标签:
在Redis的内部,数据结构类型值由高效的数据结构和算法进行支持,并且在Redis自身的构建当中,也大量用到了这些数据结构。
这一部分将对Redis内存所使用的数据结构和算法进行介绍。
Sds(Simple Dynamic String,简单动态字符串)
Sds在Redis中的主要作用有以下两个:
1. 实现字符串对象(StringObject);
2. 在Redis程序内部用作char* 类型的替代品;
对比C 字符串,sds有以下特性:
–可以高效地执行长度计算(strlen);
–可以高效地执行追加操作(append);
–二进制安全;
•sds会为追加操作进行优化:加快追加操作的速度,并降低内存分配的次数,代价是多占用了一些内存,而且这些内存不会被主动释放。
typedefchar *sds;
structsdshdr {
// buf已占用长度
intlen;
// buf剩余可用长度
intfree;
// 实际保存字符串数据的地方
charbuf[];
};
# 如果新字符串的总长度小于SDS_MAX_PREALLOC
# 那么为字符串分配2 倍于所需长度的空间
# 否则就分配所需长度加上SDS_MAX_PREALLOC 数量的空间
大部分C 程序都会自己实现一种链表类型,Redis也不例外。双端链表还是Redis列表类型的底层实现之一
Note: Redis列表使用两种数据结构作为底层实现:
1. 双端链表
2. 压缩列表
因为双端链表占用的内存比压缩列表要多,所以当创建新的列表键时,列表会优先考虑
使用压缩列表作为底层实现,并且在有需要的时候,才从压缩列表实现转换到双端链表实现。
除了实现列表类型以外,双端链表还被很多Redis内部模块所应用:
•事务模块使用双端链表来按顺序保存输入的命令;
•服务器模块使用双端链表来保存多个客户端;
•订阅/发送模块使用双端链表来保存订阅模式的多个客户端;
•事件模块使用双端链表来保存时间事件(time event);
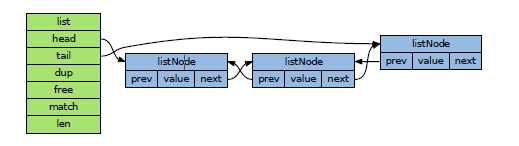
typedefstructlist {
// 表头指针
listNode*head;
// 表尾指针
listNode*tail;
// 节点数量
unsigned long len;
// 复制函数
void*(*dup)(void *ptr);
// 释放函数
void(*free)(void *ptr);
// 比对函数
int(*match)(void *ptr, void *key);
} list;
Redis为双端链表实现了一个迭代器,这个迭代器可以从两个方向对双端链表进行迭代:
双端链表及其节点的性能特性如下:
–节点带有前驱和后继指针,访问前驱节点和后继节点的复杂度为O(1) ,并且对链表
的迭代可以在从表头到表尾和从表尾到表头两个方向进行;
–链表带有指向表头和表尾的指针,因此对表头和表尾进行处理的复杂度为O(1) ;
–链表带有记录节点数量的属性,所以可以在O(1) 复杂度内返回链表的节点数量(长
度);
字典(dictionary),又名映射(map)或关联数组(associative array),在Redis中的应用广泛,使用频率可以说和SDS 以及双端链表不相上下,基本上各个功能模块都有用到字典的地方。
其中,字典的主要用途有以下两个:
1. 实现数据库键空间(key space);
2. 用作Hash 类型键的其中一种底层实现;
以下两个小节分别介绍这两种用途。
Redis的Hash 类型键使用以下两种数据结构作为底层实现:
1. 字典;
2. 压缩列表;
因为压缩列表比字典更节省内存,所以程序在创建新Hash 键时,默认使用压缩列表作为底层实现,当有需要时,程序才会将底层实现从压缩列表转换到字典。
Redis选择了高效且实现简单的哈希表作为字典的底层实现。
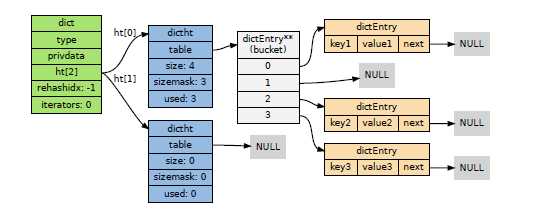
/*
* 字典
**每个字典使用两个哈希表,用于实现渐进式rehash
*/
typedefstructdict {
// 特定于类型的处理函数
dictType*type;
// 类型处理函数的私有数据
void*privdata;
// 哈希表(2 个)
dicththt[2];
// 记录rehash 进度的标志,值为-1 表示rehash 未进行
intrehashidx;
// 当前正在运作的安全迭代器数量
intiterators;
} dict;
哈希表实现
字典所使用的哈希表实现由dict.h/dictht类型定义:
/*
* 哈希表
*/
typedefstructdictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry**table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
每个dictEntry都保存着一个键值对,以及一个指向另一个dictEntry结构的指针:
/*
* 哈希表节点
*/
typedefstructdictEntry {
// 键
void*key;
// 值
union{
void*val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
structdictEntry*next;
} dictEntry;
Redis目前使用两种不同的哈希算法:
1. MurmurHash2 32 bit 算法:这种算法的分布率和速度都非常好,具体信息请参考MurmurHash的主页:http://code.google.com/p/smhasher/ 。
2. 基于djb算法实现的一个大小写无关散列算法:具体信息请参考
http://www.cse.yorku.ca/~oz/hash.html 。
字典哈希表所使用的碰撞解决方法被称之为链地址法:
字典收缩和字典扩展的一个区别是:
•字典的扩展操作是自动触发的(不管是自动扩展还是强制扩展);
•而字典的收缩操作则是由程序手动执行。
字典由键值对构成的抽象数据结构。
•Redis中的数据库和哈希键都基于字典来实现。
•Redis字典的底层实现为哈希表,每个字典使用两个哈希表,一般情况下只使用0 号哈希表,只有在rehash 进行时,才会同时使用0 号和1 号哈希表。
•哈希表使用链地址法来解决键冲突的问题。
• Rehash 可以用于扩展或收缩哈希表。
•对哈希表的rehash 是分多次、渐进式地进行的。
它的效率可以和平衡树媲美——查找、删除、添加等操作都可以在对数期望时间下完成,
并且比起平衡树来说,跳跃表的实现要简单直观得多。
•表头(head):负责维护跳跃表的节点指针。
•跳跃表节点:保存着元素值,以及多个层。
•层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
•表尾:全部由NULL 组成,表示跳跃表的末尾。
看图想象:
1) 查找简单:比如要查找5,第一层没找到,第二层定位4—6之间,再降一层则找到5。
2) 插入算法呢?还是不太确定怎么实现
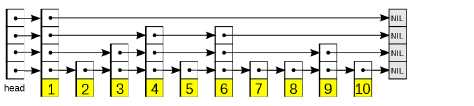
跳跃表在Redis的唯一作用,就是实现有序集数据类型。
跳跃表将指向有序集的score 值和member 域的指针作为元素,并以score 值为索引,对有序集元素进行排序。
为了适应自身的需求,Redis基于William Pugh 论文中描述的跳跃表进行了修改,包括:1. score 值可重复。
2. 对比一个元素需要同时检查它的score 和memeber。
3. 每个节点带有高度为1 层的后退指针,用于从表尾方向向表头方向迭代。
标签:
原文地址:http://www.cnblogs.com/itsmylife/p/4312148.html