第七届中国R语言会议
小记
R语言始于1993年,并在1995年首次发布,后来经过2000年R-1.0,2004年R-2.0和2013年R-3.0,以61%的得票荣登世界编程或同积累语言排行榜榜首,远超Python,SQL,SAS,JAVA,Excel和Rapidminer。
R最初是一种基于数学的脚本语言,前身为S语言。但是论数学,远不及专业的Matlab和SAS;论脚本功能,又远不及Python和Perl。但是,随着R语言的发展,在功能强大的IDE,RStudio和R本身开源的双重帮助下,R语言成为了一门真正的语言。现在的R语言是面向对象的,可方便调试的,可并行处理和接口处理的不亚于C/C++、JAVA的高级语言。
本次大会最吸引我的是RStudio的首席科学家,Hadley Wickham的参与,他开发了著名的ggplot2,plyr,dplyr,shiny,devtools,stringr,ggvis,httr。ggplot2使得R语言可以更方便的制作各类精美图片;plyr和dplyr使得R语言更便于处理各类字符、数据的类型转化;shiny是一种懒人制图,可以像VISIO等软件一样,直接对图片进行修改来返回对应的R语言代码,本次大会的后续图形专题部份,都是基于shiny的扩展;devtools是一种简便的傻瓜式的R语言包制作工具,本次大会HW为我们一步一步亲自演示了该包的使用,以及如何让R语言完美的与C++语言结合等;stringr,包如其名,是一种字符串处理工具,让R语言可以像Perl和Python等脚本语言一样进行格式化操作;ggvis是本次大会HW大神为我们带来的另一个手把手教程讲座,该包是HW制作的基于网页的扩张包,不但包含了ggplot2的所有功能,而且可以直接用R语言制作html5的最新版网页,并且让其中的图片动起来,本次大会的图形专题也是基于该包的扩张。HW还表示,自己未来将开发让R更便于链接数据库的包,让R处理PB级大数据时更加游刃有余。
一、深度学习专题:
深度学习是一种专门针对大数据的学习,通过不断地有监督学习,而达到预测、分析等预期目标。本次大会包括百度深度学习研究院(IDL)常务副院长余凯在内的众多专家都讲述了深度学习知识。
深度学习主要分为三个模块。一,model-based。学习首先要有学习法则,即模型建立。任何模型都是有极限的,突破其极限就是众多科研人员所要做的,台湾科学家张家齐重点讲述了Hacking Models with R部分,他形容,数学建模就是绘画,从不同的角度作画,得到的画是不同的,而对于同一事物的一种画,是可以由多种角度完成的。R建模也一样,要想分析数据本身,一个模型的角度往往是不够的,但是当有了事实与结论,来寻找事实到结论的映射关系模型时,往往相对较容易。二,analyze。针对模型的分析方法有很多,百度所使用的是前前馈型神经网络模型,给出一组输入,通过神经网络的加权求解,得出预测、分类等不同结果,如图:
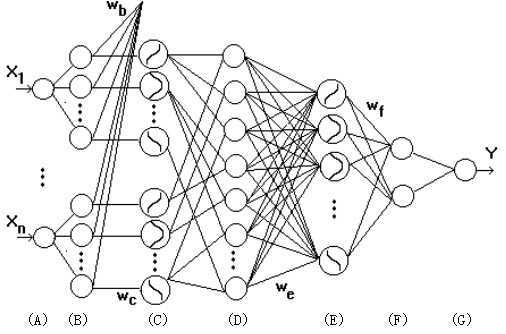
百度建议的前馈型神经网络是一种四层网络达到语音识别的模式识别效果的深度学习模型,第一层是用户输入层,第二层是文本分析层,第三层是声音处理层,第四层是最终的模式识别部分。和其他人深度学习专题差不多,所有人的学习过程都是一种Boltzmann机算法的改进。
二、聚类分类专题:
聚类分类是本次大会一个热门话题,包括中国科学研究院James Wicker在内的众多学者探讨了该问题。James Wicker的方法与以往的众多聚类分类算法不同,他的方法更好的发挥了R语言在数学上的强项,是一种基于统计的混合模型聚类分类(Mixture-Modeles),讲座围绕这混合高斯分布模型(GMM)。该模型特点是一种基于中心极限定理的扩展。
中心极限定理(central limit theorem):Lindburg-Levy:设随机变量X1,X2,......Xn,......相互独立,服从同一分布,且具有数学期望和方差:E(Xk)=μ,D(Xk)=σ^2>0(k=1,2....),则随机变量之和的标准化变量的分布函数Fn(x)对于任意x满足limFn(x)=Φ(x),n→∞ 其中Φ(x)是标准正态分布的分布函数。
根据中心极限定理可知,当样本数量达到一定规模时,样本必然服从高斯分布。如,四六级考试成绩等。反过来,如果一个样本服从一个高斯分布,那么他是同一类数据;如果服从两个高斯分布,那么他是由两类不同的数据叠加而成的;同理三个高斯分布,如图:
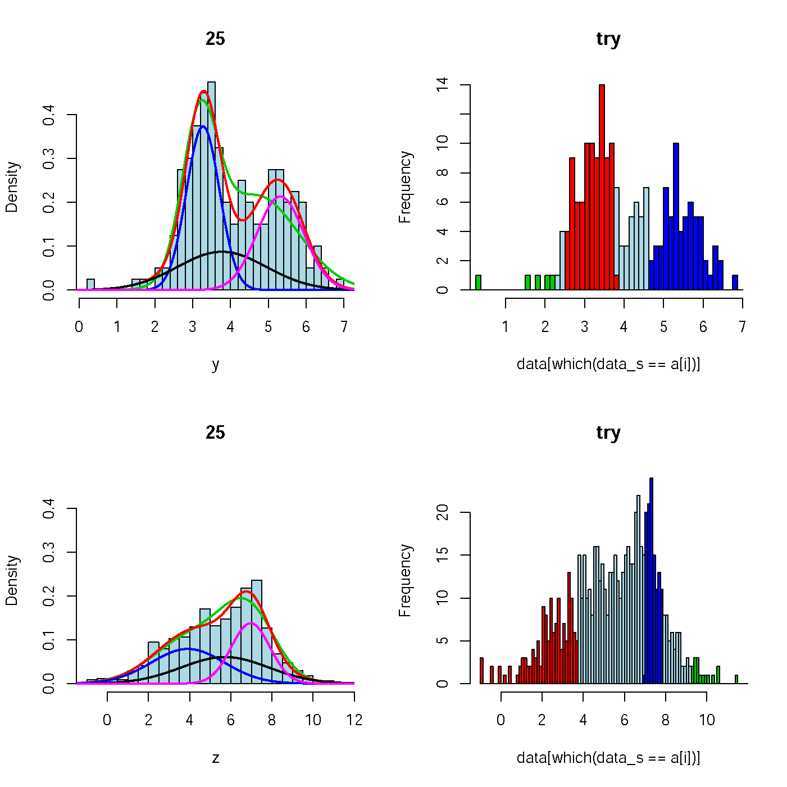
(这是一个R语言hist直方图画的样本,使用R语言Plot根据高斯分布数量将数据着色成不同颜色,中间亮蓝色区域是OVERLAPPING区域,图中是三个高斯分布,对应左侧的黑、蓝和紫三种颜色。)
中国科学院计算混合模型方法是用极大似然估计法,配合EM加速算法,最快求出高斯分布对应的均值和方差。包括贝叶斯信息准则(BIC)在内的若干信息评估函数进行评估。JW教授同样提到了超几何分布测试。Hypothesis Test,是一种对总体样本取样的最好的假设检验方法,总体是样本本身,不放回抽样是其中的高斯小分布。一个小高斯分布是否合理,就是这个小高斯分布与总体样本的超几何分布(P-Value)。
三、性能提升专题:
R语言的性能就如同matlab最初一样,无论数据规模和处理时间都很不理想。来自Revolution Analytics的David Smith建议购买他们公司的产品。包括华南统计科学研究中心的寇强等人建议用技巧进行优化。
1)大数据。由于R语言处理数据是将数据全读入内存中。当数据规模达到一定级别时,计算机就处理不了了。在无法增加内存的情况下,众多学则建议用R语言链接数据库来解决这个问题。把不用的数据放在数据库中,待需要时读取。Hadley Wickham大师的dplyr就是高效处理数据库连接的包。
2)效率。R语言对for循环的支持和Matlab一样很不理想。官方建议为在处理for循环时,尽量使用矩阵运算来提升速度。这里很多人建议使用Rcpp包,完美引入c++语言来解决这个问题。让耗时的复杂运算,用c++来高效处理。据华南统计科学研究中心的寇强介绍,他的R-CPP翻译将在年底再版。
四、数据的可视化:
Hadley Wickham大师亲自参讲授了该本分,是本次大会的亮点。主要包括大家关心的网页图片展示,以及动态图片制作。如,可以直接通过R返回html动态网页,在里面写字和展示图。其中图是可以自由控制的,比如直接对图片操作删去一些不想看的样本,在网页中返回新的图。还可以直接拖拽网页图片中元素,使得便于看重叠的图。直接操作图还可以在网页中返回修改后的R代码,在R中操作直接生成新图。因为参数过多,默认参数生成的图可能不理想,我摆放一个理想图,并得到这个理想图的参数。当然,还可以在网页中直接放大图。并且鼠标移动到一些图中元素,会动态显示这个元素的样本信息。如果同一个样本生成多个图,还可以在一个图中选择几个点,其它图自动标记这些点对应的位置。
五、R语言在生物信息学中的应用:
本部分主要讲授了Bioconductor和R在新要研发中的应用等知识。
原文地址:http://www.cnblogs.com/acmicpc/p/3757770.html