标签:
LSM(Log Structured Merge Trees)数据组织方式被应用于多种数据库,如LevelDB、HBase、Cassandra等,下面我们从为什么使用LSM、LSM的实现思路两方面介绍这种存储组织结构,完成对LSM的初步了解。
存储背景回顾
LSM相较B+树或其他索引存储实现方式,提供了更好的写性能。究其原因,我们先回顾磁盘相关的一点背景知识。
顺序操作磁盘的性能,较随机读写磁盘的性能高很多,我们实现数据库时,也是围绕磁盘的这点特性进行设计与优化。如果让写性能最优,最佳的实现方式就是日志型(Log/Journal)数据库,其以追加(Append)的方式写磁盘文件。
有得即有舍,万事万物存在权衡,带来最优写性能的同时,单纯的日志数据库读性能很差,为找到一条数据,不得不遍历数据记录,要实现范围查询(range)几乎不可能。为优化日志型数据库的读性能,实际应用中通常结合以下几种优化措施:
二分查找(Binary Search): 在一个数据文件中使用二分查找加速数据查找
哈希(Hash): 写入时通过哈希函数将数据放入不同的桶中,读取时通过哈希索引直接读取
B+树: 使用B+树作为数据组织存储形式,保持数据稳定有序
外部索引文件: 除数据本身按日志形式存储外,另对其单独建立索引加速读取,如之前介绍的《一种Bitcask存储模型的实现》
以上措施都很大程度提升了读性能(如二分查找将时间复杂度提升至O(log(N))),但相应写性能也有折损,第一写数据时需要维护索引,这视索引的实现方式,最差情况下可能涉及随机的IO操作;第二如果用B+树等结构组织数据,写入涉及两次IO操作,先要将数据读出来再写入。
LSM存储结构
LSM存储实现思路与以上四种措施不太相同,其将随机写转化为顺序写,尽量保持日志型数据库的写性能优势,并提供相对较好的读性能。具体实现方式如下:
1. 当有写操作(或update操作)时,写入位于内存的buffer,内存中通过某种数据结构(如skiplist)保持key有序
2. 一般的实现也会将数据追加写到磁盘Log文件,以备必要时恢复
3. 内存中的数据定时或按固定大小地刷到磁盘,更新操作只不断地写到内存,并不更新磁盘上已有文件
4. 随着越来越多写操作,磁盘上积累的文件也越来越多,这些文件不可写且有序
5. 定时对文件进行合并操作(compaction),消除冗余数据,减少文件数量
以上过程用图表示如下:
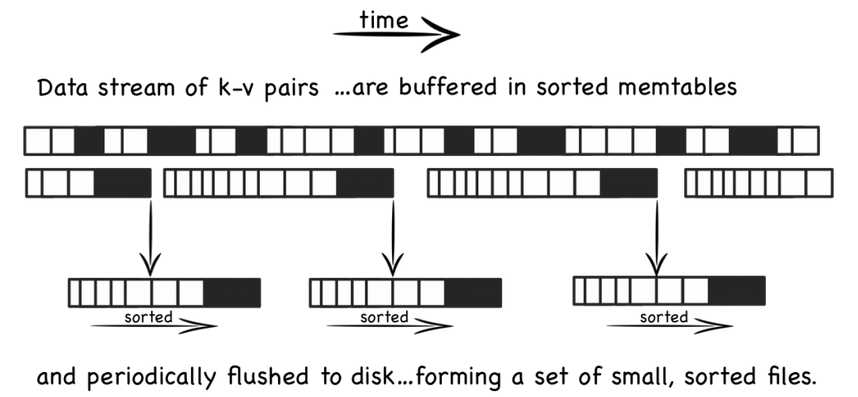
LSM存储结构的写操作,只需更新内存,内存中的数据以块数据形式刷到磁盘,是顺序的IO操作,另外磁盘文件定期的合并操作,也将带来磁盘IO操作。
LSM存储结构的读操作,先从内存数据开始访问,如果在内存中访问不到,再顺序从一个个磁盘文件中查找,由于文件本身有序,并且定期的合并减少了磁盘文件个数,因而查找过程相对较快速。
合并操作是LSM实现中重要的一环,LevelDB、Cassandra中,使用基于层级的合并方式(Levelled compaction),生成第N层的时候,对N-1层的数据进行排序,使得每层内的数据文件之间都是有序的,但最高层除外,因为该层不断有数据文件产生,因而只是数据文件内部按key有序。
除最高层外,其他层文件间数据有序,这也加速了读过程,因为一个key对应的value只存在一个文件中。假设总共有N层,每层最多K个数据文件,最差的情况下,读操作先遍历K个文件,再遍历每层,共需要K+(N-1)次读盘操作。
总结
LSM存储框架实现的思路较简单,其先在内存中保存数据,再定时刷到磁盘,实现顺序IO操作,通过定期合并文件减少数据冗余;文件有序,保证读取操作相对快速。
我们需要结合实际的业务场景选择合适的存储实现,不存在万金油式的通用存储框架。LSM适用于写多、读相对少(或较多读取最新写入的数据,该部分数据存在内存中,不需要磁盘IO操作)的业务场景。
参考文章: Log Structured Merge Trees
标签:
原文地址:http://www.cnblogs.com/bangerlee/p/4307055.html