标签:
转自: http://blog.csdn.net/jwh_bupt/article/details/7663885
聚类系列:
聚类(序)----监督学习与无监督学习
聚类(1)----混合高斯模型 Gaussian Mixture Model
聚类(2)----层次聚类 Hierarchical Clustering
聚类(3)----谱聚类 Spectral Clustering
--------------------------------
聚类的方法有很多种,k-means要数最简单的一种聚类方法了,其大致思想就是把数据分为多个堆,每个堆就是一类。每个堆都有一个聚类中心(学习的结果就是获得这k个聚类中心),这个中心就是这个类中所有数据的均值,而这个堆中所有的点到该类的聚类中心都小于到其他类的聚类中心(分类的过程就是将未知数据对这k个聚类中心进行比较的过程,离谁近就是谁)。其实k-means算的上最直观、最方便理解的一种聚类方式了,原则就是把最像的数据分在一起,而“像”这个定义由我们来完成,比如说欧式距离的最小,等等。想对k-means的具体算法过程了解的话,请看这里。而在这篇博文里,我要介绍的是另外一种比较流行的聚类方法----GMM(Gaussian Mixture Model)。
GMM和k-means其实是十分相似的,区别仅仅在于对GMM来说,我们引入了概率。说到这里,我想先补充一点东西。统计学习的模型有两种,一种是概率模型,一种是非概率模型。所谓概率模型,就是指我们要学习的模型的形式是P(Y|X),这样在分类的过程中,我们通过未知数据X可以获得Y取值的一个概率分布,也就是训练后模型得到的输出不是一个具体的值,而是一系列值的概率(对应于分类问题来说,就是对应于各个不同的类的概率),然后我们可以选取概率最大的那个类作为判决对象(算软分类soft assignment)。而非概率模型,就是指我们学习的模型是一个决策函数Y=f(X),输入数据X是多少就可以投影得到唯一的一个Y,就是判决结果(算硬分类hard assignment)。回到GMM,学习的过程就是训练出几个概率分布,所谓混合高斯模型就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
得到概率有什么好处呢?我们知道人很聪明,就是在于我们会用各种不同的模型对观察到的事物和现象做判决和分析。当你在路上发现一条狗的时候,你可能光看外形好像邻居家的狗,又更像一点点女朋友家的狗,你很难判断,所以从外形上看,用软分类的方法,是女朋友家的狗概率51%,是邻居家的狗的概率是49%,属于一个易混淆的区域内,这时你可以再用其它办法进行区分到底是谁家的狗。而如果是硬分类的话,你所判断的就是女朋友家的狗,没有“多像”这个概念,所以不方便多模型的融合。
从中心极限定理的角度上看,把混合模型假设为高斯的是比较合理的,当然也可以根据实际数据定义成任何分布的Mixture Model,不过定义为高斯的在计算上有一些方便之处,另外,理论上可以通过增加Model的个数,用GMM近似任何概率分布。
混合高斯模型的定义为:
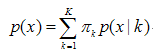
其中K为模型的个数,πk为第k个高斯的权重,则为第k个高斯的概率密度函数,其均值为μk,方差为σk。我们对此概率密度的估计就是要求πk、μk和σk各个变量。当求出的表达式后,求和式的各项的结果就分别代表样本x属于各个类的概率。
在做参数估计的时候,常采用的方法是最大似然。最大似然法就是使样本点在估计的概率密度函数上的概率值最大。由于概率值一般都很小,N很大的时候这个连乘的结果非常小,容易造成浮点数下溢。所以我们通常取log,将目标改写成:

也就是最大化log-likelyhood function,完整形式则为:

一般用来做参数估计的时候,我们都是通过对待求变量进行求导来求极值,在上式中,log函数中又有求和,你想用求导的方法算的话方程组将会非常复杂,所以我们不好考虑用该方法求解(没有闭合解)。可以采用的求解方法是EM算法——将求解分为两步:第一步是假设我们知道各个高斯模型的参数(可以初始化一个,或者基于上一步迭代结果),去估计每个高斯模型的权值;第二步是基于估计的权值,回过头再去确定高斯模型的参数。重复这两个步骤,直到波动很小,近似达到极值(注意这里是个极值不是最值,EM算法会陷入局部最优)。具体表达如下:
1、对于第i个样本xi来说,它由第k个model生成的概率为:
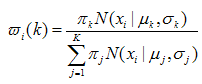
在这一步,我们假设高斯模型的参数和是已知的(由上一步迭代而来或由初始值决定)。
(E step)

(M step)
3、重复上述两步骤直到算法收敛(这个算法一定是收敛的,至于具体的证明请回溯到EM算法中去,而我也没有具体关注,以后补上)。

最后总结一下,用GMM的优点是投影后样本点不是得到一个确定的分类标记,而是得到每个类的概率,这是一个重要信息。GMM每一步迭代的计算量比较大,大于k-means。GMM的求解办法基于EM算法,因此有可能陷入局部极值,这和初始值的选取十分相关了。GMM不仅可以用在聚类上,也可以用在概率密度估计上。
聚类——混合高斯模型 Gaussian Mixture Model
标签:
原文地址:http://www.cnblogs.com/jerrice/p/4313592.html