标签:
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的。如果有幸能有大牛路过,请指教如何能以效率较高的方式学习Hadoop。
我已经记不清圣经《hadoop 实战2》在我手中停留了多久,但是每一页每一章的翻过去,还是在脑壳里留下了点什么。
一段时间以来,我还是通过这本书加深以及纠正了我对于MapReduce、HDFS乃至Hadoop的新的认识。本篇主要介绍MapReduce作业的工作机制,并介绍介于Map和Reduce过程中的Shuffle和排序过程。
为响应标题,我们今天谈的MapReduce机制,切入点是一张图。先上图:
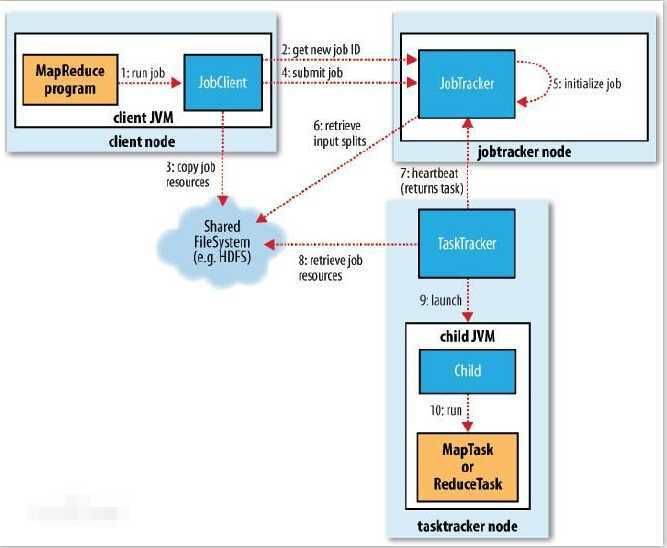
从图中不难看出,整个MapReduce分为以下流程:代码编写->作业配置->作业提交->Map任务的分配和执行->处理中间结果->Reduce任务的分配和执行->作业完成
图中:
1.运行作业
2.获取作业ID
3.复制作业资源
4.提交作业
5.初始化作业
6.获取输入分割
7.心跳通信
8.获取作业资源
9.发布
10.运行
以上过程主要涉及到的实体有客户端(用于MR代码的编写,配置作业,提交作业);TaskTracker(保持与JobTracker通信,在分配的数据片段上执行Map或Reduce任务);HDFS(保存作业的数据、配置信息、作业结果等);JobTracker(初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行)
提交作业
在提交作业前,我们需要对作业进行配置,主要包括:
(1)程序代码
(2)Map和Reduce接口
(3)输入输出路径
(4)其他配置,如InputFormat、OutputFormat等
提交作业的过程可以分为以下几步:
(1)调用JobTracker对象的getNewJobId()方法从JobTracker处获取当前作业的ID(见途中步骤2)
(2)检查作业相关路径,在运行代码时,经常遇到报错提示输出目录已存在,所以在运行代码前要确保输出目录不存在
(3)计算作业的输入划分
(4)将运行所需资源(如jar文件、配置文件、计算所得输入划分等)复制到作业对于的HDFS上(见步骤3)
(5)调用JobTracker对象的submitJob()方法来真正提交作业,通知JobTracker作业准备执行(见步骤4)
初始化作业
JobTracker在客户端调用其submitJob()方法后,会将此调用放入内部的TaskScheduler变量中,进行调度,默认调度方法为:JobQueueTaskScheduler即FIFO调度方式。
初始化作业分为如下几个步骤:
(1)从HDFS中读取作业对应的job.split(见步骤6),JobTracker从HDFS中作业对应的路径获取JobClient在步骤3中写入的job.split文件,得到输入数据的划分信息,为后面初始化过程中Map任务的分配做好准备。
(2)创建并初始化Map任务和Reduce任务。
(3)创建两个初始化Task,根据个数和输入划分已经配置的信息,并分别初始化Map和Reduce。
分配任务:
TaskTracker和JobTracker之间的通信和任务分配都是通过心跳机制完成的。TaskTracker会以一定间隔时间向JobTracker发送心跳,告诉自己是否存活,准备执行新任务;而JobTracker在接收到心跳信息后会查看是否有待分配任务,如果有,则会分配给TaskTracker。
执行任务:
当TaskTracker接收到新任务时就要开始运行任务,第一步就是将任务本地化,将任务所需的数据、配置信息、程序代码从HDFS复制到TaskTracker本地(将步骤8)。该过程主要通过localizeJob()方法来实现任务的本地化,具体包括以下几个步骤:
(1)将job.split复制到本地
(2)将job.jar复制到本地
(3)将job的配置信息写入job.xml
(4)创建本地任务目录,解压job.jar
(5)调用launchTaskForJob()方法发布任务(见步骤9)
更新任务执行进度和状态:
由MapReduce作业分割成的每个任务中都有一组计数器,他们对任务执行过程中的进度组成事件进行计数。如果任务要报告进度,它便会设置一个标志以表明状态变化将会发送到TaskTracker上,另一个监听线程检查到这标志后,会告知TaskTracker当前的任务状态。
完成作业:
所有TaskTracker任务的执行进度信息都汇总到JobTracker处,当JobTracker接收到最后一个任务的已完成通知后,便把作业的状态设置为“成功”。
Shuffle和排序:
在Map和Reduce之间有一个叫做Shuffle的过程,主要的工作是将Map的输出结果进行一定的排序和分割再交给Reduce,从某种程度上说,Shuffle过程的性能与整个MapReduce的性能直接相关。
Shuffle过程分为Map和Reduce端。Map端的Shuffle过程是对Map的结果进行划分(partition)、排序(sort)和分割(spill),然后将属于同一个划分的输出合并在一起(merge)并写在磁盘上,同时按照不同的划分将结果发送给对应的Reduce(Map输出的划分与Reduce的对应关系由JobTracker确定)。
Reduce端又会将各个Map送来的属于同一个划分的输出进行合并(merge),然后对merge的结果进行排序,最后交给Reduce处理。
对于Hadoop等大数据技术有兴趣的欢迎加群413471695交流讨论^_^
本文链接:《Hadoop阅读笔记(四)——一幅图看透MapReduce机制》
Hadoop阅读笔记(四)——一幅图看透MapReduce机制
标签:
原文地址:http://www.cnblogs.com/bigdataZJ/p/hadoopreading4.html