标签:hadoop
学习笔记:王家林老师的hadoop课程 链接:http://edu.51cto.com/course/course_id-1151.html
Hadoop --- 适合海量数据的分布式存储与计算平台
存储与计算平台:Hadoop是一个平台,在这个平台上可以实现存储与计算
分布式:单虚拟机程序变为多虚拟机程序,也就是我的一个计算任务可以被多台虚拟机去计算完成
(这中间有一个任务分配过程)
海量数据:Hadoop的对象可以是海量数据,同样也可以是少量数据,这时候我们可以用java程序进行处理,而java程序也可以转化为Hadoop程序。在实践上我们知道,海量数据指1T级别以上的数据,少量数据虽然可以用Hadoop去做,但我们可以发现效率不如单机版高,不如单机版快。
当数据量很少的时候,我们的侧重点应该是单机如何更快的去完成,而不是将时间花费在怎样将这些数据分配到多台虚拟机上。但如果是海量数据就不同了,将海量数据交给一台虚拟机去计算处理那样有可能负载过高,这时候我们的侧重点就应该在如何将这些数据分配到多台虚拟机上,从而使数据处理完成的更加高效。
适合:海量数据可以凸显Hadoop的优势,小数据虽然可以处理,但从效率等多方面考虑,Hadoop就不提倡了。
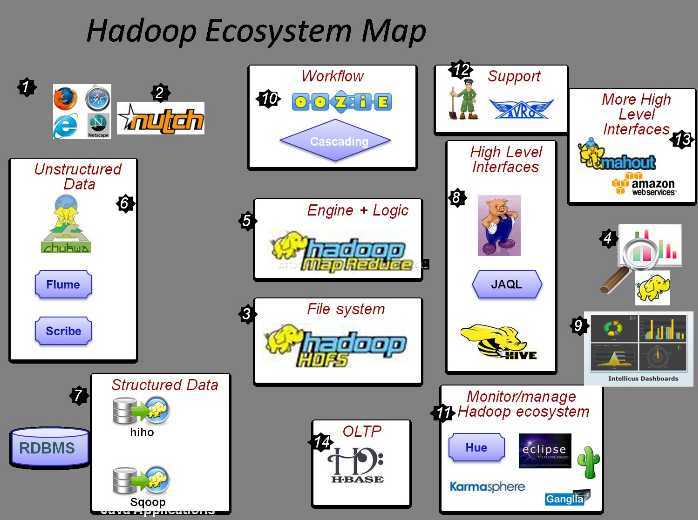
Hadoop图是一个庞大的生态系统图,是由一个生态链构成的
核心是3和5 map reduce和HDFS
★HDFS: Hadoop Distributed File System 分布式文件系统
提供了一套机制可以让我们的数据可以分布在不同的计算机上,我们不用关心数据到底是怎样存储的,HDFS可以完成
实现Hadoop的存储功能,是文件和程序的存储系统
HDFS的架构
主从结构:主节点(namenode)只有一个,从节点(datanodes)有很多个
主节点负责: 接收用户操作请求;维护文件系统的目录结构;管理文件与block之间的关系,block与datanode之间的关系(整个文件系统是分块的,数据存储在块上)。
从节点负责:存储文件;文件被分成block存储在磁盘上;为保证数据安全,文件会有多个副本。
namenode负责管理项目(数据存储与操作),相当于项目经理
datanodes负责存储数据,相当于开发工程师
★map reduce: 并行计算框架 (核心的核心)
海量数据的分布式计算框架
计算代码在不同机器上运行,每台机器只做计算中的一部分(因为其只包括一部分数据),然后再把各个机器的计算结果汇总起来
map reduce 的架构
主从结构:主节点(JobTracker)只有一个,从节点(TaskTrackers)有很多个
主节点负责:接收客户提交的计算任务;把计算任务分给TaskTrackers执行;监控TaskTracker的执行情况(是否分配成功、工作进度、工作结果)。
从节点负责:执行主节点分配的计算任务。
如果一台虚拟机无法完成分配的任务,那么主节点会透明将任务分配到其他虚拟机上
1:通过http协议是可以访问我们map ruduce的
6:日志数据
7:完成传统关系型数据和Hadoop中数据的相互转换,传统关系中的数据可以导入到Hadoop中,Hadoop中的数据也可以导入到传统关系型数据中
14:hbase 时时处理大数据读写操作的,尤其适合一些在线系统(大数据:构建方式、数据量)
Hadoop的特点:
扩容能力:能可靠地存储和处理千兆字节数据
成本低:可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
高效率:通过分发数据,hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速
可靠性:hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署计算任务
标签:hadoop
原文地址:http://caoyue.blog.51cto.com/9876038/1610158