标签:
1、机器准备,职责划分如下:
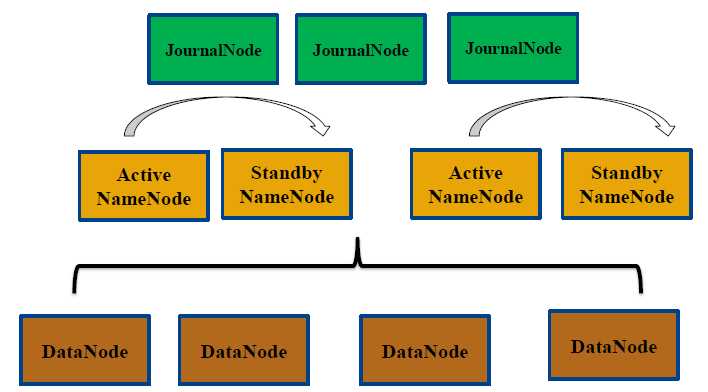
| 机器名称 | IP地址 | NameNode | DataNode | JournalNode | ZooKeeper | ZKFC | HA-Cluster1 | HA-Cluster2 | Resource Manager | Node Manager |
| hadoop01 | 192.168.147.101 | Active | √ | √ | nn1 | √ | ||||
| hadoop02 | 192.168.147.102 | Standy | √ | √ | √ | √ | nn2 | √ | ||
| hadoop03 | 192.168.147.103 | Active | √ | √ | √ | √ | nn3 | √ | ||
| hadoop04 | 192.168.147.104 | Standy | √ | √ | √ | nn4 | √ |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-cluster1</value> </property> 【这里的值指的是默认的HDFS路径。当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个哪?在这里指定!该值来自于hdfs-site.xml中的配置,在节点hadoop01和hadoop02中使用cluster1,在节点hadoop03和hadoop04中使用cluster2】 <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/hadoop2.5/tmp</value> </property> 【这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。】 <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> 【这里是ZooKeeper集群的地址和端口。注意,数量一般是奇数,且不少于三个节点】 </configuration>
2.2.3、hdfs-site.xml
1 <property> 2 <name>dfs.nameservices</name> 3 <value>hadoop-cluster1,hadoop-cluster2</value> 4 <description> 5 Comma-separated list of nameservices. 6 </description> 7 </property> 8 【使用federation时,使用了2个HDFS集群。这里抽象出两个NameService实际上就是给这2个HDFS集群起了个别名。名字可以随便起,相互不重复即可】 9 <!-- 10 hadoop cluster1 11 --> 12 <property> 13 <name>dfs.ha.namenodes.hadoop-cluster1</name> 14 <value>nn1,nn2</value> 15 <description> 16 The prefix for a given nameservice, contains a comma-separated 17 list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE). 18 </description> 19 </property> 20 【指定NameService是cluster1时的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可】 21 <property> 22 <name>dfs.namenode.rpc-address.hadoop-cluster1.nn1</name> 23 <value>hadoop01:8020</value> 24 <description> 25 RPC address for nomenode1 of hadoop-cluster1 26 </description> 27 </property> 28 【指定hadoop01的RPC地址】 29 <property> 30 <name>dfs.namenode.rpc-address.hadoop-cluster1.nn2</name> 31 <value>hadoop02:8020</value> 32 <description> 33 RPC address for nomenode2 of hadoop-test 34 </description> 35 </property> 36 【指定hadoop02的RPC地址】 37 <property> 38 <name>dfs.namenode.http-address.hadoop-cluster1.nn1</name> 39 <value>hadoop01:50070</value> 40 <description> 41 The address and the base port where the dfs namenode1 web ui will listen on. 42 </description> 43 </property> 44 【指定hadoop01的http地址】 45 <property> 46 <name>dfs.namenode.http-address.hadoop-cluster1.nn2</name> 47 <value>hadoop02:50070</value> 48 <description> 49 The address and the base port where the dfs namenode2 web ui will listen on. 50 </description> 51 </property> 52 【指定hadoop02的http地址】 53 <property> 54 <name>dfs.ha.automatic-failover.enabled.hadoop-cluster1</name> 55 <value>true</value> 56 </property> 57 【指定cluster1是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode】 58 <property> 59 <name>dfs.client.failover.proxy.provider.hadoop-cluster1</name> 60 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 61 </property> 62 【指定cluster1出故障时,哪个实现类负责执行故障切换】 63 <!-- 64 hadoop cluster2 65 --> 66 <property> 67 <name>dfs.ha.namenodes.hadoop-cluster2</name> 68 <value>nn3,nn4</value> 69 <description> 70 The prefix for a given nameservice, contains a comma-separated 71 list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE). 72 </description> 73 </property> 74 <property> 75 <name>dfs.namenode.rpc-address.hadoop-cluster2.nn3</name> 76 <value>hadoop03:8020</value> 77 <description> 78 RPC address for nomenode1 of hadoop-cluster1 79 </description> 80 </property> 81 <property> 82 <name>dfs.namenode.rpc-address.hadoop-cluster2.nn4</name> 83 <value>hadoop04:8020</value> 84 <description> 85 RPC address for nomenode2 of hadoop-test 86 </description> 87 </property> 88 <property> 89 <name>dfs.namenode.http-address.hadoop-cluster2.nn3</name> 90 <value>hadoop03:50070</value> 91 <description> 92 The address and the base port where the dfs namenode1 web ui will listen on. 93 </description> 94 </property> 95 <property> 96 <name>dfs.namenode.http-address.hadoop-cluster2.nn4</name> 97 <value>hadoop04:50070</value> 98 <description> 99 The address and the base port where the dfs namenode2 web ui will listen on. 100 </description> 101 </property> 102 <property> 103 <name>dfs.ha.automatic-failover.enabled.hadoop-cluster2</name> 104 <value>true</value> 105 </property> 106 <property> 107 <name>dfs.client.failover.proxy.provider.hadoop-cluster2</name> 108 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 109 </property> 110 <!-- 111 public 112 --> 113 <property> 114 <name>dfs.namenode.shared.edits.dir</name> 115 <value>qjournal://hadoop02:8485;hadoop03:8485;hadoop04:8485/hadoop-cluster1</value> 116 <description>A directory on shared storage between the multiple namenodes 117 in an HA cluster. This directory will be written by the active and read 118 by the standby in order to keep the namespaces synchronized. This directory 119 does not need to be listed in dfs.namenode.edits.dir above. It should be 120 left empty in a non-HA cluster. 121 </description> 122 </property> 123 【指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息】 124 <property> 125 <name>dfs.journalnode.edits.dir</name> 126 <value>/home/hadoop/app/hadoop2.5/hdfs/journal/</value> 127 </property> 128 【指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径】 129 <property> 130 <name>dfs.replication</name> 131 <value>1</value> 132 </property> 133 【指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可。】 134 <property> 135 <name>dfs.namenode.name.dir</name> 136 <value>file:///home/hadoop/app/hadoop2.5/hdfs/name</value> 137 <description>Determines where on the local filesystem the DFS name node 138 should store the name table(fsimage). If this is a comma-delimited list 139 of directories then the name table is replicated in all of the 140 directories, for redundancy. </description> 141 </property> 142 【NameNode fsiamge存放目录】 143 144 <property> 145 <name>dfs.datanode.data.dir</name> 146 <value>file:///home/hadoop/app/hadoop2.5/hdfs/data</value> 147 <description>Determines where on the local filesystem an DFS data node 148 should store its blocks. If this is a comma-delimited 149 list of directories, then data will be stored in all named 150 directories, typically on different devices. 151 Directories that do not exist are ignored. 152 </description> 153 </property> 154 <property> 155 <name>dfs.ha.fencing.methods</name> 156 <value>sshfence</value> 157 </property> 158 【一旦需要NameNode切换,使用ssh方式进行操作】 159 <property> 160 <name>dfs.ha.fencing.ssh.private-key-files</name> 161 <value>/home/hadoop/.ssh/id_rsa</value> 162 </property> 163 【如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置】
2.2.4、slaves

<!-- MR YARN Application properties --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. </description> </property> <!-- jobhistory properties --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop02:10020</value> <description>MapReduce JobHistory Server IPC host:port</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop02:19888</value> <description>MapReduce JobHistory Server Web UI host:port</description> </property>
2.2.6、yarn-site.xml
1 <!-- Resource Manager Configs --> 2 <property> 3 <description>The hostname of the RM.</description> 4 <name>yarn.resourcemanager.hostname</name> 5 <value>hadoop01</value> 6 </property> 7 8 <property> 9 <description>The address of the applications manager interface in the RM.</description> 10 <name>yarn.resourcemanager.address</name> 11 <value>${yarn.resourcemanager.hostname}:8032</value> 12 </property> 13 <property> 14 <description>The address of the scheduler interface.</description> 15 <name>yarn.resourcemanager.scheduler.address</name> 16 <value>${yarn.resourcemanager.hostname}:8030</value> 17 </property> 18 <property> 19 <description>The http address of the RM web application.</description> 20 <name>yarn.resourcemanager.webapp.address</name> 21 <value>${yarn.resourcemanager.hostname}:8088</value> 22 </property> 23 <property> 24 <description>The https adddress of the RM web application.</description> 25 <name>yarn.resourcemanager.webapp.https.address</name> 26 <value>${yarn.resourcemanager.hostname}:8090</value> 27 </property> 28 <property> 29 <name>yarn.resourcemanager.resource-tracker.address</name> 30 <value>${yarn.resourcemanager.hostname}:8031</value> 31 </property> 32 <property> 33 <description>The address of the RM admin interface.</description> 34 <name>yarn.resourcemanager.admin.address</name> 35 <value>${yarn.resourcemanager.hostname}:8033</value> 36 </property> 37 <property> 38 <description>The class to use as the resource scheduler.</description> 39 <name>yarn.resourcemanager.scheduler.class</name> 40 <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> 41 </property> 42 <property> 43 <description>fair-scheduler conf location</description> 44 <name>yarn.scheduler.fair.allocation.file</name> 45 <value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value> 46 </property> 47 <property> 48 <description>List of directories to store localized files in. An 49 application‘s localized file directory will be found in: 50 ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}. 51 Individual containers‘ work directories, called container_${contid}, will 52 be subdirectories of this. 53 </description> 54 <name>yarn.nodemanager.local-dirs</name> 55 <value>/home/hadoop/app/hadoop2.5/yarn/local</value> 56 </property> 57 <property> 58 <description>Whether to enable log aggregation</description> 59 <name>yarn.log-aggregation-enable</name> 60 <value>true</value> 61 </property> 62 <property> 63 <description>Where to aggregate logs to.</description> 64 <name>yarn.nodemanager.remote-app-log-dir</name> 65 <value>/tmp/logs</value> 66 </property> 67 <property> 68 <description>the valid service name should only contain a-zA-Z0-9_ and can not start with numbers</description> 69 <name>yarn.nodemanager.aux-services</name> 70 <value>mapreduce_shuffle</value> 71 </property>
2.2.7、fairscheduler.xml
1 <?xml version="1.0"?> 2 <allocations> 3 4 <queue name="infrastructure"> 5 <minResources>102400 mb, 50 vcores </minResources> 6 <maxResources>153600 mb, 100 vcores </maxResources> 7 <maxRunningApps>200</maxRunningApps> 8 <minSharePreemptionTimeout>300</minSharePreemptionTimeout> 9 <weight>1.0</weight> 10 <aclSubmitApps>root,yarn,search,hdfs</aclSubmitApps> 11 </queue> 12 13 <queue name="tool"> 14 <minResources>102400 mb, 30 vcores</minResources> 15 <maxResources>153600 mb, 50 vcores</maxResources> 16 </queue> 17 18 <queue name="sentiment"> 19 <minResources>102400 mb, 30 vcores</minResources> 20 <maxResources>153600 mb, 50 vcores</maxResources> 21 </queue> 22 23 </allocations>
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop-cluster2</value> </property>
2.2.9、修改hadoop03、hadoop04上的hdfs-site.xml内容
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop02:8485;hadoop03:8485;hadoop04:8485/hadoop-cluster2</value> </property>
3、启动ZooKeeper
[hadoop-ha, zookeeper][zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha[hadoop-cluster1, hadoop-cluster2]
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
7、在[nn2]上,同步nn1的元数据信息:
bin/hdfs namenode -bootstrapStandbysbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start zkfc我们的hadoop0、hadoop1有一个节点就会变为active状态
在hadoop01上执行sbin/start-yarn.shsbin/stop-yarn.sh
在[nn1]上,输入以下命令 sbin/stop-dfs.sh
Hadoop2:HA+Federation+YARN的集群部署
标签:
原文地址:http://www.cnblogs.com/home-beibei/p/4305104.html
