标签:
数据预处理章节,整理于《数据挖掘·概念与技术》第三章,如有错误,请指正,谢谢~
1、概述
数据清理可以去除数据中的噪声,纠正不一致。数据集成将数据由多个数据源合并成一个一致的数据进行存储,如数据仓库。数据规约可以通过如聚集,删除冗余特征或聚类降低数据的规模。数据变换(如规约化)可以把数据压缩到较小的区间,如0.0到1.0。这可以提高设计距离度量数据挖掘算法的准确率和效率。
数据质量涉及到许多因素,包括准确性、完整性、一致性、时效性、可信性和可解释性。
在分析中使用多个数据源的数据那就是数据集成,数据集是巨大的,要降低数据集的规模,而又不损害数据挖掘的结果--数据规约(data reduction); 维规约:用数据编码方案,得到原始数据的简化或“压缩”表示。包括数据压缩技术(例如小波变换和主成分分析),以及属性子集选择(例如去掉不相关的属性)和属性构造(例如从原来数据集导出更有用的小属性集);数据规约:使用参数模型(例如回归和对数线性模型)或非参数模型(例如直方图、聚类、抽样或数据聚集)用较小的表示取代数据
离散化和概念分层产生 也可能是有用的。
规范化、数据离散化和概念分层产生都是某种形式的数据变换(data transformation)
2、数据清理
现实的数据一般是不完整的、有噪声的和不一致的。数据清理试图填充缺失值、光滑噪声并识别离群点、纠正数据中的不一致
2.1缺失值:
针对缺失值有很多种方法忽略改元组,人工填写,用一个全局变量填充,使用属性中心度量(均值或中位数)填充,使用与给定元组属同一类的样本属性均值或中位数代替, 使用最可能的值填充缺失值。
貌似方法"使用最可能的值填充缺失值"最靠谱:可以用回归、使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定。
2.2噪声数据:
“噪声”(noise)是被测量的变量的随机误差或方差
数据光滑技术:分箱(binning)、回归(regression)、离群点分析(outlier analysis)
回归:用一个函数拟合数据来光滑数据,线性回归找出拟合两个属性的最佳直线。多元线性回归是线性回归的扩充,属性多于2个,数据将拟合到一个多维曲面
有些分类方法有内置的数据光滑机制(如神经网络)
2.3数据清理作为一个过程
第一步是偏差检测(discrepancy detection),例如,找出均值,中位数,众数。数据是对称的还是倾斜的?值域是什么?所有的值是否都落于期望区间?每个属性的标准差是多少?远离给定属性均值超过两个标准差的值可能标记为可能的离群点。属性之间是否存在已知的依赖关系?
还可以根据唯一性规则、连续性规则和空值规则考查数据。
3、数据集成
3.1实体识别问题:
数据集成是将来自多个数据源的数据合并,并存放在一个一致的数据存储中。考虑多个信息源的现实世界的等价实体如何相互“匹配”?如一个customer_id字段与另一个数据库中的cust_number是否相同属性。要考虑每个属性的元数据,包括名字、含义、数据类型、和取值范围,以及处理空白,空值和null的规则。 还可以进行变换数据,如性别有的用B和G代表,还有的用1和2代表
3.2冗余和相关性分析
冗余是常见的,比如一个属性(年收入)可以由其他属性导出(月收入),那么就是冗余的。
冗余可以被相关分析检测到。对于标称数据可以用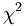 (卡方)检验;对于数值型数据可以用相关系数(correlation coefficient)和协方差(covariance)检验,这两个都是评估一个属性的值如何随另一个属性值变化。
(卡方)检验;对于数值型数据可以用相关系数(correlation coefficient)和协方差(covariance)检验,这两个都是评估一个属性的值如何随另一个属性值变化。
(1)标称数据的卡方相关检验:
有两个属性A和B,属性A有c个不同值,a1,a2……ac;属性B有r个不同值,b1,b2,……br;A和B两个属性描述的数据元组可以用一个相依表显示,A属性为列,B属性为行,构成的每个元组(Ai,Bj);则卡方的表达式为:
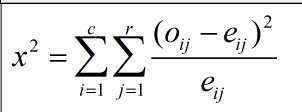 Oij是联合事件(Ai,Bj)的实际观测频度,Eij则是(Ai,Bj)的期望频度。
Oij是联合事件(Ai,Bj)的实际观测频度,Eij则是(Ai,Bj)的期望频度。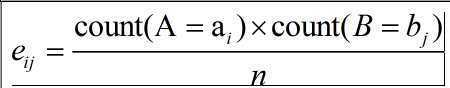 其中n是数据元组的个数,count(A=ai)表示A上具有ai值的所有个数,同理。
其中n是数据元组的个数,count(A=ai)表示A上具有ai值的所有个数,同理。
卡方统计检验假设A和B都是独立的,检验基于显著水平,具有自由度(r-1)X(c-1),如果可以拒绝改假设,则我们可以说A和B是统计相关的。
例子1:性别与是否爱阅读小说的卡方检验
| 男 | 女 | 合计 | |
| 小说 | 250(90) | 200(360) | 450 |
| 非小说 | 50(210) | 1000(840) | 1050 |
| 合计 | 300 | 1200 | 1500 |
其中括号内的数是期望频率,期望频率是根据两个属性的数据分布用eij式子计算得来,如(男,小说)的期望频率是e11 = count(男)Xcount(小说) / n = 300X450/1500 = 90
注意:任意行,期望频率的和必须等于改行总观测频率,并且任意列的期望频率和也必须等于该列的总观测频率。利用卡方计算公式有
![]() =284.44+121.90+71.11+30.48 = 507.93
=284.44+121.90+71.11+30.48 = 507.93
对于2X2的表,自由度为(2-1)X(2-1)=1, 自由度为1,在0.001置信水平下,拒绝假设的值为10.828,我们计算值大于该值,因此我们拒绝两个属性独立的假设。
例2:医院分别用化疗和化疗结合放射结合两种方法,如图
| 组别 | 有效 | 无效 | 合计 | 有效率(%) |
| 化疗组 | 19 | 24 | 43 | 44.2 |
| 化疗加放疗组 | 34 | 10 | 44 | 77.3 |
| 合计 | 53 | 34 | 87 | 60.9 |
分别计算期望频度,总数n是87,第一行第一列:count(有效)Xcount(化疗组)/n=53*43/87=26.2;第一行第二列:count(化疗)Xcount(无效)/n=43*34/87=16.8;第二行第一列:count(化疗加放疗)Xcount(有效)/n=44*53/87=26.8;第二行第二列:44*34/87=17.2
| 组别 | 有效 | 无效 | 合计 |
| 化疗组 | 19(26.2) | 24(16.8) | 43 |
| 化疗加放疗组 | 34(26.8) | 10(17.2) | 44 |
| 合计 | 53 | 34 | 87 |
则卡方的值为:(19-26.2)^2/26.2 + (34-26.8)^2/26.8 +(24-16.8)^2/16.8 + (10-17.2)^2/17.2 = 10.01
在查表之前应知本题自由度。按x2检验的自由度v=(行数-1)(列数-1),则该题的自由度v=(2-1)(2-1)=1,查x2界值表(附表20-1),找到x20.001(1)=6.63,原地方是否差错了?而本题x2=10.01即x2>x20.001(1),P<0.01,差异有高度统计学意义,按α=0.05水准,拒绝假设独立,可以认为采用化疗加放疗治疗卵巢癌的疗效比单用化疗佳。
(2)数值数据的协方差与相关系数:
在概率论与统计学中,协方差和方差是具有类似的度量,协方差是方差在多维随机变量的扩展,即刻画随机变量在其中心位置附近散步程度的数字特征。
方差:Var(X)=E(X - EX)^2 ; 另EX=a,则 Var(X) = E(X^2) - 2aE(X) +a^2 = E(X^2) - (EX)^2
考虑两个数值属性A,B和多次观测的集合{(a1, b1), ……(an,bn)},协方差定义为: 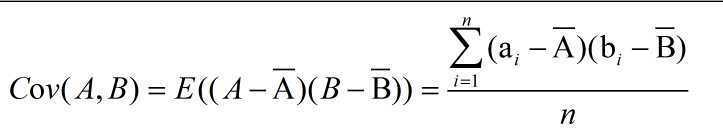
协相关系数的定义: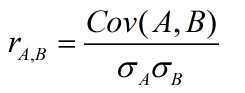 分子分别为A和B的标准差。 还可以证明Cov(A,B) = E(A·B) - E(A)·E(B)
分子分别为A和B的标准差。 还可以证明Cov(A,B) = E(A·B) - E(A)·E(B)
容易发现,对于两个趋向于一起改变的属性A和B,如果A大于期望A,则B很有可能大于期望B,那么此时协方差为正,且协相关系数>0,如果一个属性小于期望值,另一个属性趋向于大于期望值则,协方差为负,
若A,B独立(不具有相关性),那么协方差为0,反之不成立。
协方差例子:
交易数据与股票价格的简化例子,如果股市收到相同的产业趋势影响,他们的股价会一起涨跌吗,E(electronics)=(6+5+4+3+2)/5 = 4美元,E(HighTech)=(20+10+14+5+5)/5=10.8美元
则协方差为Cov() = E(A·B)- E(A)·E(B) = 7,则表明是正相关。
4、数据规约(待完善)
5、数据变换与数据离散化(待完善)
标签:
原文地址:http://www.cnblogs.com/2589-spark/p/4261169.html