标签:
? 大数据量 (100s TB级数据) 且有快速随机访问的需求。
? 例如淘宝的交易历史记录。数据量巨大无容置疑,面向普通用户的请求必然要即时响应。
? 容量的优雅扩展。
? 大数据的驱使,动态扩展系统容量的必须的。例如:webPage DB。
? 业务场景简单,不需要关系数据库中很多特性(例如交叉列、交叉表,事务,连接等等)。
? 优化方面:合理设计rowkey。因为hbase的查询用rowkey是最高效的,也几乎的唯一生产环境可行的方式。所以把你的查询请求转换为查询rowkey的请求吧。
hbase-0.98.8 【下载地址】
zookeeper-3.4.6 【下载地址】
sudo vi /etc/profile HBASE_HOME=/home/hadoop/source/hbase-0.98.8 ZK_HOME=/home/hadoop/source/zookeeper-3.4.6 PATH=$HBASE_HOME/bin:$ZK_HOME/bin export HBASE_HOME ZK_HOME
hbase-env.sh
export JAVA_HOME=/usr/jdk1.7
启动shell:
hbase shell
启动hbase:
start-hbase.sh
zk可以用来保证数据在zk集群之间事务性一致,如:
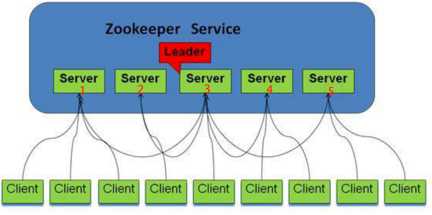
删除Server1中的数据后,其他集群的Server会自动同步删除之后的数据。
集群的规模小于等于3,各个集群的系统时间必须一致。
(1)解压zk的压缩包到指定位置。
(2)修改conf文件,cp zoo_sample.cfg zoo.cfg
(3)编辑zoo.cfg 修改dataDir=/home/zk/data 新增 server.0=hadoop0:2888:3888 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888
(4)创建文件夹 mkdir /home/zk/data 在data目录下,创建文件myid,值为0
(5)用scp命令分发zk文件夹到集群
启动zk的服务:zkServer.sh start
验证zk的启动状态:zkServer.sh status
zookeeper的集群数推荐配置奇数,Leader选举算法采用了Paxos协议,该协议的核心思想是当多数Server写成功时,则任务数据写成功,如:
由此,我们可以看出3台服务器和4台服务器的容灾能力是一样的,所以为了节约服务器资源,一般我们采用奇数个数,作为服务器部署个数。
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4221494.html