标签:
【题记·碎碎念】
斯坦福这门Compilers原本放在Coursera上,当年错过档期很是可惜,后来发现他们自己的MOOC站放了一个self paced版本,真是普大喜奔,趁着放假有空学学。
这门课的分量可以很轻,亦可很重。self-paced版本如果你只是看看视频,做做quiz,那么很简单,根据课程介绍,一个星期3小时就够了;而如果你要做programming assignments,老师给“有经验的”程序员预估6-10个小时/周的工作量。其实Coursera版写的是8-10 hours/week, 10-20 hours/week with PA,个人认为Coursera估得更准确。
前两周学完,我的感受是这门课如果不做编程作业,倒不如不学。做作业的过程既痛苦又兴奋,self-pace的一个最大问题是几乎没有进度差不多的同学来一起讨论,论坛上的信息也是零零散散,而且Edx平台的论坛比Coursera的论坛体验差太多了,因此查资料时新建浏览器标签开到电脑接近崩溃是常有的事情。
花了大把时间查的资料做完这次作业对我来说就没什么用了,想想很可惜,那么还是记下来给未来同学一个参考,我相信会有一定帮助。我在做作业的时候,也许是刚开始不适应的关系,一下子接触太多新概念有点overwhelming,花了两天时间看handout和Other Project Resources里的资料,我还是不明白第一次PA要做什么、怎么做,简直无从下手。
【上面都是废话,正题此处开始】:
我直接用老师提供的虚拟机,所以没有搭环境的环节。
第一周没有PA要提交,虚拟机下的PA1目录里有些示例程序,就让你走一走一下课程所使用的Cool语言的编译、运行流程。
从第二周开始有作业,需要提交的PA1实际在~/cool/assignments/PA2或PA2J目录里,其中PA2是C++版本,PA2J是Java版。
第一次作业是做一个词法分析器,lexical analyzer, also called a scanner。这其实是一件很琐碎的工作,而核心工作很单一:定义规则把源代码tokenize掉,所以大牛们做了一些工具来方便帮助你处理琐事,你可以专心写规则。
lexical analyzer generator的元老是lex,后来在其基础上发展出flex/jlex,分别对应C++和Java,(后来貌似又来了个jflex - -,这帮大佬起名字感觉是存心要绕死你)。
我选择了Java路线,官方资料可以在这里找到,这份文档必读。
Jlex是一个辅助工具,你按照一定格式定义好规则,然后Jlex将你定义的规则转换为程序,这个自动生成的程序就是你的词法分析器,你把源代码喂给它,它就吐出一个一个的token,告诉你这个是关键字那个是标识符。
规则写在一个叫cool.lex的文本文件里,乍看上去格式很复杂,因为它居然还分四个区域,还带有各种稀奇古怪的形如%line的参数,细看其实不难,因为你的主要工作全部在"Rules"区完成,然后根据你的实现方式差异,你有可能需要在"Declarations"加上你的类/函数定义,可以在"Rules"区调用,然后在"Definitions"定义几个状态/正则别名。
所谓规则,其实就是正则表达式了,这东西如果之前从来没用过也不用怕,因为Jlex的正则语法很简单。PA2要做的事就是用正则匹配Cool程序源码里各个不同的元素,然后处理成下一阶段需要的格式。在开始做作业之前,可以看看这个例子,你将来要实现的东西差不多就长这样。
任务不难,难的是熟悉这个操作环境,还有老师给你写好的一大堆辅助类(暂时用不上几个),再加上handout有些地方实在写得语焉不详:看了两遍,只输了一条命令
make -f /usr/class/cs143/assignments/PA2J/Makefile
然后就抓瞎了,大脑直接idle了;cool.lex里的例子有注释等于没有,看不懂,一开始根本不知道怎么下手,连看资料都不知道从哪里看起。
好在有Google和Github两个神器,我直接找到了别人写好的答案……说实话,当时我有点想偷懒直接抄,反正这次PA的核心就是写一写正则表达式,原理懂了差不多得了,代码一粘一贴,分数到手,多好,但是……
嗯……满分63分只拿了9分……
好吧,还是得自己动手。
不过既然有了分数,说明它的输入输出肯定是好的,这其实才是我们新手最棘手的问题啊,ok,仔细看来:
1 <YYINITIAL>";" { return new Symbol(TokenConstants.SEMI); }
这是其中的一条规则,意思是在"YYINITIAL"这个状态下,如果遇到";"这个符号输入,那么就输出一个Symbol对象,{}保存你的处理策略。目测这个对象的constructor接受一个SEMI常量,跑到TokenConstants.java里面看了一下,这些常量都是int,形如
public static final int MULT = 27;
知道这个就很好办了,其他的规则都照葫芦画瓢,无非正则表达式复杂一点,有些情况换个类,加个参数。
在给Jlex的特别说明里(handout page 6)他写了,(编号是我加的):
1) The value returned by the
method CoolLexer.next token is an object of class java cup.runtime.Symbol. This object has
a field representing the syntactic category of a token. The syntactic codes for all tokens are defined in the file TokenConstants.java.
2) The component,
the semantic value or lexeme (if any), is also placed in a java cup.runtime.Symbol object
3) class identifiers, object identifiers, integers, and strings, the semantic value should be of type AbstractSymbol
(注意AbstractSymbol是个抽象类,你将来要用它的子类:IdSymbol, IntSymbol, StringSymbol,class identifiers, object identifiers要用IdSymbol,integer用IntSymbol,string用StringSymbol。文档在这里。
)
其实就是告诉你,像上面那个例子一样,你的规则匹配中之后,要return一个Symbol对象,这个Symbol包含一个field代表你匹配中的token的分类或名字id,都在TokenConstants.java里定义好了,去找就是;另外一个field是semantic value,也要用Symbol来表示,但是对于3)里的这些token,semantic value要用AbstractSymbol类。注意Symbol和AbstractSymbol没有关系,甚至不在同一个包里,看文档就知道了。现在这些东西的关系不是很清楚无所谓,但再往后PA3等可能就要用到。
这一大段估计可以把人绕晕。反正我在搜到那个9分答案之前完全不理解它想说什么,代码其实很简单,如果token类型是identifier,那么就这样:
IdSymbol dummy = new IdSymbol(yytext(), yytext().length(), 0); return new Symbol(TokenConstants.TYPEID, dummy);
也有这样做的(换一种Symbol类型,类似的套路)
IntTable table = new IntTable(); return new Symbol(TokenConstants.INT_CONST, table.addString(yytext()));
理由是IntTable.addString返回值就是一个IntSymbol。这些table在lexical analysis阶段暂时不用,所以可以弄些dummy值,constructor缺什么就给它喂什么,简单粗暴。
对了,状态有必要多说一句。在"directives"区域,你可以定义状态。语法如
%state COMMENT
进入注释以后,你就使用yybegin(COMMENT)进行状态转换,转换完之后可以用
<COMMENT>... {...}
这样的方式使用状态,表示在这种状态下才匹配这条规则,出注释切记要用yybegin(YYINITIAL)把状态转回来。另外在一条规则里,状态不是必须的,可以忽略,相当于任意状态都适用此规则。
YYINITIAL是Jlex隐含定义的常量,如果在lexer的整个运行过程中你没有进行过状态转换,那么全程都处于YYINITIAL状态下,详见Jlex文档第2.2.5节。
对了还有,yytext()表示被当前规则匹配中的、预处理过的文本,可以用简单粗暴的方式查看...
System.err.println("processing: "+yytext());
这些例子举出来,这个作业可以被视为完成一半了,剩下的就是对照Cool_manual一个一个写规则。哪个TokenConstants对应哪个符号,我没有找到文档,你要是找到了请告诉我,不过从名字看并不难对应,查查字典多试一试吧。
当然有一些正则还是得花点时间动点脑筋的,必要的时候还需要写辅助类来处理字符串。
我在backslash上花费了较多时间,最后才通过的测试是"weirdcharcomment.cool",corner case无穷尽呐,更多的时候是按住葫芦起了瓢。
另外这个PDF可能会给一些启发。
最后晒一下分
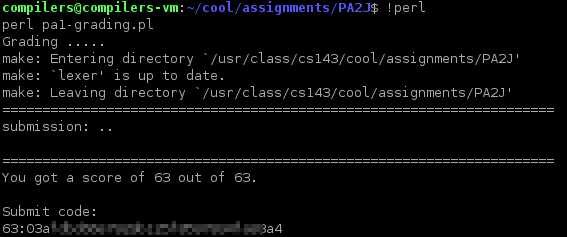
以后将继续学习继续写notes。
渣板式凑合看,如有错漏请指正,欢迎讨论。
Stanford CS1 Compilers PA2J notes
标签:
原文地址:http://www.cnblogs.com/kkzxak47/p/4288753.html