标签:
Libpcap库是WireSharek和Tcpdump抓包程序的基础,利用libcap我们自己也可以实现自己的抓包程序,在网络上实时抓包分析,或者利用处理的结果用作业务用途。
在实现我们的基于libcap的程序之前,我们先来了解一下libpcap(wiresharek和tcpdump也是这样)抓取的网络包的结构。下面以tcp/ip协议包为例:
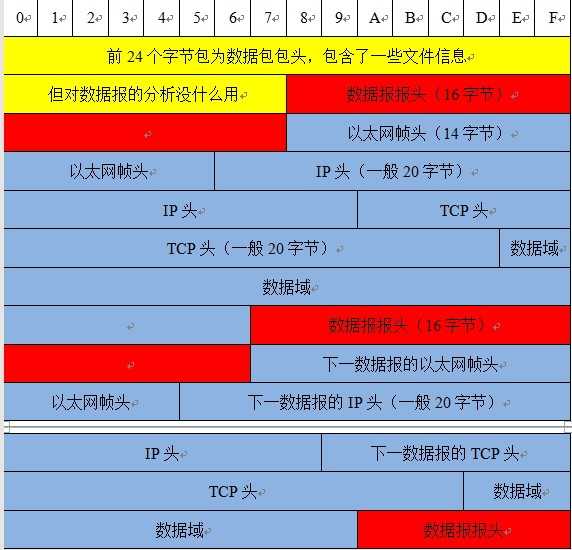
上面的数据包一共有6部分:文件头,数据报报头,以太网帧头,IP头,TCP头和数据域。其中文件头是libpcap抓取数据包时添加上去的,与网络通信无关。数据域是应用程序需要处理的数据。其他的部分则是操作系统需要处理的。
文件头详细的结构如下:
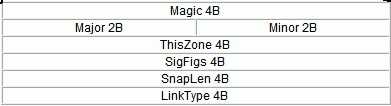
pcap.h里定义的文件头的格式结构如下:
struct pcap_file_header {
bpf_u_int32 magic;
u_short version_major;
u_short version_minor;
bpf_int32 thiszone;
bpf_u_int32 sigfigs;
bpf_u_int32 snaplen;
bpf_u_int32 linktype;
};
各字段含义如下:
l Magic:4B:0×1A 2B 3C 4D:用来识别文件自己和字节顺序。0xa1b2c3d4用来表示按照原来的顺序读取,0xd4c3b2a1表示下面的字节都要交换顺序读取。一般,我们使用0xa1b2c3d4
l Major:2B,0×02 00:当前文件主要的版本号
l Minor:2B,0×04 00当前文件次要的版本号
l ThisZone:4B 时区。GMT和本地时间的相差,用秒来表示。如果本地的时区是GMT,那么这个值就设置为0.这个值一般也设置为0 SigFigs:4B时间戳的精度;全零
l SnapLen:4B最大的存储长度(该值设置所抓获的数据包的最大长度,如果所有数据包都要抓获,将该值设置为65535; 例如:想获取数据包的前64字节,可将该值设置为64)
l LinkType:4B链路类型
常用类型:
0 BSD loopback devices, except for later OpenBSD
1 Ethernet,
and Linux loopback devices
6 802.5 Token
Ring
7 ARCnet
8 SLIP
9 PPP
10 FDDI
100 LLC/SNAP-encapsulated ATM
101 “raw IP”, with no link
102 BSD/OS SLIP
103 BSD/OS PPP
104 Cisco HDLC
105 802.11
108 later OpenBSD loopback
devices (with the AF_value in network byte order)
113 special Linux “cooked” capture
114 LocalTalk
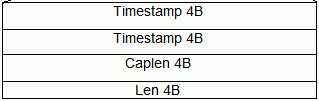
pcap.h数据报头的结构:
struct pcap_pkthdr{
struct timeval ts;
bpf_u_int32 caplen;
bpf_u_int32 len;
};
struct timeval {
long tv_sec;
suseconds_t tv_usec;
};
l ts:8字节 抓包时间 4字节表示秒数,4字节表示微秒数。需要注意的是,ts的数据类型是timeval,而timeval里的tv_sec和tv_usec在64位机器上都是8个字节,pcap_pkthdr的大小是24个字节,而网络上的数据报头是16个字节,所以在处理数据包的时候不能直接拿抓取的数据直接映射到这个数据结构上。
l caplen:4字节 保存下来的包长度(最多是snaplen,比如68字节)
l len:4字节数据报的真实长度,如果文件中保存的不是完整数据包,可能比caplen大。
略

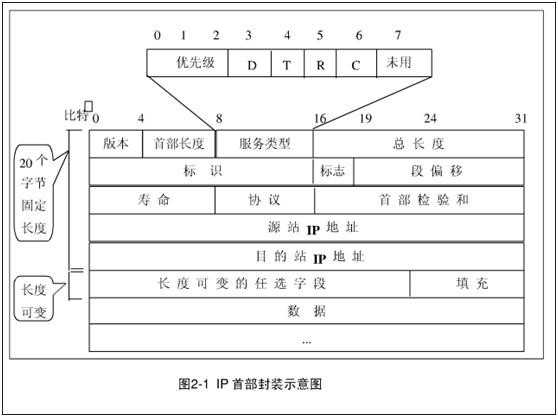
l 版本: 占4位,指IP协议的版本。通信双方使用的IP协议版本必须一致。目前广泛使用的IP协议版本号为4(即IPv4)。关于IPv6,目前还处于草案阶段。
l 首部长度 占4位,可表示的最大十进制数值是15。请注意,这个字段所表示数的单位是32位字长(1个32位字长是4字节),因此,当IP的首部长度为1111时(即十进制的15),首部长度就达到60字节。当IP分组的首部长度不是4字节的整数倍时,必须利用最后的填充字段加以填充。因此数据部分永远在4字节的整数倍开始,这样在实现IP协议时较为方便。首部长度限制为60字节的缺点是有时可能不够用。但这样做是希望用户尽量减少开销。最常用的首部长度就是20字节(即首部长度为0101),这时不使用任何选项。
l 服务类型 占8位,用来获得更好的服务。这个字段在旧标准中叫做服务类型,但实际上一直没有被使用过。1998年IETF把这个字段改名为区分服务DS(Differentiated Services)。只有在使用区分服务时,这个字段才起作用。
l 总长度 总长度指首部和数据之和的长度,单位为字节。总长度字段为16位,因此数据报的最大长度为216-1=65535字节。
在IP层下面的每一种数据链路层都有自己的帧格式,其中包括帧格式中的数据字段的最大长度,这称为最大传送单元MTU(Maximum Transfer Unit)。当一个数据报封装成链路层的帧时,此数据报的总长度(即首部加上数据部分)一定不能超过下面的数据链路层的MTU值。
l 标识(identification) 占16位。IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。
标志(flag) 占3位,但目前只有2位有意义。
l 片偏移 占13位。片偏移指出:较长的分组在分片后,某片在原分组中的相对位置。也就是说,相对用户数据字段的起点,该片从何处开始。片偏移以8个字节为偏移单位。这就是说,每个分片的长度一定是8字节(64位)的整数倍。
l 生存时间 占8位,生存时间字段常用的的英文缩写是TTL(Time To Live),表明是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在因特网中兜圈子,因而白白消耗网络资源。最初的设计是以秒作为TTL的单位。每经过一个路由器时,就把TTL减去数据报在路由器消耗掉的一段时间。若数据报在路由器消耗的时间小于1秒,就把TTL值减1。当TTL值为0时,就丢弃这个数据报。
l 协议 占8位,协议字段指出此数据报携带的数据是使用何种协议,以便使目的主机的IP层知道应将数据部分上交给哪个处理过程。
l 首部检验和 占16位。这个字段只检验数据报的首部,但不包括数据部分。这是因为数据报每经过一个路由器,路由器都要重新计算一下首部检验和(一些字段,如生存时间、标志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。
l 源地址 占32位。
l 目的地址 占32位。
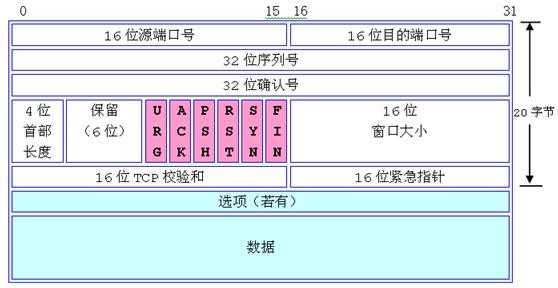
l 源端口号( 16 位):它(连同源主机 IP 地址)标识源主机的一个应用进程。
l 目的端口号( 16 位):它(连同目的主机 IP 地址)标识目的主机的一个应用进程。这两个值加上 IP 报头中的源主机 IP 地址和目的主机 IP 地址唯一确定一个 TCP 连接。
l 顺序号( 32 位):用来标识从 TCP 源端向 TCP 目的端发送的数据字节流,它表示在这个报文段中的第一个数据字节的顺序号。如果将字节流看作在两个应用程序间的单向流动,则 TCP 用顺序号对每个字节进行计数。序号是 32bit 的无符号数,序号到达 2 32 - 1 后又从 0 开始。当建立一个新的连接时, SYN 标志变 1 ,顺序号字段包含由这个主机选择的该连接的初始顺序号 ISN ( Initial Sequence Number )。
l 确认号( 32 位):包含发送确认的一端所期望收到的下一个顺序号。因此,确认序号应当是上次已成功收到数据字节顺序号加 1 。只有 ACK 标志为 1 时确认序号字段才有效。 TCP 为应用层提供全双工服务,这意味数据能在两个方向上独立地进行传输。因此,连接的每一端必须保持每个方向上的传输数据顺序号。
l TCP 报头长度( 4 位):给出报头中 32bit 字的数目,它实际上指明数据从哪里开始。需要这个值是因为任选字段的长度是可变的。这个字段占4bit ,因此 TCP 最多有 60 字节的首部。然而,没有任选字段,正常的长度是 20 字节。
l 保留位( 6 位):保留给将来使用,目前必须置为 0 。
l 控制位( control flags , 6 位):在 TCP 报头中有 6 个标志比特,它们中的多个可同时被设置为 1 。依次为:
URG :为 1 表示紧急指针有效,为 0 则忽略紧急指针值。
ACK :为 1 表示确认号有效,为 0 表示报文中不包含确认信息,忽略确认号字段。
PSH :为 1 表示是带有 PUSH 标志的数据,指示接收方应该尽快将这个报文段交给应用层而不用等待缓冲区装满。在应用层的一条消息被网络层拆分在两个数据包时,第一个数据包里的PSH为0,第二个数据包里的才会为1.
RST :用于复位由于主机崩溃或其他原因而出现错误的连接。它还可以用于拒绝非法的报文段和拒绝连接请求。一般情况下,如果收到一个 RST 为1 的报文,那么一定发生了某些问题。
SYN :同步序号,为 1 表示连接请求,用于建立连接和使顺序号同步( synchronize )。
FIN :用于释放连接,为 1 表示发送方已经没有数据发送了,即关闭本方数据流。
l 窗口大小( 16 位):数据字节数,表示从确认号开始,本报文的源方可以接收的字节数,即源方接收窗口大小。窗口大小是一个 16bit 字段,因而窗口大小最大为 65535字节。
l 校验和( 16 位):此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。这是一个强制性的字段,一定是由发送端计算和存储,并由接收端进行验证。
l 紧急指针( 16 位):只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
l 选项:最常见的可选字段是最长报文大小,又称为 MSS(Maximum Segment Size) 。每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN 标志的那个段)中指明这个选项,它指明本端所能接收的最大长度的报文段。选项长度不一定是 32 位字的整数倍,所以要加填充位,使得报头长度成为整字数。
l 数据: TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
未完待续......
参考文章:
http://blog.chinaunix.net/uid-26366978-id-3282793.html
http://www.tcpdump.org/pcap.html
http://www.360doc.com/content/14/0220/11/15257968_354157537.shtml
http://www.cnblogs.com/hnrainll/archive/2012/06/17/2552943.html
标签:
原文地址:http://www.cnblogs.com/CasperWu/p/4306404.html