标签:
Paper:V. Vineet, P. J. Narayanan. CUDA cuts: Fast graph cuts on the GPU. In Proc. CVPR Workshop, 2008.
原文出处:
http://lincccc.blogspot.tw/2011/03/cuda-cuts-fast-graph-cuts-on-gpu_03.html
问题概述:Graph cut是一种十分有用和流行的能量优化算法,在计算机视觉领域普遍应用于前背景分割(Image segmentation)、立体视觉(stereo vision)、抠图(Image matting)等。但在获得不错效果的同时,Max-flow / Min-cost问题求解的时间代价却很大。本文作者称其所知最佳的Graph cut实现求解一张640×480的图至少需100毫秒(平均数据会差得多),无法满足实时应用的需求。但事实上,Max-flow求解中经典的Push-relabel算法在流的计算和维护上只与局部相关,具有潜在的可并行性,适于GPU加速。因此,作者实现了push-relabel算法的GPU版。作者称其算法于一张640×480的图平均每秒可以求解150次Graph cut(Nvidia 8800 GTX),也就是约6.7毫秒速,是传统CPU算法约30-40倍速。作者还提供源码的下载,点我。
Definition & Notation:
对于一个图 G = (V, E) ,其中 V 为节点集合,包括源点 s 和终点 t (也可以定义多个端点,其可以优化为双顶点图)、以及其他诸多中间节点集合 V’ ,E 为连接这些节点的边,每条边附有容量 c(u, v) 代表节点 u 通过这条边流向节点 v 所能承受的最大流量,在具体应用中边的容量通常等价于其能量值。Graph cut的目的在于找到图的Min-cut,Cut将 V’ 分割为两个部分,去掉这些边将使舍得图中的任意一个节点只与 s 或 t 相连通(如下图),而Min-cut是所有cut中边的能量值总和最小的一个。
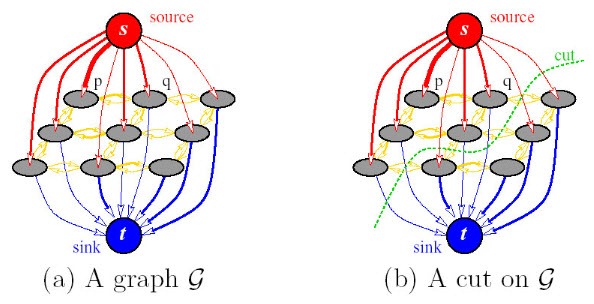
算法上要直接找Min-cut是十分困难的,通常要将问题转化为与之等价的Max-flow问题(理论推导点我)。Graph cut具体应用的性能关键在于能量函数的定义,用于计算机视觉中的一种常见能量函数定义如下:
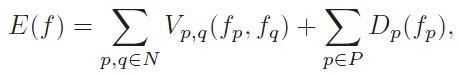
Dp 定义数据能量,Vp, q 定义平滑度能量,N 定义相邻关系,fp 为像素 p 的标签(属于 s 或 t )。
经典Push-relabel算法:
求解Max-flow有两种经典的算法:Ford-Fulkerson和Push-relabel算法。Ford-Fulkerson算法的大意是在图中不断寻找 s 和 t 之间可用路径,记入总流量,并维护一张残余网络(Residual graph),直到再也找不到可用路径为止,此时的总流量就是Max-flow(具体算法点我)。Ford-Fulkerson算法的串行性很大,因为可用路径的查找是全局性的,这是GPU所不擅长的。
Push-relabel算法,相对的,具有很强的局部性和可并行性,在每一个子操作中指关心节点及其相邻节点。Push-relabel的基本思路是将尽可能多的流量从 s 推向 t ,但是当 t 已经无法再接受更多的流量时,这些流量将会被反推回 s,最终达到平衡(和Ford-Fulkerson算法一样,再也找不到 s 到 t 的可用路径)。算法过程中的“流”称为Preflow(先流),它并不像Ford-Fulkerson算法过程中的流一样总是持续升高直至Max-flow,而是初始预测一个值,在不断趋近于Max-flow,过程中可能出现回流的现象。Preflow对每一个节点满足 e(u) = in(u) – out(u),且 e(u) ≥ 0。当 e(u) > 0 时,节点 u 溢出(overflowing)。溢出的节点需要将多余的流量Push向其相邻的节点,即Push操作。当一条从 s 到 t 的路径上所有的节点都不溢出时,此路径上的Preflow就变成真正的Flow了。
Push-relabel算法和Ford-Fulkerson算法一样都会维护一张残余网络。对于图中的每一个节点 u,若在残余网络中存在 e(u, v),则 h(u) ≤ h(v) + 1。Push操作只能在 h(u) > h(v) ,u 节点溢出且 e(u, v) 残留容量时进行;而当 u 节点溢出,且与之相邻所有残留边节点的 h(v) ≥ h(u) 时,只能进行Label操作,增加节点 u 的高度,即 h(u) += 1。在初始化时,h(s) = n,t 及其他所有节点的高度均为 0;从 s 出发的所有边初始化 f(e) = c(e),其余边 f(e) =0。Push-relabel算法将不断重复Push和Label操作,直至任意操作都无法进行。
(更详细的算法步骤推荐查阅Tutorial,点我)
比较形象点,Push-relabel是泛滥的洪水,奔腾向前,堵了就倒流;Ford-Fulkerson则是很温吞的做法,先找个人探路,回来报告能流多少水就开闸放多少。
Push-relabel算法的GPU版:
存储和线程结构:
Grid拥有和输入图片一样的维度,并被分为若干个Block,每个Block的维度为 B×B。每个线程对应一个节点(像素),即每个Block对应 B×B 个节点、需要访问 (B+2)×(B+2) 个节点的数据。每个节点包含以下数据:溢出量 e(u),高度 h(u),活跃状态 flag(u) 以及与其相邻节点间的边的容量。活跃状态共3种:Active,e(u) > 0 且 h(u) = h(v) + 1;Passive,e(u) > 0 且 h(u) ≠ h(v) + 1,这种状态在Relabel后可能变成Active;Inactive,没有溢出且没有相邻残留边,
这些数据存储在全局或设备内存中,被所有线程共享。
(GPU架构及Cuda指南参考NVidia相关手册,点我)
本文作者通过4个Kernel实现GPU版Push-relabel算法:
1) Push Kernel (node u):
|
■ |
将 h(u) 和 e(u) 从全局内存读入到Block共享内存中(使用共享内存是因为一些数据会被相邻线程共享,这种读入方式相对单独的读入更节省时间); |
|
■ |
同步线程(使用共享内存都需要做这一步,为了保证所有内存都被完全读入了); |
|
■ |
将 e(u) 按照Push规则推向相邻节点(不大于边的剩余容量,且 h(u) ≥ h(v) ); |
|
■ |
将以上Preflow记入一个特殊的全局数组 F。 |
之所以记入 F,而不直接写入相邻节点,是因为在并行Push操作时,一个节点的溢出值同时受到多个相邻节点的影响,如果直接写入,可能造成数据的不一致性(Read-after-write data consistency)。因此,作者将原来的Push操作分成了Push和Pull两个Kernel执行(另一种选择是在同一个Kernel中分两部分执行,之间进行一次同步,但是对于Block边缘的节点,这种同步需要等待其他Block的线程,这种Block间的同步并不被所有GPU支持)。
2) Pull Kernel (node u):
|
■ |
读入 F 中推向 u 的Preflow; |
|
■ |
累加所有新的Preflow,得到最终的溢出值,记入 e(u) 到全局内存。 |
3) Local Relabel Kernal (node u):
按照经典Push-relabel算法中的Relabel操作,局部地调整节点的高度
|
■ |
将 h(u) 和 flag(u) 从全局内存读入到Block共享内存中; |
|
■ |
同步线程; |
|
■ |
计算 u 相邻 active / passive 节点的最小高度; |
|
■ |
该最小高度+1,作为新高度写入 h(u) 到全局内存。 |
4) Global Relabel Kernal:
从终点 t 开始,按照广度优先策略,遍历所有节点,更新其高度至正确的距离(节点的高度总是其与终点距离的下限)。迭代次数 k 被记录与全局内存中。
|
■ |
如果 k == 1,所有与 t 相邻且有残留边的节点高度被设为 1; |
|
■ |
所有未被设置的节点检查其相邻节点,若其相邻节点的高度为 k,则设置该节点高度为 k+1; |
|
■ |
更新高度值到全局内存。 |
算法总体流程:
a. 计算能量矩阵 → b. Push+Pull Kernel循环 → c. Local Relabel Kernel循环 → d. Global Relabel Kernel循环 → e. 重复b到d至收敛(没有可进行的Push和Relabel操作)
作者还基于GPU实现了Dynamic graph cut,应用于连续细微变化的Graph cut,通过对前一帧的简单修改形成新图,重用其他数据,加速Max-flow的求解。作者的实验数据称GPU实现可以提速70-100倍。不过具体应用具体分析,提速肯定是有的,多少未知,要待我实现过试验过。据说这个印度人提供的代码Bug颇多,虽然不太信,但还是先做了要重新实现的准备。末了,吐个槽,这论文贡献不大,确实只是发Workshop的水平。
[论文笔记] CUDA Cuts: Fast Graph Cuts on the GPU
标签:
原文地址:http://www.cnblogs.com/wangyaning/p/4293396.html