标签:
引言
| server | HiveServer名称,同一台机器可以开启多个HiveServer实例 |
| hook | PRE_EXEC_HOOK、POST_EXEC_HOOK,分别表示语句执行开始之前、执行线束之后 |
| queryId | HiveServer内部语句唯一ID |
| queryStr | 具体执行语句,可根据语句复杂度计算工作负载 |
| jobName | 平台自己设置,我们仅仅考虑会转化为MR任务的语句,jobName即为MR JobName |
| preTime | 语句执行之前的时间戳 |
| postTime | 语句执行之后的时间戳 |
QueryPlan queryPlan = hookContext.getQueryPlan();
HiveConf conf = hookContext.getConf();
String queryId = queryPlan.getQueryId();
if (StringUtils.isEmpty(queryId)) {
LOGGER.warn("queryId is null or empty, return");
return;
}
LOGGER.info("queryId: " + queryId);
String queryStr = URLEncoder.encode(queryPlan.getQueryStr(),
CharEncoding.UTF_8);
if (StringUtils.isEmpty(queryStr)) {
LOGGER.warn("queryStr is null or empty, return");
return;
}
LOGGER.info("queryStr: " + queryStr);
String jobName = conf.getVar(HiveConf.ConfVars.HADOOPJOBNAME);
LOGGER.info("jobName: " + jobName);
if (StringUtils.isEmpty(jobName)) {
LOGGER.warn("jobName is null or empty, return");
return;
}
String server = conf.get("hiveserver.execute.hook.server");
if (StringUtils.isEmpty(server)) {
LOGGER.warn("server is null or empty, return");
return;
}
LOGGER.info("server: " + server);
String rest = conf.get("hiveserver.execute.hook.rest");
LOGGER.info("rest: " + rest);
if (StringUtils.isEmpty(rest)) {
LOGGER.warn("rest is null or empty, return");
return;
}
Map<String, String> params = new HashMap<String, String>();
params.put("server", server);
params.put("hook", hookContext.getHookType().toString());
params.put("queryId", queryId);
params.put("queryStr", queryStr);
params.put("jobName", jobName);
params.put("timestamp", String.valueOf(DatetimeUtil.now()));
try {
HttpClientUtil.doPost(rest, params);
} catch (Exception e) {
LOGGER.error("do post error: "
+ ExceptionUtils.getFullStackTrace(e));
}
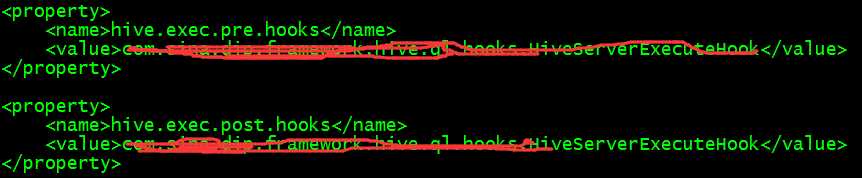
.png)
标签:
原文地址:http://www.cnblogs.com/yurunmiao/p/4275459.html