标签:
注:出于记录对 zookeeper 的学习研究成果目的,并分享经验,根据官方文档翻译整理而成本文,原文地址: http://zookeeper.apache.org/doc/trunk/zookeeperOver.html
ZooKeeper:一个用于分布式应用的分布式协调服务
Zookeeper 是一个分布式的、开源的协调服务,用在分布式应用程序中。它提出了一组简单的原语,分布式应用程序可以基于这些原语之上构建更高层的分布式服务用于实现同步、配置管理、分组和命名等。Zookeeper 设计的容易进行编程,它使用一种类似于文件系统的目录树结构的数据模型,以 java 方式运行,有 java 和 c 的绑定(binding)。
协调服务总所周知地难于正确实现,尤其容易产生诸如争用条件、死锁等错误。Zookeeper 背后的动机就是减轻分布式应用程序从头做起实现协调服务的难度。
设计目标
Zookeeper 是简单的,它使分布式进程可以通过一种类似于标准文件系统的共享的层次化的命名空间进行相互协调。命名空间由称为 znode 的数据记录组成,在 Zookeeper 的语义里,znode 类似于文件和目录。不同于典型的为存储而设计的文件系统,ZooKeeper 的数据是保持在内存中的,这意味着可以达到高吞吐量和低延迟。
Zookeeper 的实现着重于高性能、高可用性和严格的顺序访问。在性能方面, Zookeeper 适用于大型的分布式系统。在可靠性方面,Zookeeper 能够避免单点失效。严格顺序意味着可以在客户端实现复杂的同步原语。
Zookeeper 是复制的(replicated),就像它协调的分布式进程一样,Zookeeper 自身也在被称为“ensemble” 的一组主机之间进行复制。
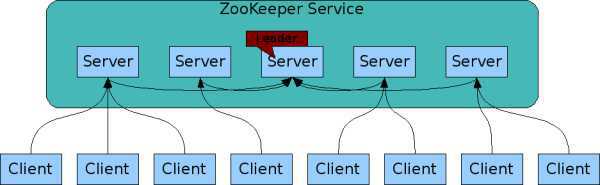
组成 Zookeeper 服务(Service)的每个服务器(server)必须相互知道对方。它们(Server)维护着一份保持在内存中的状态镜像,以及持久存储的事务日志和快照。只要这些服务器中的大多数是可用的,整个 Zookeeper 服务就是可用的。
客户端连接到单个 Zookeeper Server,维持着一个 TCP 连接,通过该连接进行发送请求,获取回复,获取监视事件,以及发送心跳。如果该TCP连接中断了,客户端将连接到另外一个服务器。
Zookeeper 是顺序的。Zookeeper 用一个数字标记每一次更新,以反映所有 Zookeeper 事务的顺序。并发的操作可以这些次序来实现更高层的抽象,比如同步原语。
Zookeeper 是快速的。在应对以“读”为主的负载时尤其地快速。Zookeeper 的应用程序运行在数以千计的计算机上,而当“读”远多于“写”,读写比达到 10 比 1 左右时,表现最好。
数据模型和层次化的命名空间
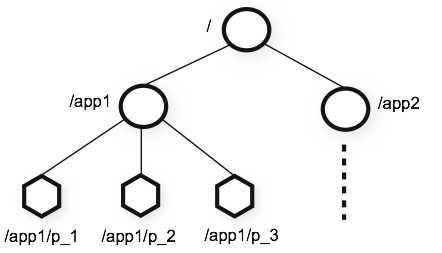
ZooKeeper 采用的命名空间很像标准的文件系统。一个名称由连续的以斜线"/"分隔的路径元素组成。命名空间中的每一个节点都通过一个路径唯一标识。
| Zookeeper 命名空间 |
 |
节点和瞬时节点(Nodes and ephemeral nodes)
与标准的文件系统不同的是,Zookeeper 命名空间中的每一个节点可以既有数据同时也有子节点。就像是有那样一种文件系统,允许一个文件同时也是一个目录。(Zookeeper 设计用于保存协调数据:状态信息、配置、地址信息等等,所以这些保存在节点中的数据通常都很小,在 Byte 到 KB 的范围。)为了更明晰一些,Zookeeper 使用“znode”这一术语来表示我们谈论的这些数据节点。
Znode 维护了一个属性结构,其中包含了表示数据改变、访问控制列表(ACL)改变的版本号、时间戳,可用于缓存校验、协调更新。每次一个 znode 的数据发生改变,版本号随之递增。当一个客户端检索数据时,同时也收到数据对应的版本号。
命名空间中的每个 znode 的数据的读写都是原子的。读取一个znode将获得其全部的数据,而写入则替换其全部的数据。每个节点有一个访问控制列表(Access Control List (ACL) )用于约束什么样的访问者可以进行哪些操作。
ZooKeeper 还有“瞬时节点”(emphemeral node)的概念。当创建瞬时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。
条件更新和监视(Conditional updates and watches)
ZooKeeper 支持“监视”(watch)的概念。客户端可以在 znode 上设置一个监视(watch)。当 znode 发生改变时,“监视”被触发同时被移除。当“监视”被触发时,客户端会收到一个描述了 znode 的变更的数据包。如果客户端和Zookeeper服务器之间的连接断开时,客户端将会收到一个本地通知。
保证(Guarantees)
Zookeeper 很快速也很简单。不过,由于它的目标是作为构建诸如“同步”这类更复杂服务的基础,它提供了一些的一组保证:
简单的API
Zookeeper 的设计目标之一就是提供简单的编程接口。于是,它只提供了以下的操作:
create : 在(命名空间)树的一个特定地址上创建一个节点。
delete : 删除一个节点。
exists : 检测在一个地址上是否存在节点。
get data : 从节点读取数据。
set data :将数据写入节点。
get children :检索子节点列表。
sync : 等待数据传播完成。
实现
Zookeeper 组件图展示了 Zookeeper 服务的高层组件。除了“Request Processor”,构成 Zookeeper 服务的所有服务器都会复制一份这些组件的拷贝。
| Zookeeper 组件 |
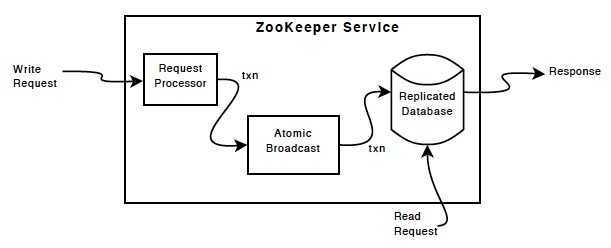 |
“Replicated Database” 是一个内存数据库,包含了整个数据树。所有更改都会记录到磁盘以便可恢复。数据写入在应用到内存数据库之前,会先序列化到磁盘。
每一个 Zookeeper 服务器都向客户端提供服务,客户端连接到一个确切的Zookeeper服务器提交请求。读请求从服务器数据库的本地拷贝中获取。改变Zookeeper服务状态的请求、写入请求通过一个一致性协议进行处理。
作为协议的一部分,客户端的所有写入请求都被转发到一个单独的服务器,该服务器被称为 leader。而其余的服务器,被称为 follower,从leader接收消息提案(proposal)并对消息的交付取得一致。消息层维护 leader 失效时的更新替换以及 leader 和 follower 之间的同步。
Zookeeper 使用自定义的原子消息协议。由于消息层是原子的,Zookeeper 可以保证本地的复制品不会不一致。当 leader 收到一个写入请求时,它计算系统所处的状态以及何时应用写入请求,并将此转换为一个事务,包含新的状态。
使用
Zookeeper 的编程接口特意地定义得很简单。然而,通过这些编程接口可以更高阶的操作,例如同步原语,成员分组,所有权,等等。
性能
Zookeeper 被设计为高性能。但实际是否如此呢?在雅虎研发中心的 Zookeeper 开发团队的研究结果表明的确如此。(参见下图:Zookeeper 吞吐量随读写比的变化)。在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致在所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
| Zookeeper 吞吐量随读写比的变化 |
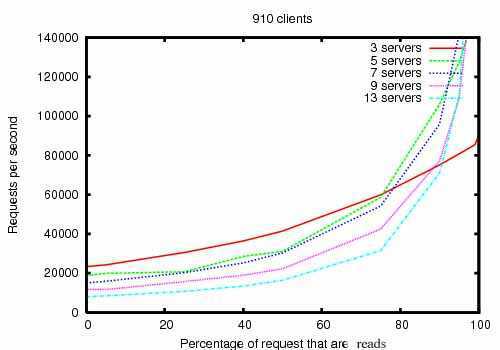 |
图“Zookeeper 吞吐量随读写比的变化” 是 Zookeeper3.2 版本运行于 Dual 2Gh Xeon + 2 个 15K RPM 的 SATA 硬盘驱动器的服务器上的结果。一个驱动器用作 Zookeeper 专用的日志设备。快照写到操作系统驱动器。写请求是 1K 数据的写入而读请求是 1K 的数据读取。“Servers”标出了 Zookeeper Ensemble 的大小,即组成 Zookeeper 服务的服务器的数量。大约30台其它的服务器被用作模拟客户端。Zookeeper Ensemble 被配置为不允许客户端连接到 Leader 。
注:3.2版本的读/写性能相对于3.1版本以前有最多达2倍的提升。
基准测试也表明了 Zookeeper 的可靠性。图“错误发生的情况下的可靠性”展示了 Zookeeper 是如何应对各种不同的失效的。图中标注的事件如下:
1、一个 Follower 失效然后恢复。
2、另一个不同的 Follower 失效然后恢复。
3、Leader 失效。
4、两个 Follower 失效然后恢复。
5、另一个 Leader 失效。
| 错误发生的情况下的可靠性(Reliability in the Presence of Errors) |
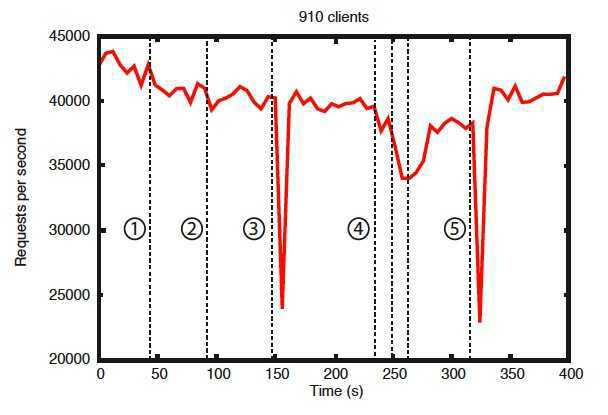 |
从这张图中可以得到几点重要的结果。首先,如果 follower 失效并快速恢复,Zookeeper 能够维持高吞吐量,尽管存在失效。但也许更重要的是,leader 选举算法使系统足够快地恢复,避免了吞吐量的总体下降。从观察结果来看,Zookeeper 花了不到 200 毫秒的时间选举出了一个新的 leader。第三,只要 follower 恢复,Zookeeper 的吞吐量能够再次上升到刚开始处理请求时的水平。
Zookeeper 已经被成功地用在许多工业级的应用。在雅虎,Zookeeper 被用作雅虎消息中间件的协调和失效恢复服务,该系统是一个高伸缩性的发布订阅系统,管理着成千上万的主题复制和数据分发。Zookeeper 还被用在雅虎爬虫的抓取服务上,用于管理失效恢复。许多雅虎的广告系统也用 Zookeeper 实现可靠的服务。
我们鼓励所有的用户和开发者都加入社区,并贡献他们的专业知识。更多详细信息请参见 Zookeeper Project on Apache。
标签:
原文地址:http://www.cnblogs.com/haiq/p/3899650.html