标签:
1、HDFS简介
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集合的应用带来了很多便利。
Hadoop整合了众多文件系统,在其中有一个综合性的文件系统抽象,它提供了文件系统实现的各类接口,HDFS只是这个抽象文件系统的一个实例。Hadoop提供了一个高层的文件系统抽象类org.apache.hadoop.fs.FileSystem,这个抽象类展示了一个分布式文件系统,并有几个具体的实现,如表1-1所示。
表1-1 Hadoop文件系统
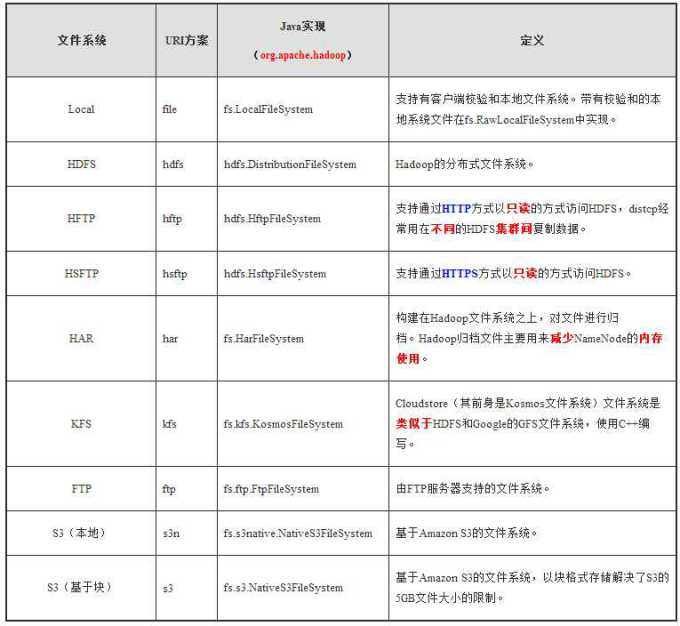
Hadoop提供了许多文件系统的接口,用户可以使用URI方案选取合适的文件系统实现交互。
2、HDFS基础概念
2.1 数据库(block)
2.2 NameNode和DataNode
HDFS体系结构中有两类节点,一类是NameNode,又叫“元数据节点”;另一类是DataNode,又叫“数据节点”。这两类节点分别是承担Master和Worker具体任务的执行节点。
1)元数据节点用来管理文件系统的命名空间
2)数据节点是文件系统中真正存储数据的地方
3)从元数据节点(secondary namenode)
2.3 元数据节点目录结构
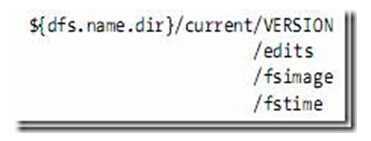
VERSION文件是java properties文件,保存了HDFS的版本号。

2.4 数据节点的目录结构
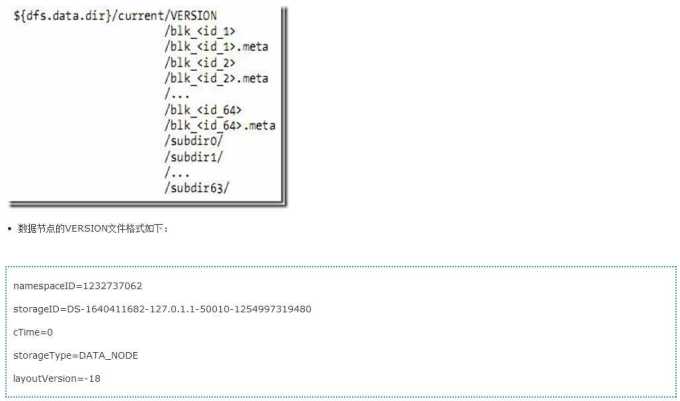
2.5 文件系统命名空间映像文件及修改日志
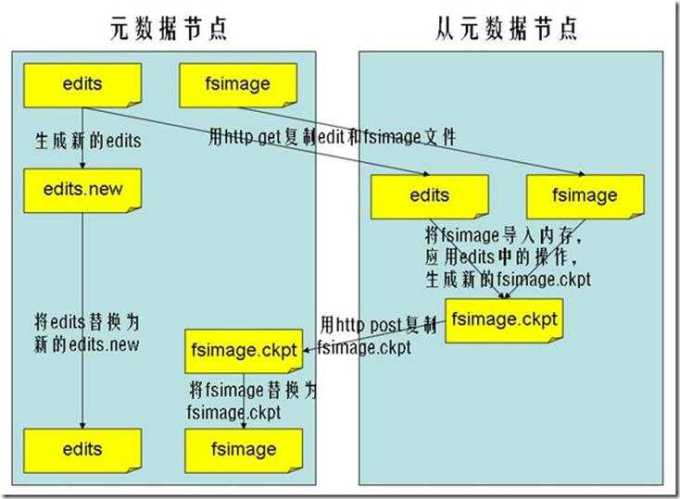
3、HDFS体系结构
HDFS是一个主/从(Master/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update、Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
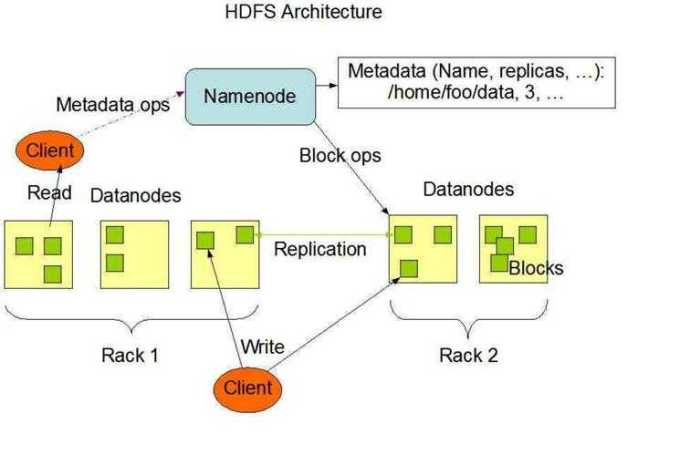
图3-1 Hadoop的体系结构
1)NameNode、DataNode和Client
2)文件写入
3)文件读取
HDFS典型的部署是在一个专门的机器上运行的NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。
4、HDFS的优缺点
4.1 HDFS的优点
1)处理超大文件
这里的超大文件通常是指百MB、甚至数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。
2)流式的访问数据
HDFS的设计建立在更多地响应“一次写入、多次读写”任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。
3)运行于廉价的商用机器集群上
Hadoop设计对硬件需求比较低,只须要运行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。廉价的商用机器也就意味着大型集群中出现节点故障情况的概率非常高。这就要求设计HDFS时要充分考虑数据的可靠性、安全性及高可用性。
4.2 Hadoop的缺点
1)不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:对于那些有低延迟要求的应用程序,HBase是一个更好的选择。通过上层数据管理项目来尽可能地补充这个不足。在性能上有了很大的提升,它的口号就是goes real time。使用缓存或多master设计可以降低client的数据请求压力,以减少延迟。还有就是对HDFS系统内部的修改,这就得权衡大吞吐量与低延迟了,HDFS不是万能的。
2)无法高效存储大量小文件
因为NameNode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由NameNode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300M内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没办法实现了。还有一个问题就是,因为Map task的数据是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。举个例子,处理10000M的文件,若每个split为1M,那就会有10000个Maptasks,会有很大的线程开销;若每个split为100M,则只有100个Maptasks,每个Maptask将会有更多的事情做,而线程的管理开销也将减少很多。
改进策略:要想让HDFS能处理好小文件,有不少方法。
3)不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。目前HDFS还不支持多个用户对同一个文件的写操作,以及在文件任意位置进行修改。
5、HDFS常用操作
先说一下“hadoop fs”和“hadoop dfs”的区别,看两本Hadoop书上各有用到,但效果一样,求证与网络发现下面一解释比较中肯。
粗略的讲,fs是个比较抽象的层面,在分布式环境中,fs就是dfs,但在本地环境中,fs是local file system,这个时候dfs就不能用。
5.1 文件操作
1)列出HDFS文件
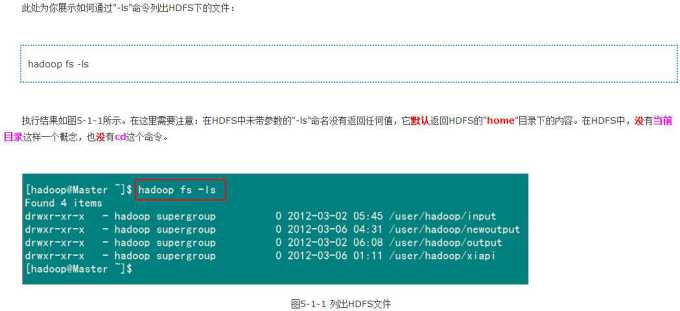
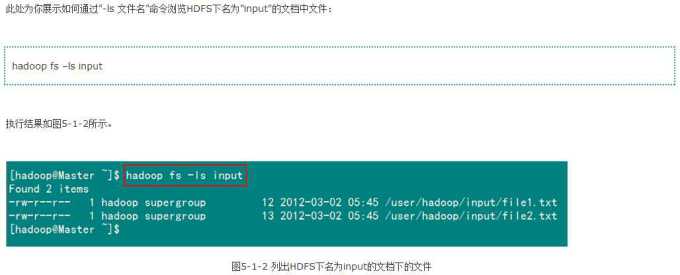
2)列出HDFS目录下某个文档中的文件
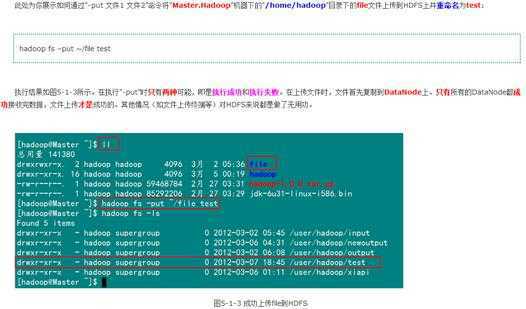
3)上传文件到HDFS
4)将HDFS中文件复制到本地系统中
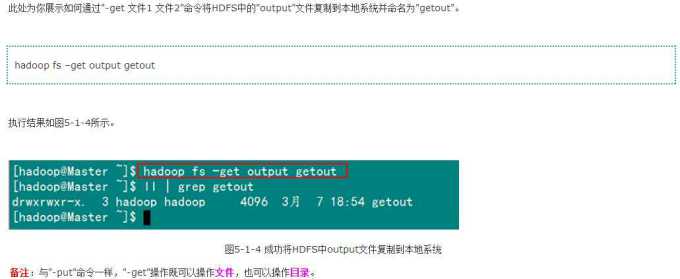
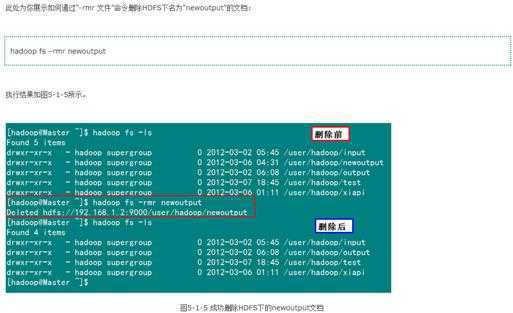
5)删除HDFS下的文档
6)查看HDFS下某个文件

“hadoop fs”的命令远远不止这些,本小节的命令可以再HDFS上完成大多数常规操作。对于其他操作,可以通过“-help commandName”命令所列出的清单来进一步学习与探索。
5.2 管理与更新
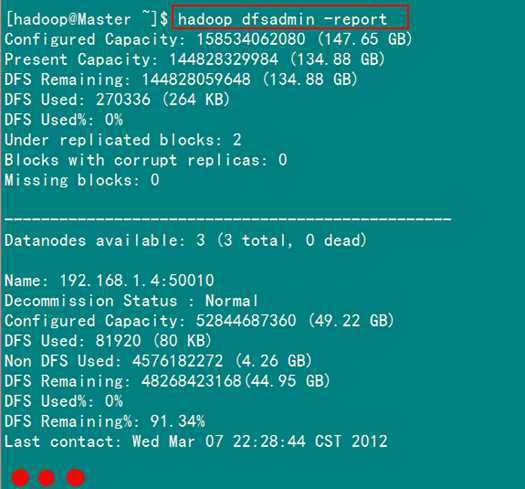
1)报告HDFS的基本统计情况
此处为你展示通过“-report”命令如何查看HDFS的基本统计信息:

执行结果如下所示。
2)退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。安全模式的目的是在系统启动时检查各个DataNode上数据块的有效性,同时根据策略对数据块进行必要的复制或删除,当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式。
系统显示“Name node is in safe mode”,说明系统正处于安全模式,这时只需要等待17秒即可,也可以通过下面的命令退出安全模式。

成功退出安全模式的结果如下所示。

3)进入安全模式
在必要的情况下,可以通过以下命令把HDFS置于安全模式。

执行结果如下所示。

4)添加节点
可扩展性是HDFS的一个重要特性,向HDFS集群中添加节点是很容易实现的。添加一个新的DataNode节点,首先在新加节点上安装好Hadoop,要和NameNode使用相同的配置(可以直接从NameNode复制),修改"/usr/hadoop/conf/master"文件,加入NameNode主机名。然后在NameNode节点上修改"/usr/hadoop/conf/slaves"文件,加入新节点主机名,再建立到新加点无密码的SSH连接,运行启动命令:

5)负载均衡
HDFS的数据在各个DataNode中的分布肯定很不均匀,尤其是DataNode节点出现故障或者新增DataNode节点时。新增数据块NameNode对DataNode节点的选择策略也有可能导致数据块分布的不均匀。用户可以使用命令重新平衡DataNode的数据块的分布:

执行命令前,DataNode节点上数据分布情况,如下所示。
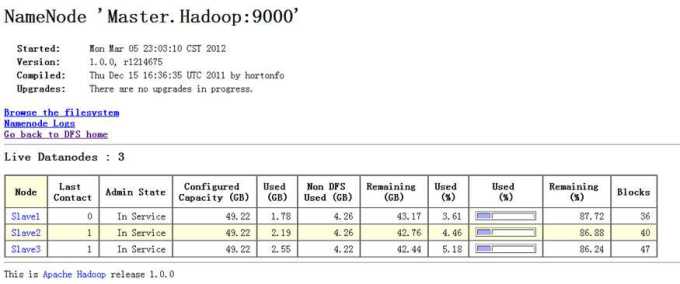
负载均衡完毕后,DataNode节点上数据的分布情况,如下所示。
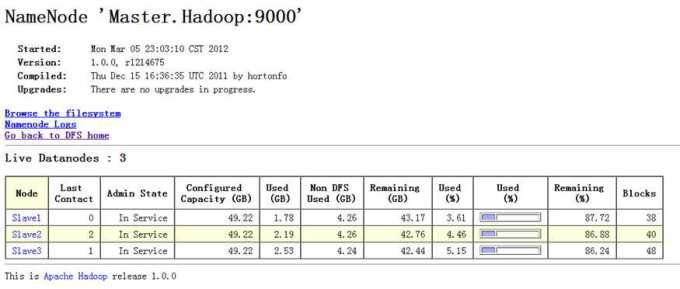
执行负载均衡命令,如下所示。

感谢原作者,链接:http://www.cnblogs.com/xia520pi/archive/2012/05/28/2520813.html
标签:
原文地址:http://www.cnblogs.com/iloveyouforever/p/4303903.html