标签:Lucene c style class blog code
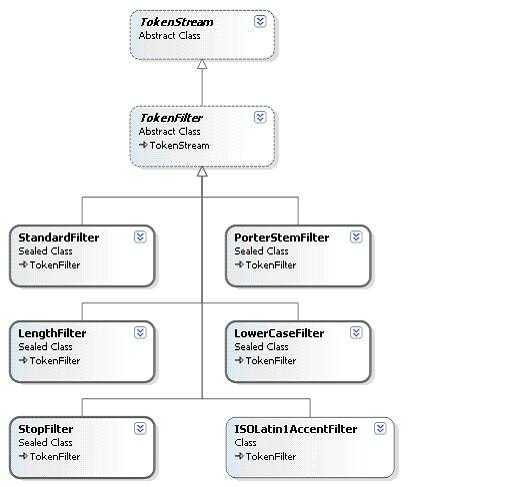
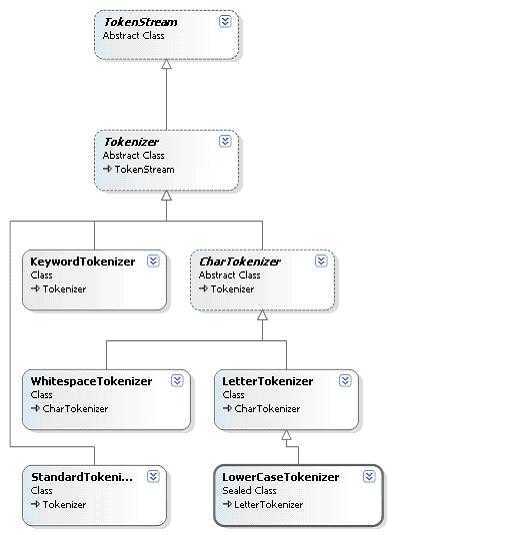
TokenStream是一个能在被调用后产生语汇单元流的类,但是 TokenStream 类有两个不同的类型:Tokenizer 类和 TokenFilter 类。这两个类都是从抽象类TokenStream类继承而来。
Tokenizer 对象通过Java.io.Reader 对象读取字符创建语汇单元,而TokenFilter 类则负责处理输入的语汇单元,然后通过新增、删除或者修改属性的方式来产生新的语汇单元。
当分词器从tokenStream 方法或者 reusableTokenStream 方法返回tokenStream 对象后,它就开始用一个tokenizer对象创建初始的语汇单元流,然后再链接到任意数量的tokenFilter对象来修改这些语汇单元。这被称为分词器链。
Tokenizer是一个以Reader为输入的TokenStream;而TokenFilter是一个以另一个TokenStream为输入的TokenStream。
表面上看两者只是输入不同,但正因为这一点,Tokenizer被用来做初级的文本处理,它把从Reader读入的原始文本通过一些简单的办法处理成一个个初级的token;TokenFilter则以Tokenizer为输入(因为Tokenizer继承自TokenStream),用一些规则过滤掉不符合要求的token(像StopFilter中的停用词),产生最终的token stream。
还记得前文说的WhitespaceAnalyzer和SimpleAnalyzer引用的都是Tokenizer,StopAnalyzer和StandardAnalyzer引用的都是TokenFilter吗?这就是因为前二者处理规则比较简单,用Tokenizer把Reader的输入经过一步处理就够了;后二者处理要复杂一些,需要用到TokenFilter,而TokenFilter在Tokenizer处理的基础上进行一些过滤,这样才能满足后二者的需要。
另外,引用他人的解释
Lucene Analyzer包含两个核心组件,Tokenizer以及TokenFilter。两者的区别在于,前者在字符级别处理流,而后者则在词语级别处理流。Tokenizer是Analyzer的第一步,其构造函数接收一个Reader作为参数,而TokenFilter则是一个类似拦截器的东东,其参数可以使TokenStream、Tokenizer,甚至是另一个TokenFilter。整个Lucene Analyzer的过程如下图所示:
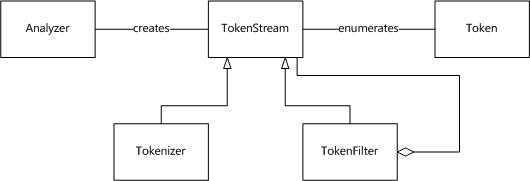
上图中的一些名词的解释如下表所示:
| 类 | 说明 |
| Token | 表示文中出现的一个词,它包含了词在文本中的位置信息 |
| Analyzer | 将文本转化为TokenStream的工具 |
| TokenStream | 文本符号的流 |
| Tokenizer | 在字符级别处理输入符号流 |
| TokenFilter | 在字符级别处理输入符号流,其输入可以是TokenStream、Tokenizer或者TokenFilter |
关于Tokenizer与TokenFilter的区别,布布扣,bubuko.com
标签:Lucene c style class blog code
原文地址:http://www.cnblogs.com/yaokaizi/p/3758563.html