标签:
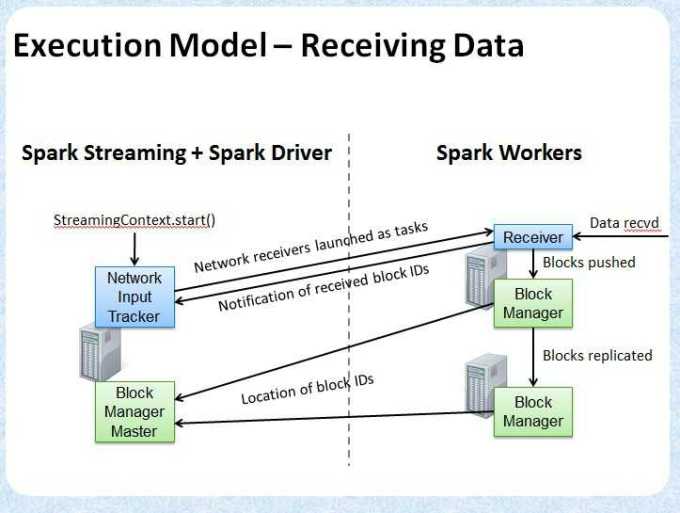
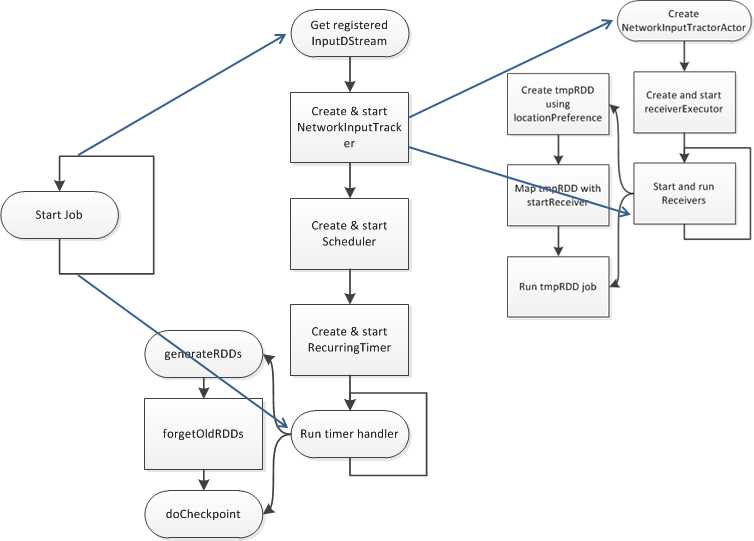
/**
* :: DeveloperApi ::
* Abstract class of a receiver that can be run on worker nodes to receive external data. A
* custom receiver can be defined by defining the functions `onStart()` and `onStop()`. `onStart()`
* should define the setup steps necessary to start receiving data,
* and `onStop()` should define the cleanup steps necessary to stop receiving data.
* Exceptions while receiving can be handled either by restarting the receiver with `restart(...)`
* or stopped completely by `stop(...)` or
*
* A custom receiver in Scala would look like this.
*
* {{{
* class MyReceiver(storageLevel: StorageLevel) extends NetworkReceiver[String](storageLevel) {
* def onStart() {
* // Setup stuff (start threads, open sockets, etc.) to start receiving data.
* // Must start new thread to receive data, as onStart() must be non-blocking.
*
* // Call store(...) in those threads to store received data into Spark‘s memory.
*
* // Call stop(...), restart(...) or reportError(...) on any thread based on how
* // different errors needs to be handled.
*
* // See corresponding method documentation for more details
* }
*
* def onStop() {
* // Cleanup stuff (stop threads, close sockets, etc.) to stop receiving data.
* }
* }
* }}}
*/
@DeveloperApi
abstract class Receiver[T](val storageLevel: StorageLevel) extends Serializable {
/**
* This method is called by the system when the receiver is started. This function
* must initialize all resources (threads, buffers, etc.) necessary for receiving data.
* This function must be non-blocking, so receiving the data must occur on a different
* thread. Received data can be stored with Spark by calling `store(data)`.
*
* If there are errors in threads started here, then following options can be done
* (i) `reportError(...)` can be called to report the error to the driver.
* The receiving of data will continue uninterrupted.
* (ii) `stop(...)` can be called to stop receiving data. This will call `onStop()` to
* clear up all resources allocated (threads, buffers, etc.) during `onStart()`.
* (iii) `restart(...)` can be called to restart the receiver. This will call `onStop()`
* immediately, and then `onStart()` after a delay.
*/
def onStart()
/**
* Store an ArrayBuffer of received data as a data block into Spark‘s memory.
* The metadata will be associated with this block of data
* for being used in the corresponding InputDStream.
*/
def store(dataBuffer: ArrayBuffer[T], metadata: Any) {
executor.pushArrayBuffer(dataBuffer, Some(metadata), None)
}
/**
* Abstract class that is responsible for supervising a Receiver in the worker.
* It provides all the necessary interfaces for handling the data received by the receiver.
*/
private[streaming] abstract class ReceiverSupervisor(
receiver: Receiver[_],
conf: SparkConf
) extends Logging {
/**
* Concrete implementation of [[org.apache.spark.streaming.receiver.ReceiverSupervisor]]
* which provides all the necessary functionality for handling the data received by
* the receiver. Specifically, it creates a [[org.apache.spark.streaming.receiver.BlockGenerator]]
* object that is used to divide the received data stream into blocks of data.
*/
private[streaming] class ReceiverSupervisorImpl(
receiver: Receiver[_],
env: SparkEnv
) extends ReceiverSupervisor(receiver, env.conf) with Logging {
private val blockManager = env.blockManager
private val storageLevel = receiver.storageLevel
/** Remote Akka actor for the ReceiverTracker */
private val trackerActor = {
val ip = env.conf.get("spark.driver.host", "localhost")
val port = env.conf.getInt("spark.driver.port", 7077)
val url = "akka.tcp://%s@%s:%s/user/ReceiverTracker".format(
SparkEnv.driverActorSystemName, ip, port)
env.actorSystem.actorSelection(url)
}
/** Timeout for Akka actor messages */
private val askTimeout = AkkaUtils.askTimeout(env.conf)
/** Akka actor for receiving messages from the ReceiverTracker in the driver */
private val actor = env.actorSystem.actorOf(
Props(new Actor {
override def preStart() {
logInfo("Registered receiver " + streamId)
val msg = RegisterReceiver(
streamId, receiver.getClass.getSimpleName, Utils.localHostName(), self)
val future = trackerActor.ask(msg)(askTimeout)
Await.result(future, askTimeout)
}
override def receive() = {
case StopReceiver =>
logInfo("Received stop signal")
stop("Stopped by driver", None)
}
def ref = self
}), "Receiver-" + streamId + "-" + System.currentTimeMillis())
/** Unique block ids if one wants to add blocks directly */
private val newBlockId = new AtomicLong(System.currentTimeMillis())
/** Divides received data records into data blocks for pushing in BlockManager. */
private val blockGenerator = new BlockGenerator(new BlockGeneratorListener {
def onError(message: String, throwable: Throwable) {
reportError(message, throwable)
}
def onPushBlock(blockId: StreamBlockId, arrayBuffer: ArrayBuffer[_]) {
pushArrayBuffer(arrayBuffer, None, Some(blockId))
}
}, streamId, env.conf)
/**
* This class manages the execution of the receivers of NetworkInputDStreams. Instance of
* this class must be created after all input streams have been added and StreamingContext.start()
* has been called because it needs the final set of input streams at the time of instantiation.
*/
private[streaming]
class ReceiverTracker(ssc: StreamingContext) extends Logging {
val receiverInputStreams = ssc.graph.getReceiverInputStreams()
val receiverInputStreamMap = Map(receiverInputStreams.map(x => (x.id, x)): _*)
val receiverExecutor = new ReceiverLauncher()
val receiverInfo = new HashMap[Int, ReceiverInfo] with SynchronizedMap[Int, ReceiverInfo]
val receivedBlockInfo = new HashMap[Int, SynchronizedQueue[ReceivedBlockInfo]]
with SynchronizedMap[Int, SynchronizedQueue[ReceivedBlockInfo]]
val timeout = AkkaUtils.askTimeout(ssc.conf)
val listenerBus = ssc.scheduler.listenerBus
// actor is created when generator starts.
// This not being null means the tracker has been started and not stopped
var actor: ActorRef = null
var currentTime: Time = null
/** Add new blocks for the given stream */
def addBlocks(receivedBlockInfo: ReceivedBlockInfo) {
getReceivedBlockInfoQueue(receivedBlockInfo.streamId) += receivedBlockInfo
logDebug("Stream " + receivedBlockInfo.streamId + " received new blocks: " +
receivedBlockInfo.blockId)
}
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def startReceivers() {
/** Event classes for JobGenerator */
private[scheduler] sealed trait JobGeneratorEvent
private[scheduler] case class GenerateJobs(time: Time) extends JobGeneratorEvent
private[scheduler] case class ClearMetadata(time: Time) extends JobGeneratorEvent
private[scheduler] case class DoCheckpoint(time: Time) extends JobGeneratorEvent
private[scheduler] case class ClearCheckpointData(time: Time) extends JobGeneratorEvent
/**
* This class generates jobs from DStreams as well as drives checkpointing and cleaning
* up DStream metadata.
*/
private[streaming]
class JobGenerator(jobScheduler: JobScheduler) extends Logging {
private val ssc = jobScheduler.ssc
private val conf = ssc.conf
private val graph = ssc.graph
val clock = {
val clockClass = ssc.sc.conf.get(
"spark.streaming.clock", "org.apache.spark.streaming.util.SystemClock")
Class.forName(clockClass).newInstance().asInstanceOf[Clock]
}
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventActor ! GenerateJobs(new Time(longTime)), "JobGenerator")
/** Generate jobs and perform checkpoint for the given `time`. */
private def generateJobs(time: Time) {
SparkEnv.set(ssc.env)
Try(graph.generateJobs(time)) match {
case Success(jobs) =>
val receivedBlockInfo = graph.getReceiverInputStreams.map { stream =>
val streamId = stream.id
val receivedBlockInfo = stream.getReceivedBlockInfo(time)
(streamId, receivedBlockInfo)
}.toMap
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfo))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventActor ! DoCheckpoint(time)
}
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap(outputStream => outputStream.generateJob(time))
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
/**
* Class representing a Spark computation. It may contain multiple Spark jobs.
*/
private[streaming]
class Job(val time: Time, func: () => _) {
var id: String = _
var result: Try[_] = null
def run() {
result = Try(func())
}
def setId(number: Int) {
id = "streaming job " + time + "." + number
}
override def toString = id
}
/** Class representing a set of Jobs
* belong to the same batch.
*/
private[streaming]
case class JobSet(
time: Time,
jobs: Seq[Job],
receivedBlockInfo: Map[Int, Array[ReceivedBlockInfo]] = Map.empty
) {
private val incompleteJobs = new HashSet[Job]()
private val submissionTime = System.currentTimeMillis() // when this jobset was submitted
private var processingStartTime = -1L // when the first job of this jobset started processing
private var processingEndTime = -1L // when the last job of this jobset finished processing
jobs.zipWithIndex.foreach { case (job, i) => job.setId(i) }
incompleteJobs ++= jobs
/**
* :: DeveloperApi ::
* Class having information on completed batches.
* @param batchTime Time of the batch
* @param submissionTime Clock time of when jobs of this batch was submitted to
* the streaming scheduler queue
* @param processingStartTime Clock time of when the first job of this batch started processing
* @param processingEndTime Clock time of when the last job of this batch finished processing
*/
@DeveloperApi
case class BatchInfo(
batchTime: Time,
receivedBlockInfo: Map[Int, Array[ReceivedBlockInfo]],
submissionTime: Long,
processingStartTime: Option[Long],
processingEndTime: Option[Long]
) {
spark streaming 3: Receiver 到 submitJobSet
标签:
原文地址:http://www.cnblogs.com/zwCHAN/p/4274814.html