标签:
缓存,提高访问速度的利器。工作中主要用到的是memcache和redis,它们是B/S软件,类似练习时装在机子上的Apache,它也会监听端口,可以在客户端(如在cmd上通过telnet操作Memcache)直接敲各自对应的命令来存取值,自学时可以通过这样的方式熟悉下原生命令,看看效果。它们常驻内存,得到数据后写入内存(安装软件后会占用一片内存区域),设定数据的过期时间,用到时直接从内存中读出来,因为是内存所以访问速度上有数量级的提高。lz曾今写了个非常简单的后台,完全不用缓存那种,那速度我自己看了都忍不住要咆哮:这么慢tm也能叫网页?!可那时我年幼无知,不会用缓存,当然现在也不见得好到哪儿去,但愿那时前端妹子没在心里暗自唾骂>3<......
memcache的使用较简单,至少从命令上来看是这样。在memcache中,存储的方式是key->value,键-值对应的方式存储,类似联接数组的元素形式,可存储的类型可以是数字、字符串、数组、对象等,项目中一般会将非字符串(数字可看成是数字字符串)类型的先进行json编码或者序列化再存入缓存,取出来时则解码或者反序列化。Memcache是php专门处理memcache缓存的类,封装的主要方法是get、set、delete、flush、connect、close,即一个缓存必备的获取、设置、删除、清空、连接、关闭等。(中括号为可传参数)
| add | key, var, [flag], [expire] | 添加一个键为key、值为var到服务端,可指定过期时间expire,0则永不过期,最长30天 |
| get | key, [flag] | 从服务端获取某一或某些元素 |
| delete | key, [timeout] | 在指定timeout时间内删除key对应元素,默认timeout为0立即删除 |
| flush | 无 | 清空,即删除所有元素 |
| connect | host, [port], [timeout] | 连接到memcache服务器host主机的port端口,它会在脚本执行完自动关闭,也可主动关闭 |
| close | 无 | 主动关闭memcache服务端连接,但不会关闭pconnect生成的连接 |
| set | key, var, [flag], [expire] | 存储键为key、值为var的元素到服务端,key存在则覆盖其值,不存在新add一个 |
| replace | key, var, [flag], [expire] | 查找键为key的元素,以值var替换,查不到会报错 |
| increment | key, [value] | 在键为key的元素上增加值value,value默认为1,可能改变原值 |
| decrement | key, [value] | 在键为key的元素上减少值value,value默认为1,可能改变原值 |
| addServer | host, [port], [persistent], [weight], [timeout], ...... | 添加一个memcache服务到连接池(保存多个memcache连接的地方)中,即建立一个到host的连接,port为端口 |
| pconnect | host, [port], [timeout] | 建立到位于host主机的memcache服务器的持久连接,port为端口,脚本执行完或调用close也无法关闭这种连接 |
其中有几点需要留意下:
1. set和replace的用法区别:set几乎任何情况下,当然不是连接都失败、内存不够用等硬性原因,都是成功的,replace只是在已经存在的键的基础上进行修改,键若不存在不成功;
2. connect方法建立的连接,要么脚本运行结束自己断开,要么调用close()方法被断开掉;
3. increment或者的decrement方法得到的数永远是大于或等于0,如果确实计算后得到的值是小于0的则进行转化,比如int类型,32位上占4字节,则返回的值是(232-1),计算后大于或等于0的直接返回;而元素之类型为非数字(或数字字符串)的,先转为数字再计算;
4. 当我们new一个Memcache对象并进行连接时,可以有两种方式,一是connect方法:$mem =new Memcache; $mem->connect(‘127.0.0.1‘, 11211); 或者使用addserver方法:$mem->addServer(‘127.0.0.1‘, 11211); 后者以向已有的连接池中添加一个Memcache服务器连接的方式建立,效果一样。
Redis,一款强大的缓存工具,得益于在国内门户网站中的广泛使用,功能上在不断完善,现在有稳定的版本(貌似微软github上最新64位的release 2.8版本,在我工作的机子上运行不起来...),方法比memcache多得多,作为开发使用到的主要是数据的存取,而其他的事物、通信协议、集群,在一般开发个后台,不是对速度追求到极致的情况下,还是基本用不到。redis中有按操作分为以下几种类型:
1. String:也是key-value对,主要也是对它的键对应的元素进行get、set、求长度、自增等操作,redis将添加的类型全存为字符串,即便纯数字;
2. Hash:哈希表(散列表),就是数据结构中的字典,采用特定的散列算法,比如手机通讯录有几百人,以姓的第一个字母作为关键码进行排序,这样我们可以快速找到联系人,这是通过特定的映射方式,将一个字母与姓名联系起来。在redis中,创建hash表时,首先指定表名,你存在哪张表里边,然后指定一个域(field,实际就是一个变量),和它对应的值,单用cmd操作就像下面这样(在hash表hash1中存储一个域username对应值Jack,redis会自动建立username到Jack的映射),一张hash表里边可以存储多个域和对应的变量;

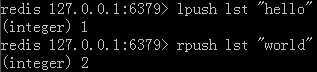
3. List:列表,类似于相当于数据结构的链表,通过它还可实现栈和队列,前面的string(这名字取得很怪异)存储一一对应的单个键值对,它则存多个值(没有键),重点是作为一个列表结构,它可以分别从左右(表头和表尾)进行插入和弹出变量值,求长度等一系列操作,这也是为什么称为列表,下面lpush、rpush命令就是从表左边和右边插入变量hello和world;
4. Set:集合,顾名思义也可以存储多个变量值(没有键),只是符合数学上定义的集合的特性,比如集合中元素不重复,因此set中各个数据对的键名也不一样,它也可以进行并、交、差等运算(下面命令是向集合mySet添加一个值var);

5. SortedSet:有序集合,可看做Set的特殊方式,在每一个SortedSet类型集合中,添加一个值(没有键)时,都要给它们指定一个称为score的变量值,有序有序,得有个字段来判定它的顺序是不,就是这个玩意儿,下面命令创建一个有序集合stset,添加一个值google.com,它的score是10。其实猜也猜得到,既然叫有序集合,既然给定了score,基本确定可以用这个来进行某些排序操作,事实也是这样;

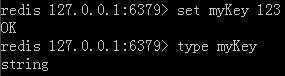
6. Key:单独对键进行操作,当然对其对应的元素值也有影响,如查看键对应元素的数据类型、键对应元素的存活时间、重置存活时间、返回所有键、正则形式查看相关键名、删除键(元素也跟着没了)等等。它不是数据类型,实际上,Redis把Hash表表名、List列表表名、集合Set名都称为键,整个集合或者表是它的值。下面是type命令查看它存储值得类型,它存储的是List列表。

上面这些命令,找个参考文档走一遍,很快就能玩熟,个人在这儿也只是泛泛而谈。那么在实际项目中,通常是怎样使用缓存呢?不往大的谈,比如微博的缓存设计,这可能涉及到架构层面的东西了,单说作为一个有一定访问量的后台,又想使用缓存来提高速度的情况下。
一个重要的原则(个人目前碰得多的情况)是,以传入的参数来拼键名,以这个键名来存取值。比如现在Model模型类里面有个方法:getUserInfoByUid($params),传入包含uid字段的数组查询这个用户的信息,在这儿使用缓存,先取缓存数据,取不到则去查数据库,然后重新加入缓存,最后返回结果数据,这也是使用缓存的一个通用流程。
以Memcache为例,先看代码,定义一个Cache类:
/** * Memcache缓存类 */ define(‘CACHE_HOST‘, ‘127.0.0.1‘); define(‘CACHE_PORT‘, 11211); class Cache{ private static $instance = null; private $_cache = null; // 缓存操作对象 const prefix = ‘APP|‘; // 缓存键值的前缀,为该项目名称 private function __construct(){ if($this->_cache === null){ try{ $this->_cache = new Memcache; if(!$this->_cache->connect(CACHE_HOST, CACHE_PORT)){ exit(‘connect failed‘); } } catch(Exception $e){ echo ‘ERROR: ‘.$e->getMessage(); } } } /** * 返回单例 */ public static function getInstance(){ if(self::$instance === null){ self::$instance = new self(); } return self::$instance; } /** * 生成键名 */ private function genKey($key){ return Cache::prefix.$key; } public function __destruct(){ if($this->_cache !== null){ return $this->_cache->close(); } } /** * 添加元素,设置过期时间 */ public function add($key, $val, $expire = 3600){ return $this->_cache->add($this->genKey($key), $val, 0, $expire); } /** * 重置元素 */ public function set($key, $val, $expire = 3600){ echo ‘cache key: ‘.$this->genKey($key).‘<br/>‘; // test return $this->_cache->set($this->genKey($key), $val, 0, $expire); } /** * 获取元素 */ public function get($key){ return $this->_cache->get($this->genKey($key)); } /** * 自增 */ public function increment($key, $val = 1){ return $this->_cache->increment($this->genKey($key), $val); } /** * 自减 */ public function decrement($key, $val = 1){ return $this->_cache->decrement($this->genKey($key), $val); } /** * 删除元素 */ public function delete($key, $timeout = 0){ return $this->_cache->delete($this->genKey($key), $timeout); } /** * 删除所有元素 */ public function flush(){ return $this->_cache->flush(); } }
然后定义一个操作数据库操作类:
/** * 数据库操作 */ define(‘DB_NAME‘, ‘test‘); define(‘DB_HOST‘, ‘127.0.0.1‘); define(‘DB_PORT‘, 3306); define(‘DB_USER‘, ‘root‘); define(‘DB_PASS‘, ‘1234‘); class Dal{ private static $instance = null; public $pdo = null; private function __construct(){ try{ $dsn = ‘mysql:dbname=‘.DB_NAME.‘;host=‘.DB_HOST.‘:‘.DB_PORT; $this->pdo = new PDO($dsn, DB_USER, DB_PASS); } catch(PDOException $e){ echo ‘Error: ‘.$e->getMessage(); return false; } } //获取实例 public static function getInstance(){ if(self::$instance === null){ self::$instance = new self(); } return self::$instance; } // 获取用户信息 public function getUserInfoByUid($uid){ $sql = sprintf(‘select * from tab1 where uid = %s limit 1‘, $uid); $stmt = $this->pdo->query($sql); return $stmt->fetch(PDO::FETCH_ASSOC); } }
而一般来说,通常是在Model模型类中才对数据进行读写,因此再定义一个UserModel类,尽量从简,不再去写可能会有的Model公共公共基类。
include ‘Dal.php‘; include ‘Cache.php‘; class UserModel{ private static $instance = null; public $cache = null; public $db = null; // 缓存键名部分,通过函数名称及参数拼接 const cache_get_userinfo_uid = ‘GET|USER|INFO|BY|UID|%s‘; private function __construct(){ // 获取对应类实例 $this->cache = Cache::getInstance(); $this->db = Dal::getInstance(); } public static function getInstance(){ if(self::$instance === null){ self::$instance = new self(); } return self::$instance; } /** 根据uid获取用户信息 */ public function getUserInfoByUid($params, $timeout = 3600){ // 缺少必要参数uid,返回 if(empty($params[‘uid‘])){ return null; } // 拼接缓存键名 $key = sprintf(self::cache_get_userinfo_uid, $params[‘uid‘]); // 获取缓存数据 $data = json_decode($this->cache->get($key), true); echo ‘cache=><pre>‘; var_dump($data); // 缓存为空 if(!$data){ $data = $this->db->getUserInfoByUid($params[‘uid‘]); if(empty($data)){ return null; } // 在数据库中获取到数据后,重新写入缓存 $this->cache->set($key, json_encode($data), $timeout); } else{ } return $data; } } // 测试 $data = UserModel::getInstance()->getUserInfoByUid(array(‘uid‘=>17653), 5); echo ‘UserModel=><pre>‘; var_dump($data);
这里,我们要通过用户的uid获取一个用户的信息,这个查询条件是uid,传过来的必要参数是uid,本来我们就是要缓存每个用户的数据,以期在重复查询时速度更快,因此在定义缓存的键时,就可以考虑使用uid。但是单单使用这个uid不行,因为假如其他的表中也有根据uid查询的,就会出现键名重复,造成了数据混乱,好我们使用的是getUserInfoByUid这个方法,可以把方法名也拼进去,因此在UserModel类中,定义了一个常量cache_get_userinfo_uid,它最后的%s就是为了拼接参数uid。但是,这样可能还是不行,现在公司启动了另外一个项目,也要用到这个表,某人写的方法跟这个方法名完全一样,毕竟函数名字又没有专利,而且运维一般单独拿服务器出来作为缓存使用,几个项目公用一台服务器,数据写在一个缓存池里也正常,此时可以考虑再加个前缀---工程名称(或说项目),因此,在Cache类中,又定义了一个常量prefix,给这个项目叫APP,这样基本就可以保证不会冲突了。当然如果这是一个组的子项目,这个组还有其他项目,这个组叫Star的话,可以再将项目组名称加在前面。
看看效果,第一次(左边)运行读取cache是空的,但是可以看到打印的缓存键名,


第二次(右边)cache就有数据了,因为我把打印缓存键名的地方放在Cache类的set方法中,第二次直接读到了缓存数据,没有去连数据库,自然也没有重置缓存,所以没打印cache key。
扯了半天就是要保证键名不冲突,也夹杂了一般在一个项目中怎样使用缓存,有几个供参考的方式:
1. 当前参数,可以有几个拼接几个,这里只举了个uid,假如还有name, age等等,可以都放在后面,具体怎么弄看个人喜好或者代码规范;
2. 当前方法名称,尽量接近当前方法名称,拼在缓存key中间;
3. 当前项目名称作为前缀(可选),更安全;
4. 所在项目组名称,再次作为前缀拼进来(一般用不到)。
然后就是,在Model模型类中,先取缓存,取不到则读数据库,读到后不要忘了写入缓存,设置好过期时间等细节,就这么一个流程。
当然你还可以做得更加细致,比如读取到缓存数据后,再检测下它的过期时间,发现还有5秒就要过期了,于是我们重新给它设置为3000秒,这样下次访问时又能取到了,不至于下次又读库,频繁地连接数据库是很耗时的一件事。
不过我还是觉得Redis好用,Redis中的Hash表最好的啦>-_-<,但恰好机子上还没配。
唔......不早了,洗洗睡~=_=
标签:
原文地址:http://www.cnblogs.com/lazycat-cz/p/4251597.html