标签:
学了这么些天的基础知识发现自己还是个门外汗,难怪自己一直混的不怎么样。但这样的恶补不知道有没有用,是不是过段时间这些知识又忘了呢?这些知识平时的工作好像都是随拿随用的,也并不是平时一点没有关注过这些基础知识,只是用完了也就忘了。所以写笔记也是个好习惯,光看一个概念不容易记住,整理写成文那就好许多,以后查起来也方便一些。
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
- 若关键字为
,则其值存放在
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
为散列函数,按这个思想建立的表为散列表。

散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
- 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即
或
,其中
为常数(这种散列函数叫做自身函数)
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即
,
。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生碰撞。
/** * The hash table data. */ private transient Entry[] table;
再看数据链表
/** * Hashtable collision list. */ private static class Entry<K,V> implements Map.Entry<K,V> { int hash; K key; V value; Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } protected Object clone() { return new Entry<K,V>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } // Map.Entry Ops public K getKey() { return key; } public V getValue() { return value; } public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ (value==null ? 0 : value.hashCode()); } public String toString() { return key.toString()+"="+value.toString(); } }
其实还是挺简单的,就是一个Entry数组,而Entry就是一个键值关系表,同时提供了链表的功能。
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<K,V>(hash, key, value, e); count++; return null; }
看看关键代码:
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
先得到key的hashcode,再通过除留余数法得到数组索引,简单高效就得到了存储位置。
获得数据的方法就是get:
public synchronized V get(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
计算数组下标的方法是一样的,这样的定位方式特别高效,只要计算一次就可以了,当然如果有冲突的话还要遍历链表对比hash和key再确定最终的数据项。
标签:
原文地址:http://www.cnblogs.com/5207/p/4277507.html
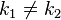 ,而
,而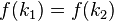 ,这种现象称为碰撞(
,这种现象称为碰撞(