorrelationid); 49 for(index = 0;index < OMCI_MESSAGE_LENGTH; index++) 50 { 51 if( 0 == (index%16)) 52 sprintf(&omcilog[strlen(omcilog)],"\n\r"); 53 if( 8 == index) 54 sprintf(&omcilog[strlen(omcilog)],"["); 55 if( 40 == index) 56 sprintf(&omcilog[strlen(omcilog)],"]"); 57 if( 24 == index) 58 sprintf(&omcilog[strlen(omcilog)]," "); 59 sprintf(&omcilog[strlen(omcilog)],"%02x ",buffer[index]); 60 } 61 sprintf(&omcilog[strlen(omcilog)],"\n\r"); 62 if(0!=(dwPrintSwitch & 0x00000001)) 63 { 64 omci_printTime(); 65 /* using this function just for it is compatible with old print switchs */ 66 omcidebug_print("%s",omcilog); 67 } 68 else 69 { 70 OmciPrint_omciframe("%s", omcilog); 71 } 72 } 73 74 OMCI_FREE ( buffer ) ; 75 return OMCI_FUNC_RETURN_SUCCESS; 76 }
ONUMACDRV_get_omci函数对接收到的OMCI帧进行解析和受控打印。此处不考虑单一职责的设计问题,仅分析其编码缺陷:
1)OMCI帧定长为32字节,没有必要申请动态内存;
2)omcilog[strlen(omcilog)]导致大量毫无必要的字符串长度计算。
上述两个问题极大地拖慢该函数执行速度,并直接导致某产品在打开OMCI帧打印时无法注册上线。ONUMACDRV_set_omci函数存在同样问题。
关于strlen的冗余计算,再举类似一例:
1 /*************************************************************** 2 * Function: Omci_IPv4_Int_to_String 3 * Description: 将IP地址从INT32U型转换成点分十进制的字符串 4 * Input: 5 * Output: 6 * Returns: 点分十进制的字符串表示的IP地址 7 ***************************************************************/ 8 INT8U *Omci_IPv4_Int_to_String(INT32U dwInt) 9 { 10 INT8U ucByte,ucPos; 11 static INT8U azStr[16]; 12 memset(azStr,0,16); 13 14 ucPos = strlen(azStr); 15 sprintf(&azStr[ucPos],"%d.",(INT8U)((dwInt>>24)&0x000000FF)); 16 17 ucPos = strlen(azStr); 18 sprintf(&azStr[ucPos],"%d.",(INT8U)((dwInt>>16)&0x000000FF)); 19 20 ucPos = strlen(azStr); 21 sprintf(&azStr[ucPos],"%d.",(INT8U)((dwInt>>8)&0x000000FF)); 22 23 ucPos = strlen(azStr); 24 sprintf(&azStr[ucPos],"%d",(INT8U)(dwInt&0x000000FF)); 25 26 return azStr; 27 }
对比其另一实现:
1 /* IPv4 Format: 0x0a285b09 ----> "10.40.91.9" or "0a.28.5b.09" */ 2 /* **************************Usage**************************** */ 3 /* INT32S dwIp = 0x0a285b09; CHAR aIpAddr[32] = {0}; */ 4 /* HexIpv4ToStrIp(dwIp, aIpAddr, sizeof(aIpAddr)); */ 5 #define STR_IPV4_MAX_SIZE (INT8U)sizeof("255.255.255.255") 6 INT32S HexIpv4ToStrIp(INT32S dwIp, CHAR *pStrIp, INT16U wSize) 7 { 8 if((NULL == pStrIp) || (wSize < STR_IPV4_MAX_SIZE)) 9 { 10 return -1; 11 } 12 13 sprintf(pStrIp, "%d.%d.%d.%d", (dwIp & 0xFF000000) >> 24, (dwIp & 0x00FF0000) >> 16, 14 (dwIp & 0x0000FF00) >> 8, dwIp & 0x000000FF); 15 /* Use "%02x.%02x.%02x.%02x" to form "0a.28.5b.09" */ 16 17 return 0; 18 }
重复造轮主要体现在对于相同或相似的功能,存在多种实现方式。
例如,通过Get-Next命令从表里逐条获取记录时,应执行相同的操作。代码里实现如下:

函数索引表里的函数实现(绿色)几乎各不相同,表明未做好足够的抽象。
另一处明显的重复出现在Sub_InsertPerformanceDb/Sub_InsertPerfInfoDb、Sub_DeletePerformanceDb/ Sub_DeletePerfInfoDb等,对于性能统计历史库和性能统计信息库定义了几乎相同的两套操作函数。同样,这里体现了抽象和提取能力的欠缺。
当然,上述重复性相比SNdbplat.c文件里各实体操作数据库的诸多函数,简直不值一提。
重复造轮还表现在OMCI函数状态返回值多处定义,违反了DRY(Don’t Repeat Yourself)原则。列举部分成功返回值如下:
1 OMCI_RET_OK 2 OMCI_RET_SUCCESS 3 R_OA_OK 4 AGENT_OPER_SUCCESS 5 OMCI_LIST_OPER_SUCCESS 6 OMCI_FUNC_RETURN_SUCCESS 7 …………
其实,将函数返回状态定义为统一的枚举变量不是更好吗?
引用混乱主要体现在头文件嵌套或交叉引用,违反了编译防火墙的原则。举例如下:
#include "omci_common_function.h"
→#include "omci_me_layer2_vlan.h"
→#include "omcifunc.h"
→
以上仅示出引用链上的关键头文件,这些多重引用的头文件不仅拖慢编译和链接速度,而且常常引发莫名其妙的错误。例如,曾发现头文件A中将OP_SET定义为宏,头文件B中将OP_SET定义为枚举值;而某源文件所必须包含的头文件辗转包含了头文件A和B,于是……
对于独立功能的代码(如链表操作等),头文件嵌套引用的做法还会削弱其独立性(使用者可能不得不拷贝不必要的文件)。
当然,头文件嵌套引用可以“简化”编码,如使用者可能只需在.c源文件里#include “XXXCommon.h”。但这无异于饮鸩止渴,除了纵容使用者的懒惰和不求甚解外别无他用!
因此我们约定:在头文件内尽量不引用其他头文件,而在源文件内引用所需的头文件。
此外,不加区分地将以太网、组播、语音、升级等相关宏和数据结构揉为一体,造就了1570行的巨型头文件:OmciComm.h!
注意该头文件的名称后缀(Comm),您似乎已意识到这是个被普遍包含的大家伙?
词不达意的变量名自不待说,先就函数命名的随意性举例若干:
1 void Sub_SNAddmulticastoperationsprofile(DB_ONUMAC_OMCI * in,SN_OPERATE_OUT * out) 2 { 3 WORD wNum, i = 0; 4 BYTE ucResult = 0; 5 BYTE * pRecord = DB_POINTER_NULL; 6 SN_MULCAST_OPERATIONS_PROFILE MulCastOp; 7 8 SN_MULCAST_OPERATIONS_PROFILE* pMulCastOpRecord = DB_POINTER_NULL; 9 10 MIB_OMCI_INDEX ont_data_index; 11 12 OmciPrint_debug("[LHP]Enter Sub_SNAddmulticastoperationsprofile MeClass %u MeId %u \n\r",in->index.wMeClass,in->index.wMeID); 13 g_wMulticastOperationsProfileDbHandle = _GetDBHandle(MULTICASTOPERATIONSPROFILE_DB); 14 15 //... ... 16 }
示例函数无论函数名还是局部变量名(毫无用处的全局DB句柄)长度都有点过分。然而更过分的示例来自下面的函数:
1 void Sub_SNQuerymulticastmulticastsubscriberconfiginfoForMultopProfilePT(INT16U Meid,SN_MULTOPPRO_MULTSUBS_POINT_QUERY_OUT * out,int MaxCount)
该函数名足足有67个字符!代码作者似乎“刻意”将multicast重复两遍,并在函数名末尾鬼使神差地使用了缩写:MultopProfile也许意指multicastoperationsprofile,但PT作何解呢?该函数在完成其既定功能的同时,还顺带考验读者的耐心和智商。
看过“大腹便便”型的函数名后,再来赏析“雾里看花”型的函数名:
1 INT32U OA_manage_configure_flows(void) 2 { 3 OA_manage_compare_flows(); 4 OA_manage_delete_flows(); 5 OA_manage_modify_flows(); 6 OA_manage_add_flows(); 7 8 return R_OA_OK; 9 }
据远古的传说讲,compare、delete、modify、add的操作对象似乎不是同一条(或所有条)flow……
对外提供的接口应有详细的文档说明和注释,且文档应随接口代码发布(最好置于同一目录)。接口函数应有详尽的函数签名,相同层次的函数应有相同的行为模式。此外,接口在封装内部实现的同时,应对外提供足够的透明性。无法探知内部状态的接口,无论易用性或安全性都将大打折扣。
此处就R73内存数据库接口加以说明:
1)从上研移植来的R73内存数据库设计文档已不可知。代码中也未提供数据库视图、关键结构/参数说明。接口函数签名信息量太少,直接将函数名或参数名拆分作为注释。
1 /*-------------------------------------------------------------- 2 function name: _CreateDB 3 para: dbName = db name 4 desc: create db 5 udate history: 6 XXX write code on 2002-03-04 7 --------------------------------------------------------------*/ 8 WORD _CreateDB( BYTE *dbName )
2)插入(_Insert)、删除(_Delete)、修改(_Update)接口从逻辑而言属于相同层次的函数,但其返回值模式并不相同,即:
首先,成功时返回非0正数违反编程习惯,默认约定0应表示成功。其次,三个接口返回模式不同,会增加使用者出错的可能性。
3)修改(_Update)接口内含大量校验处理,且失败时均返回-1。加之接口未提供错误打印(这本是良好的设计风格),导致使用者在调用失败时很难定位原因,而不得不手工添加调试打印:
1 if ((dbHandle<1)||(dbHandle>=mm_db_num)||(keyPtr==NULL)||(indexNo>INDEX_NUM-1)) 2 { 3 GeneralErrorHandler(); 4 return -1; 5 } 6 if(SafetyCheck(WRITE_OP,dbHandle)) return -1; 7 curRecNum=GetRecNum(dbHandle); 8 if (curRecNum==0) 9 { 10 FreeLock(WRITE_OP,dbHandle); 11 return -1; 12 }
其实接口设计者应定义一套错误原因码,校验失败时通过返回值向使用者抛出该错误码。如果接口位于同一源文件,则最简单最偷懒的错误码就是行数(__LINE__)!
另一处晦涩的接口来自1.2节的Omci_List_Query函数,该函数参数长度可变,但没有任何函数签名和注释。使用它的唯一“安全”方式就是搜索已有的调用代码,照猫画虎。
GCC编译器所提示的模块内警告多达1361处。若再进行更为严苛的pclint检查,则可以预想警告的暴增。
这是前人馈赠给后人的一大“遗产”,其中暗含不计其数的陷阱……
以上示出的主要为函数级问题,尚未涉及流程设计。事实上,糟糕的流程设计不仅降低了代码执行效率,而且增加了人工理解和维护的难度。迷失在巨型函数森林里的人们,除了焦虑和绝望别无一物。也许,会有少数人知晓某条林间蹊径,但无法驱散追随者心中的不安。
幸运的是,软件工程先哲们指出了一条路:重构。那么,亲们准备好了吗?
MDU某产品OMCI模块代码质量现状分析,布布扣,bubuko.com
标签:des c style class blog code
原文地址:http://www.cnblogs.com/clover-toeic/p/3755545.html
