标签:
NSQ是一个实时的分布式消息平台。它的设计目标是为在多台计算机上运行的松散服务提供一个现代化的基础设施骨架。这篇文章介绍了 基于go语言的NSQ的内部架构,它能够为高吞吐量的网络服务器带来 性能的优化,稳定性和鲁棒性。可以说, 如果不是因为我们在bitly使用go语言,NSQ就不会存在。这里既会讲NSQ的功能也会涉及语言提供的特征。当然,语言会影响思维,这次也不例外。现在回想起来,选择使用go语言已经收到了十倍的回报。由语言带来的兴奋和社区的积极反馈为这个项目提供了极大的帮助。
NSQ是由3个进程组成的:
nsqd是一个接收、排队、然后转发消息到客户端的进程。
nsqlookupd 管理拓扑信息并提供最终一致性的发现服务。
nsqadmin用于实时查看集群的统计数据(并且执行各种各样的管理任务)。
NSQ中的数据流模型是由streams和consumers组成的tree。topic是一种独特的stream。channel是一个订阅了给定topic的consumers 逻辑分组。
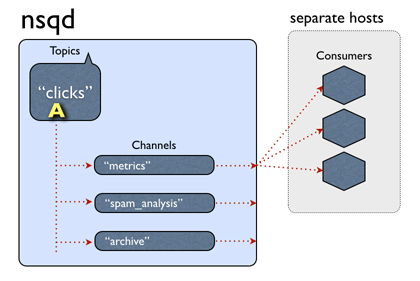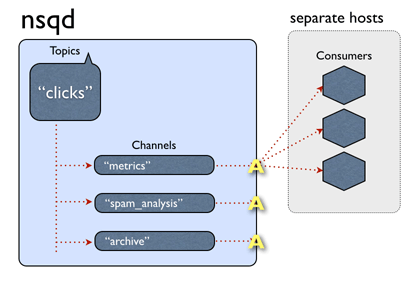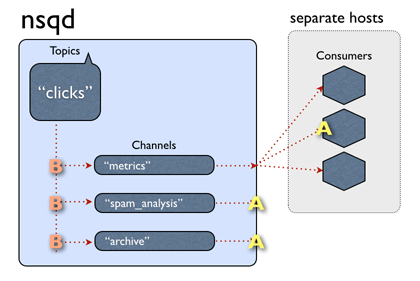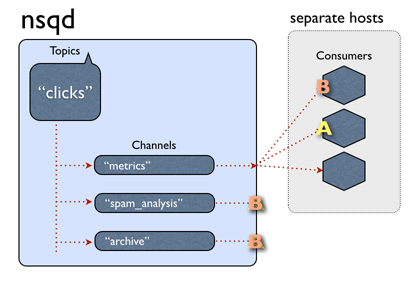
单个nsqd可以有多个topic,每个topic可以有多个channel。channel接收这个topic所有消息的副本,从而实现多播分发,而channel上的每个消息被分发给它的订阅者,从而实现负载均衡。这些基本成员组成了一个可以表示各种简单和复杂拓扑结构的强大框架。有关NSQ的设计的更多信息请参见设计文档。
Topics 和 channels,是NSQ的核心成员,它们是如何使用go语言的特点来设计系统的最好示例。Go的channels(为防止歧义,以下简称为“go-chan”)是表达队列的一种自然方式,因此一个NSQ的topic/channel,其核心就是一个存放消息指针的go-chan缓冲区。缓冲区的大小由 --mem-queue-size 配置参数确定。
读取数据后,向topic发布消息的行为包括:
实例化消息结构 (并分配消息体的字节数组)
read-lock 并获得 Topic
read-lock 并检查是否可以发布
发送到go-chan缓冲区
为了从一个topic和它的channels获得消息,topic不能按典型的方式用go-chan来接收,因为多个goroutines在一个go-chan上接收将会分发消息,而期望的结果是把每个消息复制到所有channel(goroutine)中。此外,每个topic维护3个主要goroutine。第一个叫做 router,负责从传入的go-chan中读取新发布的消息,并存储到一个队列里(内存或硬盘)。
第二个,称为 messagePump, 它负责复制和推送消息到如上所述的channel中。
第三个负责 DiskQueue IO,将在后面讨论。
Channels稍微有点复杂,它的根本目的是向外暴露一个单输入单输出的go-chan(事实上从抽象的角度来说,消息可能存在内存里或硬盘上);

另外,每一个channel维护2个时间优先级队列,用于延时和消息超时的处理(并有2个伴随goroutine来监视它们)。并行化的改善是通过管理每个channel的数据结构来实现,而不是依靠go运行时的全局定时器。
注意:在内部,go运行时使用一个优先级队列和goroutine来管理定时器。它为整个time包(但不局限于)提供了支持。它通常不需要用户来管理时间优先级队列,但一定要记住,它是一个有锁的数据结构,有可能会影响 GOMAXPROCS>1 的性能。请参阅runtime/time.goc。
NSQ的一个设计目标是绑定内存中的消息数目。它是通过DiskQueue(它拥有前面提到的的topic或channel的第三个goroutine)透明的把消息写入到磁盘上来实现的。
由于内存队列只是一个go-chan,没必要先把消息放到内存里,如果可能的话,退回到磁盘上:
|
1
2
3
4
5
6
7
8
9
10
|
for msg := range c.incomingMsgChan { select { case c.memoryMsgChan <- msg: default: err := WriteMessageToBackend(&msgBuf, msg, c.backend) if err != nil { // ... handle errors ... } } } |
利用go语言的select语句,只需要几行代码就可以实现这个功能:上面的default分支只有在memoryMsgChan 满的情况下才会执行。
NSQ也有临时channel的概念。临时channel会丢弃溢出的消息(而不是写入到磁盘),当没有客户订阅后它就会消失。这是一个Go接口的完美用例。Topics和channels有一个的结构成员被声明为Backend接口,而不是一个具体的类型。一般的 topics和channels使用DiskQueue,而临时channel则使用了实现Backend接口的DummyBackendQueue。
在任何带有垃圾回收的环境里,你都会多多少少感受到吞吐量(工作有效性)、延迟(响应能力)、驻留集大小(内存使用量)的压力。就 Go 1.2 而言,垃圾回收有标记-清除(并发的)、不再生、不紧凑、阻止一切运行、大体精准的特点。大体精准是因为剩下的工作没有及时的完成(这是 Go 1.3 的计划)。Go 的垃圾回收机制当然会持续改进,但普遍的真理是:创建的垃圾越少,回收垃圾的时间越少。
首先,理解垃圾回收是如何在实际的工作负载中运行的是非常重要的。为此,nsqd 以 statsd 的格式 (与其它内部指标一起) 发布垃圾回收的统计信息。nsqadmin 显示这些指标的图表,可以让你深入了解它在频率和持续时间两方面产生的影响:
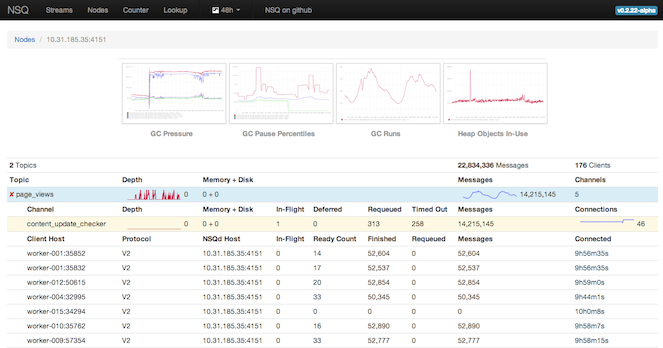
为了减少垃圾,你需要知道它们是在哪生成的。再次回到Go的工具链,它提供的答案如下:
使用testing包和go test -benchmen来基准测试热点代码路径。它配置了每个迭代分配的数字(基准的运行可与benchcmp进行比较)。
使用 go build -gcflags -m 创建,将会输出逃逸分析的结果。
除此之外,它还提供了nsqd 的如下优化:
避免把[]byte 转化为字符串类型.
预分配切片(特别是make的能力)并总是知晓链中各个条目的数量和大小。
提供各种配置面板(如消息大小)的限制。
避免封装(如使用interface{})或者不必要的包装类(例如 用一struct给一个多值的go-chan).
在热代码路径(它指定的)中避免使用defer。
TCP 协议
NSQ的TCP协议是一个闪亮的会话典范,在这个会话中垃圾回收优化的理论发挥了极大的效用。
协议的结构是一个有很长的前缀框架,这使得协议更直接,易于编码和解码。
|
1
2
3
4
5
|
[x][x][x][x][x][x][x][x][x][x][x][x]... | (int32) || (int32) || (binary) | 4-byte || 4-byte || N-byte ------------------------------------... size frame ID data |
因为框架的组成部分的确切类型和大小是提前知道的,所以我们可以规避了使用方便的编码二进制包的Read()和Write()封装(及它们外部接口的查找和会话)反之我们使用直接调用 binary.BigEndian方法。
为了消除socket 输入输出的系统调用,客户端net.Conn被封装了bufio.Reader和bufio.Writer。这个Reader通过暴露ReadSlice(),复用了它自己的缓冲区。这样几乎消除了读完socket时的分配,这极大的降低了垃圾回收的压力。这可能是因为与数据相关的大多数命令并没有逃逸(在边缘情况下这是假的,数据被强制复制)。
在更低层,MessageID 被定义为 [16]byte,这样可以将其作为 map 的 key(slice 无法用作 map 的 key)。然而,考虑到从 socket 读取的数据被保存为 []byte,胜于通过分配字符串类型的 key 来产生垃圾,并且为了避免从 slice 到 MessageID 的支撑数组产生复制操作,unsafe 包被用来将 slice 直接转换为 MessageID:
|
1
|
id := *(*nsq.MessageID)(unsafe.Pointer(&msgID)) |
注意: 这是个技巧。如果编译器对此已经做了优化,或者 Issue 3512 被打开可能会解决这个问题,那就不需要它了。issue 5376 也值得通读,它讲述了在无须分配和拷贝时,和 string 类型可被接收的地方,可以交换使用的“类常量”的 byte 类型。
类似的,Go 标准库仅仅在 string 上提供了数值转换方法。为了避免 string 的分配,nsqd 使用了 惯用的十进制转换方法,用于对 []byte 直接操作。
这些看起来像是微优化,但 TCP 协议包含了一些最热的代码执行路径。总体来说,以每秒数万消息的速度来说,它们对分配和系统开销的数量有着显著的影响:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
benchmark old ns/op new ns/op delta BenchmarkProtocolV2Data 3575 1963 -45.09% benchmark old ns/op new ns/op delta BenchmarkProtocolV2Sub256 57964 14568 -74.87% BenchmarkProtocolV2Sub512 58212 16193 -72.18% BenchmarkProtocolV2Sub1k 58549 19490 -66.71% BenchmarkProtocolV2Sub2k 63430 27840 -56.11% benchmark old allocs new allocs delta BenchmarkProtocolV2Sub256 56 39 -30.36% BenchmarkProtocolV2Sub512 56 39 -30.36% BenchmarkProtocolV2Sub1k 56 39 -30.36% BenchmarkProtocolV2Sub2k 58 42 -27.59% |
NSQ的HTTP API是基于 Go‘s net/http 包实现的. 就是 常见的HTTP应用,在大多数高级编程语言中都能直接使用而无需额外的三方包。 简洁就是它最有力的武器,Go的 HTTP tool-chest最强大的就是其调试功能. net/http/pprof 包直接集成了HTTP server,可以方便的访问CPU, heap, goroutine, and OS 进程文档 .gotool就能直接实现上述操作:
|
1
|
$ go tool pprof http://127.0.0.1:4151/debug/pprof/profile |
这对于调试和实时监控进程非常有用!
此外,/stats端端返回JSON或是美观的文本格式信息,这让管理员使用命令行实时监控非常容易:
|
1
|
|
打印出的结果如下:
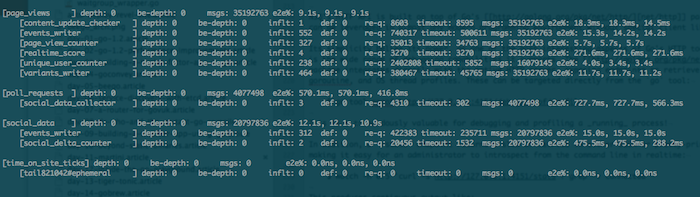
此外, Go 1.2 还有很多监控指标measurable HTTP performance gains. 每次更新Go版本后都能看到性能方面的改进,真是让人振奋!
源于其它生态系统,使用GO(理论匮乏)语言的依赖管理还得花点时间去适应
NSQ 就并不是单一的整个 repo库, 通过 _relative imports_ 而无需区别内部的包资源, 最终产生结构化的依赖管理。
主流的观点有以下两个:
Vendoring:拷贝应用需要的正确版本号到本地仓库并修改import 路径到本地库地址
Virtual Env: 列出构建是需要的版本信息,创建包含相关信息的GOPATH环境变量
Note: 这仅仅应用于二级制包,对于可导入的包版本不起作用
NSQ使用 godep提供 (2) 中的实现.
它的实现原理是复制依赖关系到 Godeps文件中, 之后生成GOPATH环境变量。构建时,它使用Go环境中的工具链 来完成工作。 Godeps就是json格式,可以手动修改。
它还支持go的get. 例如,构建一个 NSQ版本:
|
1
|
$ godep get github.com/bitly/nsq/... |
Go语言提供了内置的测试和基线。由于其简单的并发操作建模,在测试环境里加入nsqd 实例轻而易举。但是,在测试初始化的时候会有个问题:全局状态。最明显的就是引用运行态nsqd 实例的全局变量 i.e.var nsqd *NSQd.
于是某些测试就无可避免的使用局部变量去保存该值i.e.nsqd := NewNSQd(...).这也就意味着全局状态并未指向运行态的值,使测试失去了意义。
应对这个问题,Context结构体被引入以保存配置项metadata和实时nsqd的父类。所有全局状态的子引用都通过访问该Context来安全的获取相应值(主题,渠道,协议处理等等),这样测试起来也更有保障。
一个系统,如果在面对变幻的网络环境和不可预知的事件时不具备可靠性,将不会是一个表现良好的分布式生产环境。NSQ的设计和实现方式,使它能容忍错误并以一种始终如一的,可预期的和稳定的方式来运行。它的首要的设计哲学是快速失败,认为错误都是致命的,并提供一种方式来调试遇到的任何问题。不过,为了能有所行动,你必须要能够检测异常环境...
为了确保进程的正常工作,所有的网络IO都会依据心跳检测的间隔时间来设置边界.这意味着你甚至可以断开客户端和 nsqd 的网络连接,而不必担心问题被发现并恰当的处理。一旦发现致命错误,客户连接将被强关。发送中的消息超时并从新加入新的客户端接受队列。最后,错误日志会被保存并增加内部评价矩阵内容。
启用goroutines很简单,但后续工作却不是那么容易弄好的。避免出现死锁是一个挑战。通常都是因为在排序上出了问题,goroutine可能在接到上游的消息前就收到了go-chan的退出信号。为啥提到这个?简单,一个未正确处理的goroutine就是内存泄露。更深入的分析,nsqd 进程含有多个激活的goroutines。从内部情况来看,消息的所有权是不停在变得。为了能正确的关掉goroutines,实时统计所有的进程信息是非常重要的。虽没有什么神奇的方法,但下面的几点能让工作简单一点...
sync 包提供了 sync.WaitGroup, 它可以计算出激活态的goroutines数(比提供退出的平均等待时间)
为了使代码简洁nsqd 使用如下wrapper:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type WaitGroupWrapper struct { sync.WaitGroup } func (w *WaitGroupWrapper) Wrap(cb func()) { w.Add(1) go func() { cb() w.Done() }() } // can be used as follows: wg := WaitGroupWrapper{} wg.Wrap(func() { n.idPump() }) // ... wg.Wait() |
在含有多个子goroutines中触发事件最简单的办法就是用一个go-chan,并在完成后关闭。所有当中暂停的动作将被激活,这就无需再向每个goroutine发送相关的信号了
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type WaitGroupWrapper struct { sync.WaitGroup } func (w *WaitGroupWrapper) Wrap(cb func()) { w.Add(1) go func() { cb() w.Done() }() } // can be used as follows: wg := WaitGroupWrapper{} wg.Wrap(func() { n.idPump() }) // ... wg.Wait() |
想可靠的,无死锁,所有路径都保有信息的实现是很难的。下面是一些提示:
理想情况下,在go-chan发送消息的goroutine也应为关闭消息负责.
如果消息需要保留,确保相关go-chans被清空(尤其是无缓冲的!),以保证发送者可以继续进程.
另外,如果消息不再是相关的,在单个go-chan上的进程应该转换到包含推出信号的select上 (如上所述)以保证发送者可以继续进程.
一般的顺序应该是:
停止接受新的连接(停止监听)
向goroutines发出退出信号(见上文)
等待WaitGroup的goroutine中退出(见上文)
恢复缓冲数据
剩下的部分保存到磁盘
最后,最重要的工作是记录你的Go例程的入口和出口日志!这使得它更容易识别死锁或泄漏的情况。nsqd日志行包括信息Go例程与他们的兄弟姐妹(和父母),如客户端的远程地址或主题/渠道名。日志是冗长的,但还不至于到接受不了的程度。这个是有两面性的,但nsqd倾斜当故障发生时向日志中放入更多的信息,,而不是为了避免繁琐而降低日志定位问题的有效性。
原文地址: http://www.oschina.net/translate/day-22-a-journey-into-nsq
相关文章:
标签:
原文地址:http://www.cnblogs.com/shanyou/p/4296181.html