标签:
经过一两个月的学习,对pf_ring DNA的内核部分有了一些认识,本文侧重pf_ring对ixgbe的改动分析。
先说一说接收流程吧,流程如下:
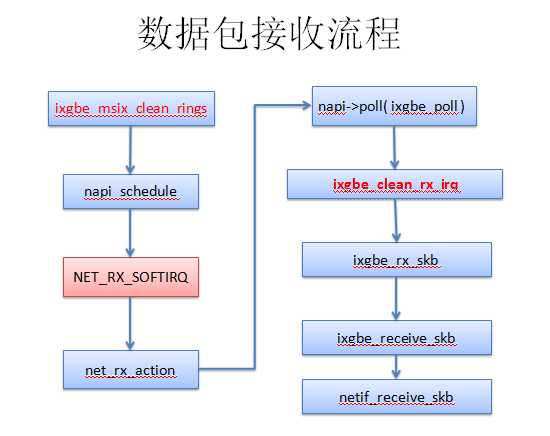
其中,硬中断处理函数是ixgbe_msix_clean_rings( );软中断处理函数是net_rx_action( )。
pf_ring对ixgbe的改动主要在ixgbe_poll()和ixgbe_clean_rx_irq()中。
在ixgbe_poll( )中遍历每个队列并轮询处理数据包,代码如下。
int ixgbe_poll(struct napi_struct *napi, int budget) { struct ixgbe_q_vector *q_vector = container_of(napi, struct ixgbe_q_vector, napi); struct ixgbe_adapter *adapter = q_vector->adapter; struct ixgbe_ring *ring; int per_ring_budget; bool clean_complete = true; #if defined(CONFIG_DCA) || defined(CONFIG_DCA_MODULE) //如果设定直接缓存访问技术 if (adapter->flags & IXGBE_FLAG_DCA_ENABLED) ixgbe_update_dca(q_vector); //怎么一点儿性能提升都没有呢? #endif ixgbe_for_each_ring(ring, q_vector->tx) clean_complete &= ixgbe_clean_tx_irq(q_vector, ring); //清理回收发送所用资源 #ifdef CONFIG_NET_RX_BUSY_POLL if (!ixgbe_qv_lock_napi(q_vector)) return budget; #endif /* attempt to distribute budget to each queue fairly, but don‘t allow * the budget to go below 1 because we‘ll exit polling */ if (q_vector->rx.count > 1) per_ring_budget = max(budget/q_vector->rx.count, 1); else per_ring_budget = budget; //默认为64,执行else分支 //for (ring = (q_vector->rx).ring; ring != NULL; ring = ring->next) ixgbe_for_each_ring(ring, q_vector->rx) //循环遍历每个ring clean_complete &= (ixgbe_clean_rx_irq(q_vector, ring, per_ring_budget) < per_ring_budget); //判断已处理包数是否小于事先设定值 #ifdef CONFIG_NET_RX_BUSY_POLL ixgbe_qv_unlock_napi(q_vector); #endif #ifndef HAVE_NETDEV_NAPI_LIST if (!netif_running(adapter->netdev)) clean_complete = true; #endif /* If all work not completed, return budget and keep polling 如果未全部完成*/ if (!clean_complete) return budget; /* all work done, exit the polling mode 如果已经全部完成 */ napi_complete(napi); //标记NAPI完成 if (adapter->rx_itr_setting == 1) ixgbe_set_itr(q_vector); //根据状况调整中断频率 if (!test_bit(__IXGBE_DOWN, &adapter->state)) //如果不是down状态 ixgbe_irq_enable_queues(adapter, ((u64)1 << q_vector->v_idx)); ////使能中断队列 return 0; }
pf_ring的修改只有一处:
#ifdef ENABLE_DNA
if(!adapter->dna.dna_enabled) //如果没有启动DNA
#endif
if (!test_bit(__IXGBE_DOWN, &adapter->state)) //如果不是down状态
ixgbe_irq_enable_queues(adapter, ((u64)1 << q_vector->v_idx)); //使能中断队列
//也就是说,DNA模式下不会执行使能中断队列
ixgbe_clean_rx_irq( )函数的代码如下:
1 static int ixgbe_clean_rx_irq(struct ixgbe_q_vector *q_vector, //把ring buffer的内容取出来转成sk_buff包 2 struct ixgbe_ring *rx_ring, 3 int budget) 4 { 5 unsigned int total_rx_bytes = 0, total_rx_packets = 0; 6 #ifdef IXGBE_FCOE 7 int ddp_bytes = 0; 8 #endif /* IXGBE_FCOE */ 9 u16 cleaned_count = ixgbe_desc_unused(rx_ring); //计算可清除的descriptors个数(打印其值为0,说明descriptors使用非常紧张) 10 11 do { 12 union ixgbe_adv_rx_desc *rx_desc; ////描述符 13 struct sk_buff *skb; //套接字缓冲区 14 15 /* return some buffers to hardware, one at a time is too slow */ 16 if (cleaned_count >= IXGBE_RX_BUFFER_WRITE) { //超过16个 17 ixgbe_alloc_rx_buffers(rx_ring, cleaned_count); //替换出已使用的descriptors,并修改next_to_use值 18 cleaned_count = 0; 19 } 20 //next_to_clean是可以清除的描述符编号,也就是网卡对描述符该做的工作已经做完,可以传递给上层协议 21 rx_desc = IXGBE_RX_DESC(rx_ring, rx_ring->next_to_clean); //将next_to_clean序号转换成相应的描述符 22 23 if (!ixgbe_test_staterr(rx_desc, IXGBE_RXD_STAT_DD)) //测试Descriptor Done位是否为1(表示网卡硬件已经处理完毕) 24 break; // 如果desc的DD位为0,则结束整个while循环, 也就是说,只有在DD位为1时才能往下执行 25 26 /* 27 * This memory barrier is needed to keep us from reading 28 * any other fields out of the rx_desc until we know the 29 * RXD_STAT_DD bit is set 30 */ 31 rmb(); 32 33 /* retrieve a buffer from the ring 根据描述符从接收环中提取一个缓冲单元*/ 34 skb = ixgbe_fetch_rx_buffer(rx_ring, rx_desc); //分配skb 35 36 /* exit if we failed to retrieve a buffer */ 37 if (!skb) 38 break; 39 40 cleaned_count++; 41 42 /* place incomplete frames back on ring for completion */ 43 if (ixgbe_is_non_eop(rx_ring, rx_desc, skb)) //返回false表示EOP位为1,并修改next_to_clean值,直接影响下一次循环的rx_desc 44 continue; //如果EOP为0,则结束本次循环,也就是说,只有在EOP为1时才能继续往下执行 45 46 /* verify the packet layout is correct */ 47 if (ixgbe_cleanup_headers(rx_ring, rx_desc, skb)) //检查数据包的header 48 continue; //如果header有误则返回true并释放skb 49 50 /* probably a little skewed due to removing CRC */ 51 total_rx_bytes += skb->len; 52 53 /* populate 填充 checksum, timestamp, VLAN, and protocol */ 54 ixgbe_process_skb_fields(rx_ring, rx_desc, skb); 55 56 #ifdef IXGBE_FCOE 57 /* if ddp, not passing to ULD unless for FCP_RSP or error */ 58 if (ixgbe_rx_is_fcoe(rx_ring, rx_desc)) { 59 ddp_bytes = ixgbe_fcoe_ddp(q_vector->adapter, 60 rx_desc, skb); 61 if (!ddp_bytes) { 62 dev_kfree_skb_any(skb); 63 #ifndef NETIF_F_GRO 64 netdev_ring(rx_ring)->last_rx = jiffies; 65 #endif 66 continue; 67 } 68 } 69 70 #endif /* IXGBE_FCOE */ 71 #ifdef CONFIG_NET_RX_BUSY_POLL 72 skb_mark_napi_id(skb, &q_vector->napi); 73 #endif 74 ixgbe_rx_skb(q_vector, rx_ring, rx_desc, skb); //调用netif_receive_skb接收数据包 75 76 /* update budget accounting */ 77 total_rx_packets++; 78 } while (likely(total_rx_packets < budget)); //是否已经达到设备的budget 79 80 #ifdef IXGBE_FCOE 81 /* include DDPed FCoE data */ 82 if (ddp_bytes > 0) { 83 unsigned int mss; 84 85 mss = netdev_ring(rx_ring)->mtu - sizeof(struct fcoe_hdr) - 86 sizeof(struct fc_frame_header) - 87 sizeof(struct fcoe_crc_eof); 88 if (mss > 512) 89 mss &= ~511; 90 total_rx_bytes += ddp_bytes; 91 total_rx_packets += DIV_ROUND_UP(ddp_bytes, mss); 92 } 93 94 #endif /* IXGBE_FCOE */ 95 u64_stats_update_begin(&rx_ring->syncp); 96 rx_ring->stats.packets += total_rx_packets; 97 rx_ring->stats.bytes += total_rx_bytes; 98 u64_stats_update_end(&rx_ring->syncp); 99 q_vector->rx.total_packets += total_rx_packets; 100 q_vector->rx.total_bytes += total_rx_bytes; 101 102 if (cleaned_count) 103 ixgbe_alloc_rx_buffers(rx_ring, cleaned_count); //分配clean_count个page建立流式映射 104 105 #ifndef IXGBE_NO_LRO 106 ixgbe_lro_flush_all(q_vector); 107 108 #endif /* IXGBE_NO_LRO */ 109 return total_rx_packets; 110 }
而pf_ring对ixgbe_clean_rx_irq( )函数的改动非常大:
static int ixgbe_clean_rx_irq(struct ixgbe_q_vector *q_vector,
struct ixgbe_ring *rx_ring,
int budget)
{
unsigned int total_rx_bytes = 0, total_rx_packets = 0;
#ifdef IXGBE_FCOE
int ddp_bytes = 0;
#endif /* IXGBE_FCOE */
u16 cleaned_count = ixgbe_desc_unused(rx_ring);
#ifdef ENABLE_DNA
struct ixgbe_adapter *adapter = q_vector->adapter;
if(adapter->dna.dna_enabled)
return(dna_ixgbe_clean_rx_irq(q_vector, rx_ring, budget)); //抛弃intel原有处理流程,调用PF_RING DNA独有的清理函数
#endif
..........................
}
再来秀一秀dna_ixgbe_clean_rx_irq()函数吧:
1 static bool dna_ixgbe_clean_rx_irq(struct ixgbe_q_vector *q_vector, 2 struct ixgbe_ring *rx_ring, int budget) { 3 union ixgbe_adv_rx_desc *rx_desc, *shadow_rx_desc, *next_rx_desc; 4 u32 staterr; 5 u16 i, num_laps = 0, last_cleaned_idx; 6 struct ixgbe_adapter *adapter = q_vector->adapter; 7 struct ixgbe_hw *hw = &adapter->hw; 8 unsigned int total_rx_packets = 0; 9 10 last_cleaned_idx = i = IXGBE_READ_REG(hw, IXGBE_RDT(rx_ring->reg_idx)); //读取tail 11 if(++i == rx_ring->count) 12 i = 0; 13 14 rx_ring->next_to_clean = i; //把i赋给next_to_clean 15 16 //i = IXGBE_READ_REG(hw, IXGBE_RDT(rx_ring->reg_idx)); 17 rx_desc = IXGBE_RX_DESC(rx_ring, i); //得到描述符 18 staterr = le32_to_cpu(rx_desc->wb.upper.status_error); //读取描述符状态 19 20 if(rx_ring->dna.queue_in_use) { //如果应用程序正在使用该接收队列 21 /* 22 A userland application is using the queue so it‘s not time to 23 mess up 弄乱 with indexes but just to wakeup apps (if waiting) 24 */ 25 26 /* trick for appplications calling poll/select directly (indexes not in sync of one position at most) */ 27 if (!(staterr & IXGBE_RXD_STAT_DD)) { 28 u16 next_i = i; 29 if(++next_i == rx_ring->count) next_i = 0; 30 next_rx_desc = IXGBE_RX_DESC(rx_ring, next_i); 31 staterr = le32_to_cpu(next_rx_desc->wb.upper.status_error); 32 } 33 34 if(staterr & IXGBE_RXD_STAT_DD) { 35 if(unlikely(enable_debug)) 36 printk(KERN_INFO "DNA: got a packet [index=%d]!\n", i); 37 38 if(waitqueue_active(&rx_ring->dna.rx_tx.rx.packet_waitqueue)) { 39 wake_up_interruptible(&rx_ring->dna.rx_tx.rx.packet_waitqueue); 40 rx_ring->dna.rx_tx.rx.interrupt_received = 1; 41 42 if(unlikely(enable_debug)) 43 printk("%s(%s): woken up ring=%d, [slot=%d] XXX\n", 44 __FUNCTION__, rx_ring->netdev->name, 45 rx_ring->reg_idx, i); 46 } 47 } 48 49 // goto dump_stats; 50 return(!!budget); 51 } 52 53 /* Only 82598 needs kernel housekeeping 家务 (82599 does not need that thanks 54 to the drop bit), as the drop flag does not seem to work 55 只有82598网卡因drop标志位似乎不能工作而需要做杂务处理, 56 而82599不需要继续执行 57 */ 58 if(adapter->hw.mac.type != ixgbe_mac_82598EB) 59 return(!!budget); //可是,82599网卡怎么收包呢? 60 61 if( /* staterr || */ enable_debug) { 62 printk("[DNA] %s(): %s@%d [used=%d][idx=%d][next_to_use=%u][#unused=%d][staterr=%d][full=%d][pkt_ptr=%llu]\n", __FUNCTION__, 63 rx_ring->netdev->name, rx_ring->queue_index, 64 rx_ring->dna.queue_in_use, i, rx_ring->next_to_use, 65 ixgbe_desc_unused(rx_ring), staterr, dna_ixgbe_rx_dump(rx_ring), rx_desc->read.pkt_addr); 66 } 67 68 /* 69 This RX queue is not in use 用户空间的程序没有使用该接收队列 70 71 IMPORTANT 72 We need to poll queues not in use as otherwise they will stop the operations 73 also on queues where there is an application running that consumes the packets 74 */ 75 while(staterr & IXGBE_RXD_STAT_DD) { //轮询DD状态的描述符 76 shadow_rx_desc = IXGBE_RX_DESC(rx_ring, i+rx_ring->count); //影子描述符 77 rx_desc->wb.upper.status_error = 0, last_cleaned_idx = i; 78 rx_desc->read.hdr_addr = shadow_rx_desc->read.hdr_addr, rx_desc->read.pkt_addr = shadow_rx_desc->read.pkt_addr; //从影子描述符中取出数据包和包头的DMA地址 79 80 rmb(); //内存屏障,保证代码执行顺序 81 82 // REMOVE BELOW 83 // ixgbe_release_rx_desc(rx_ring, i); /* Not needed */ 84 85 i++, num_laps++, budget--; 86 if(i == rx_ring->count) //环状数组,逆转 87 i = 0; 88 89 rx_desc = IXGBE_RX_DESC(rx_ring, i); //取出描述符 90 prefetch(rx_desc); //预取描述符 91 staterr = le32_to_cpu(rx_desc->wb.upper.status_error); 92 93 if(budget == 0) break; 94 } 95 96 rx_ring->stats.packets += total_rx_packets; 97 // rx_ring->stats.bytes += total_rx_bytes; 98 q_vector->rx.total_packets += total_rx_packets; 99 // q_vector->rx.total_bytes += total_rx_bytes; 100 101 /* Update register 更新寄存器 */ 102 rx_ring->next_to_clean = i, IXGBE_WRITE_REG(&adapter->hw, IXGBE_RDT(rx_ring->reg_idx), last_cleaned_idx); 103 104 if(unlikely(enable_debug)) { //忽略 105 int j=0, full = 0, other = 0, null_dma = 0; 106 struct ixgbe_rx_buffer *bi; 107 108 for(j=0; j<rx_ring->count; j++) { 109 rx_desc = IXGBE_RX_DESC(rx_ring, j); 110 prefetch(rx_desc); 111 staterr = le32_to_cpu(rx_desc->wb.upper.status_error); 112 113 bi = &rx_ring->rx_buffer_info[i]; 114 115 if(staterr & IXGBE_RXD_STAT_DD) 116 full++; //DD状态 117 else if(staterr) 118 other++; //非DD状态 119 120 if(bi->dma == 0) null_dma++; 121 } 122 123 printk("[DNA] %s(): %s@%d [laps=%d][budget=%d][full=%d/other=%d][next_to_clean=%u][next_to_use=%d][#unused=%d][null_dma=%d]\n", 124 __FUNCTION__, 125 rx_ring->netdev->name, rx_ring->queue_index, 126 num_laps, budget, full, other, 127 rx_ring->next_to_clean, rx_ring->next_to_use, 128 ixgbe_desc_unused(rx_ring), null_dma); 129 } 130 131 return(!!budget); 132 }
其实,还有个很重要的函数ixgbe_alloc_rx_buffers( ),主要用来分配DMA page映射网卡的FIFO,代码如下。
void ixgbe_alloc_rx_buffers(struct ixgbe_ring *rx_ring, u16 cleaned_count) { union ixgbe_adv_rx_desc *rx_desc; struct ixgbe_rx_buffer *bi; u16 i = rx_ring->next_to_use; //接收环中下一个可使用的描述符编号, next_to_use之后是目前可以DMA映射与传输的描述符 /* nothing to do */ if (!cleaned_count) //如果需要替换的缓存单元个数为0 return; rx_desc = IXGBE_RX_DESC(rx_ring, i); //取第i个描述符 bi = &rx_ring->rx_buffer_info[i]; //取第i个缓存单元 i -= rx_ring->count; //减去count do { #ifdef CONFIG_IXGBE_DISABLE_PACKET_SPLIT //禁止包分割 if (!ixgbe_alloc_mapped_skb(rx_ring, bi)) //分配rx_buf_len即2048字节来建立流式映射 #else //默认情形,允许包分割 if (!ixgbe_alloc_mapped_page(rx_ring, bi)) //分配page来建立流式映射,使用的是高端内存 #endif break; /* 即便buffer_addrs没变,也要更新desc,因为每次硬件写回会擦除这个buffer_addrs信息 * Refresh the desc even if buffer_addrs didn‘t change * because each write-back erases 擦除 this info. */ #ifdef CONFIG_IXGBE_DISABLE_PACKET_SPLIT //禁止包分割 rx_desc->read.pkt_addr = cpu_to_le64(bi->dma); #else //默认情况下允许包分割 rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset); //设置pkt_addr #endif rx_desc++; //指向下一个接收描述符 bi++; //指向下一个接收缓存单元 i++; //指向下一个接收描述符编号 if (unlikely(!i)) { //如果下一个接收描述符编号i为0 rx_desc = IXGBE_RX_DESC(rx_ring, 0); //描述符为0 bi = rx_ring->rx_buffer_info; //缓冲单元指向缓冲区起始位置 i -= rx_ring->count; //65536减去count } /* clear the hdr_addr for the next_to_use descriptor */ rx_desc->read.hdr_addr = 0; //清除下一个描述符的hdr_addr cleaned_count--; //需要替换的缓存单元个数减一 } while (cleaned_count); i += rx_ring->count; //加上count if (rx_ring->next_to_use != i) //如果next_to_use与i不一致 ixgbe_release_rx_desc(rx_ring, i); //更新next_to_use和next_to_alloc变量 }
而pf_ring也采用了它自己的函数dna_ixgbe_alloc_rx_buffers:
#ifdef ENABLE_DNA
struct ixgbe_adapter *adapter = netdev_priv(rx_ring->netdev);
if(adapter->dna.dna_enabled) {
if(rx_ring->netdev)
dna_ixgbe_alloc_rx_buffers(rx_ring); //抛弃intel实现的方法,采用PF_RING DMA方式自己的内存分配方案
return;
}
#endif
void dna_ixgbe_alloc_rx_buffers(struct ixgbe_ring *rx_ring) { union ixgbe_adv_rx_desc *rx_desc, *shadow_rx_desc; struct ixgbe_rx_buffer *bi; u16 i; struct ixgbe_adapter *adapter = netdev_priv(rx_ring->netdev); struct ixgbe_hw *hw = &adapter->hw; u16 cache_line_size; struct ixgbe_ring *tx_ring = adapter->tx_ring[rx_ring->queue_index]; struct pfring_hooks *hook = (struct pfring_hooks*)rx_ring->netdev->pfring_ptr; mem_ring_info rx_info = {0}; mem_ring_info tx_info = {0}; int num_slots_per_page; /* Check if the memory has been already allocated */ if(rx_ring->dna.memory_allocated) return; /* nothing to do or no valid netdev defined */ if (!netdev_ring(rx_ring)) return; if (!hook) { printk("[DNA] WARNING The PF_RING module is NOT loaded.\n"); printk("[DNA] WARNING Please load it, before loading this module\n"); return; } init_waitqueue_head(&rx_ring->dna.rx_tx.rx.packet_waitqueue); cache_line_size = cpu_to_le16(IXGBE_READ_PCIE_WORD(hw, IXGBE_PCI_DEVICE_CACHE_LINE_SIZE)); cache_line_size &= 0x00FF; cache_line_size *= PCI_DEVICE_CACHE_LINE_SIZE_BYTES; if(cache_line_size == 0) cache_line_size = 64; if(unlikely(enable_debug)) printk("%s(): pci cache line size %d\n",__FUNCTION__, cache_line_size); rx_ring->dna.packet_slot_len = ALIGN(rx_ring->rx_buf_len, cache_line_size); //1600 slot长度 rx_ring->dna.packet_num_slots = rx_ring->count; //8192 slot个数 rx_ring->dna.tot_packet_memory = PAGE_SIZE << DNA_MAX_CHUNK_ORDER; //4096*32=131072 全部包内存 这个有什么用? num_slots_per_page = rx_ring->dna.tot_packet_memory / rx_ring->dna.packet_slot_len; //131072/1600=81 rx_ring->dna.num_memory_pages = (rx_ring->dna.packet_num_slots + num_slots_per_page-1) / num_slots_per_page; //(8192+81-1)/81=102 /* Packet Split disabled in DNA mode */ //if (ring_is_ps_enabled(rx_ring)) { /* data will be put in this buffer */ /* Original fuction allocate PAGE_SIZE/2 for this buffer*/ // rx_ring->dna.packet_slot_len += PAGE_SIZE/2; //} if(unlikely(enable_debug)) printk("%s(): RX dna.packet_slot_len=%d tot_packet_memory=%d num_memory_pages=%u num_slots_per_page=%d\n", __FUNCTION__, rx_ring->dna.packet_slot_len, //1600 rx_ring->dna.tot_packet_memory, //131072 rx_ring->dna.num_memory_pages, //102 num_slots_per_page); //81 for(i=0; i<rx_ring->dna.num_memory_pages; i++) { //102次 rx_ring->dna.rx_tx.rx.packet_memory[i] = //slot槽 alloc_contiguous_memory(&rx_ring->dna.tot_packet_memory, //4096*32字节 &rx_ring->dna.mem_order, //返回页数 rx_ring->q_vector->numa_node); //指定numa节点 if (rx_ring->dna.rx_tx.rx.packet_memory[i] == 0) { //如果分配失败 printk("\n\n%s() ERROR: not enough memory for RX DMA ring!!\n\n\n", __FUNCTION__); return; } if(unlikely(enable_debug)) printk("[DNA] %s(): Successfully allocated RX %u@%u bytes at 0x%08lx [slot_len=%d]\n", __FUNCTION__, rx_ring->dna.tot_packet_memory, i, rx_ring->dna.rx_tx.rx.packet_memory[i], rx_ring->dna.packet_slot_len); } if(unlikely(enable_debug)) printk("[DNA] %s(): %s@%d ptr=%p memory allocated on node %d\n", __FUNCTION__, rx_ring->netdev->name, rx_ring->queue_index, rx_ring, rx_ring->q_vector->numa_node); for(i=0; i < rx_ring->count; i++) { //8192 u_int offset, page_index; char *pkt; page_index = i / num_slots_per_page; // i/81 offset = (i % num_slots_per_page) * rx_ring->dna.packet_slot_len; pkt = (char *)(rx_ring->dna.rx_tx.rx.packet_memory[page_index] + offset); //DMA缓冲区的地址 /* if(unlikely(enable_debug)) printk("[DNA] %s(): Successfully remapped RX %u@%u bytes at 0x%08lx [slot_len=%d][page_index=%u][offset=%u]\n", __FUNCTION__, rx_ring->dna.tot_packet_memory, i, rx_ring->dna.rx_tx.rx.packet_memory[i], rx_ring->dna.packet_slot_len, page_index, offset); */ bi = &rx_ring->rx_buffer_info[i]; bi->skb = NULL; rx_desc = IXGBE_RX_DESC(rx_ring, i); if(unlikely(enable_debug)) printk("%s(): Mapping RX slot %d of %d [pktaddr=%p][rx_desc=%p][offset=%u]\n", __FUNCTION__, i, rx_ring->dna.packet_num_slots, pkt, rx_desc, offset); //为什么只是做了一次DMA流式映射呢??????????? bi->dma = pci_map_single(to_pci_dev(rx_ring->dev), pkt, //进行流式DMA映射 rx_ring->dna.packet_slot_len, //1600 PCI_DMA_BIDIRECTIONAL /* PCI_DMA_FROMDEVICE */ ); /* Packet Split disabled in DNA mode 禁止数据包分割*/ //if (!ring_is_ps_enabled(rx_ring)) { rx_desc->read.hdr_addr = 0; rx_desc->read.pkt_addr = cpu_to_le64(bi->dma); //} else { // rx_desc->read.hdr_addr = cpu_to_le64(bi->dma); // rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + rx_ring->dna.packet_slot_len); //} rx_desc->wb.upper.status_error = 0; shadow_rx_desc = IXGBE_RX_DESC(rx_ring, i + rx_ring->count); //计算影子描述符表的地址 memcpy(shadow_rx_desc, rx_desc, sizeof(union ixgbe_adv_rx_desc));//把原描述符表全部复制到影子描述表 if(unlikely(enable_debug)) { print_adv_rx_descr(rx_desc); print_adv_rx_descr(shadow_rx_desc); } ixgbe_release_rx_desc(rx_ring, i); } /* for */ /* Shadow */ rx_desc = IXGBE_RX_DESC(rx_ring, 0); /* Resetting index rx_ring->next_to_use = the last slot where the next incoming packets can be copied (tail) */ ixgbe_release_rx_desc(rx_ring, rx_ring->count-1); /* rx_ring->next_to_clean = the slot where the next incoming packet will be read (head) */ rx_ring->next_to_clean = 0; /* Register with PF_RING */ if(unlikely(enable_debug)) printk("[DNA] next_to_clean=%u/next_to_use=%u [register=%d]\n", rx_ring->next_to_clean, rx_ring->next_to_use, IXGBE_READ_REG(hw, IXGBE_RDT(rx_ring->reg_idx))); /* Allocate TX memory */ tx_ring->dna.tot_packet_memory = rx_ring->dna.tot_packet_memory; tx_ring->dna.packet_slot_len = rx_ring->dna.packet_slot_len; tx_ring->dna.packet_num_slots = tx_ring->count; tx_ring->dna.mem_order = rx_ring->dna.mem_order; tx_ring->dna.num_memory_pages = (tx_ring->dna.packet_num_slots + num_slots_per_page-1) / num_slots_per_page; dna_ixgbe_alloc_tx_buffers(tx_ring, hook); rx_info.packet_memory_num_chunks = rx_ring->dna.num_memory_pages; rx_info.packet_memory_chunk_len = rx_ring->dna.tot_packet_memory; rx_info.packet_memory_num_slots = rx_ring->dna.packet_num_slots; rx_info.packet_memory_slot_len = rx_ring->dna.packet_slot_len; rx_info.descr_packet_memory_tot_len = 2 * rx_ring->size; tx_info.packet_memory_num_chunks = tx_ring->dna.num_memory_pages; tx_info.packet_memory_chunk_len = tx_ring->dna.tot_packet_memory; tx_info.packet_memory_num_slots = tx_ring->dna.packet_num_slots; tx_info.packet_memory_slot_len = tx_ring->dna.packet_slot_len; tx_info.descr_packet_memory_tot_len = 2 * tx_ring->size; //原来如此,通过调用函数 dna_device_handler,把驱动有关信息告诉pf_ring模块 hook->ring_dna_device_handler(add_device_mapping, dna_v1, &rx_info, &tx_info, rx_ring->dna.rx_tx.rx.packet_memory, //接收包内存 rx_ring->desc, /* Packet descriptors 接收包描述符内存 */ tx_ring->dna.rx_tx.tx.packet_memory, //发送包内存 tx_ring->desc, /* Packet descriptors 发送包描述符内存 */ (void*)rx_ring->netdev->mem_start, //物理网卡内存 rx_ring->netdev->mem_end - rx_ring->netdev->mem_start, rx_ring->queue_index, /* Channel Id */ rx_ring->netdev, rx_ring->dev, /* for DMA mapping */ dna_model(hw), rx_ring->netdev->dev_addr, &rx_ring->dna.rx_tx.rx.packet_waitqueue, &rx_ring->dna.rx_tx.rx.interrupt_received, (void*)rx_ring, (void*)tx_ring, wait_packet_function_ptr, notify_function_ptr); rx_ring->dna.memory_allocated = 1; if(unlikely(enable_debug)) printk("[DNA] ixgbe: %s: Enabled DNA on queue %d [RX][size=%u][count=%d] [TX][size=%u][count=%d]\n", rx_ring->netdev->name, rx_ring->queue_index, rx_ring->size, rx_ring->count, tx_ring->size, tx_ring->count); #if 0 if(adapter->hw.mac.type != ixgbe_mac_82598EB) ixgbe_irq_disable_queues(rx_ring->q_vector->adapter, ((u64)1 << rx_ring->queue_index)); #endif }
标签:
原文地址:http://www.cnblogs.com/mylinuxer/p/4272382.html