标签:c style class blog code java
前言
在并发,多线程环境下,同步是一个很重要的环节。同步即是指进程/线程之间的执行顺序约定。
本文将介绍如何通过共享内存机制实现块内多线程之间的同步。
至于块之间的同步,需要使用到 global memory,代价较为高昂,目前使用的情况也不多,就先不介绍了。
块内同步函数:__syncthreads ()
线程调用此函数后,该线程所属块中的所有线程均运行到这个调用点后才会继续往下运行。
代码示例
使用同步思想优化之前一篇博文中提到的数组求和程序。在新的程序中,让每个块中的第一个线程将块中所有线程的运算结果都加起来,然后再存入到结果数组中。这样,结果数组的长度与块数相等 (原来是和总线程数相等),大大降低了 CPU 端程序求和的工作量以及需要传递进/出显存的数据 (代码下方如果出现红色波浪线无视之):

1 // 相关 CUDA 库 2 #include "cuda_runtime.h" 3 #include "cuda.h" 4 #include "device_launch_parameters.h" 5 6 // 此头文件包含 __syncthreads ()函数 7 #include "device_functions.h" 8 9 #include <iostream> 10 #include <cstdlib> 11 12 using namespace std; 13 14 const int N = 100; 15 16 // 块数 17 const int BLOCK_data = 3; 18 // 各块中的线程数 19 const int THREAD_data = 10; 20 21 // CUDA初始化函数 22 bool InitCUDA() 23 { 24 int deviceCount; 25 26 // 获取显示设备数 27 cudaGetDeviceCount (&deviceCount); 28 29 if (deviceCount == 0) 30 { 31 cout << "找不到设备" << endl; 32 return EXIT_FAILURE; 33 } 34 35 int i; 36 for (i=0; i<deviceCount; i++) 37 { 38 cudaDeviceProp prop; 39 if (cudaGetDeviceProperties(&prop,i)==cudaSuccess) // 获取设备属性 40 { 41 if (prop.major>=1) //cuda计算能力 42 { 43 break; 44 } 45 } 46 } 47 48 if (i==deviceCount) 49 { 50 cout << "找不到支持 CUDA 计算的设备" << endl; 51 return EXIT_FAILURE; 52 } 53 54 cudaSetDevice(i); // 选定使用的显示设备 55 56 return EXIT_SUCCESS; 57 } 58 59 // 此函数在主机端调用,设备端执行。 60 __global__ 61 static void Sum (int *data,int *result) 62 { 63 // 声明共享内存 (数组) 64 extern __shared__ int shared[]; 65 // 取得线程号 66 const int tid = threadIdx.x; 67 // 获得块号 68 const int bid = blockIdx.x; 69 70 shared[tid] = 0; 71 // 有点像网格计算的思路 72 for (int i=bid*THREAD_data+tid; i<N; i+=BLOCK_data*THREAD_data) 73 { 74 shared[tid] += data[i]; 75 } 76 77 // 块内线程同步函数 78 __syncthreads (); 79 80 // 每个块内索引为 0 的线程对其组内所有线程的求和结果再次求和 81 if (tid == 0) { 82 for(int i = 1; i < THREAD_data; i++) { 83 shared[0] += shared[i]; 84 } 85 // result 数组存放各个块的计算结果 86 result[bid] = shared[0]; 87 } 88 } 89 90 int main () 91 { 92 // 初始化 CUDA 编译环境 93 if (InitCUDA()) { 94 return EXIT_FAILURE; 95 } 96 cout << "成功建立 CUDA 计算环境" << endl << endl; 97 98 // 建立,初始化,打印测试数组 99 int *data = new int [N]; 100 cout << "测试矩阵: " << endl; 101 for (int i=0; i<N; i++) 102 { 103 data[i] = rand()%10; 104 cout << data[i] << " "; 105 if ((i+1)%10 == 0) cout << endl; 106 } 107 cout << endl; 108 109 int *gpudata, *result; 110 111 // 在显存中为计算对象开辟空间 112 cudaMalloc ((void**)&gpudata, sizeof(int)*N); 113 // 在显存中为结果对象开辟空间 114 cudaMalloc ((void**)&result, sizeof(int)*BLOCK_data); 115 116 // 将数组数据传输进显存 117 cudaMemcpy (gpudata, data, sizeof(int)*N, cudaMemcpyHostToDevice); 118 // 调用 kernel 函数 - 此函数可以根据显存地址以及自身的块号,线程号处理数据。 119 Sum<<<BLOCK_data,THREAD_data,THREAD_data*sizeof (int)>>> (gpudata,result); 120 121 // 在内存中为计算对象开辟空间 122 int *sumArray = new int[BLOCK_data]; 123 // 从显存获取处理的结果 124 cudaMemcpy (sumArray, result, sizeof(int)*BLOCK_data, cudaMemcpyDeviceToHost); 125 126 // 释放显存 127 cudaFree (gpudata); 128 cudaFree (result); 129 130 // 计算 GPU 每个块计算出来和的总和 131 int final_sum=0; 132 for (int i=0; i<BLOCK_data; i++) 133 { 134 final_sum += sumArray[i]; 135 } 136 137 cout << "GPU 求和结果为: " << final_sum << endl; 138 139 // 使用 CPU 对矩阵进行求和并将结果对照 140 final_sum = 0; 141 for (int i=0; i<N; i++) 142 { 143 final_sum += data[i]; 144 } 145 cout << "CPU 求和结果为: " << final_sum << endl; 146 147 getchar(); 148 149 return 0; 150 }
运行结果
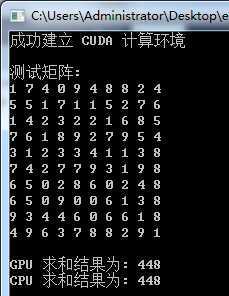
小结
共享内存,或者说这个共享数组是 CUDA 中实现同步最常用的方法。
标签:c style class blog code java
原文地址:http://www.cnblogs.com/scut-fm/p/3761399.html