标签:
这里的迁移指的是从一个数据库迁移到另一个,比如组织库
一个公司可能有多个系统,各个系统又有各自的组织架构
比如 HR 系统的用户发生信息(手机号,住址)修改时,其它的库也要跟着发生改变
如图(这里为了方便,两个系统的组织架构表结构和字段都一样了,现实中肯定不一样):
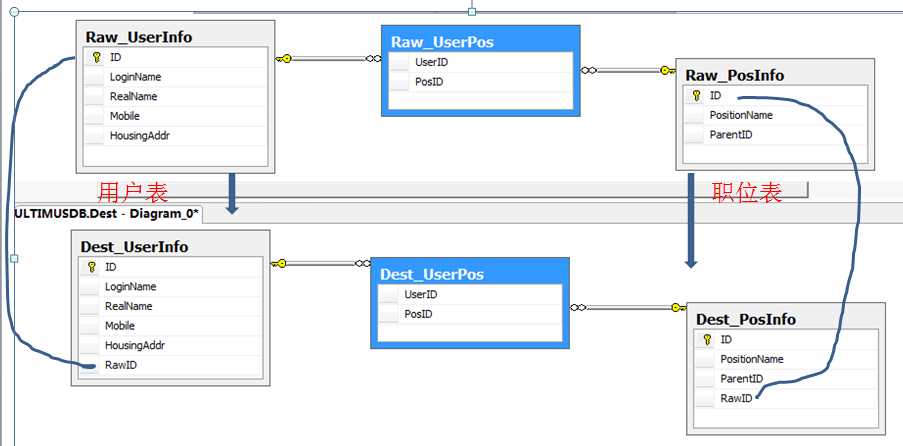
上面一个系统,下面是另一个系统,数据从上面的系统同步到下面。数据在第一个系统(源表)中新增了用户,或者修改了用户信息,第二个系统也要做对应的业务操作,弯曲是两个系统关联的第三方ID。
以往迁移会使用步骤:
1. 通过SQL查询拿到数据。
2. 应用C#(Java 或者 Ruby、Python脚本)读取SQL结果集并对其作比较,检查源表是做了【插入】、【修改】还是【删除】了用户信息和组织信息。
3. 比较后对目标表作相应的【插入】、【修改】、【删除】业务操作。
但这里我们采用:
1. SQL查询并比较,直接分辨出源表中【插入】、【修改】、【删除】的数据。
2. 根据上面比较的信息,使用SQL或者API接口把修过的数据更新到目标表。
优点:
SQL批处理的即时结果的特性,直接可以看出插入、修改、删除了哪些数据,而不用中间语言(C#\Java\Python\Ruby)去比较信息,对用户调试,特别是对于几 千上万用户信息的情况尤其有利。
缺点:
以下标红的地方,可先略过。
实现过程:
步骤1:找出所有变更过信息(手机号、住址等)的和新增的用户,这一步只要找出用户ID就行了,关于【删除】用户在【步骤4】:
;WITH SrcModified AS ( SELECT ID , Mobile , HousingAddr FROM Raw.dbo.Raw_UserInfo -- 源表 EXCEPT SELECT ID = RawID , Mobile , HousingAddr FROM Dest.dbo.Dest_UserInfo -- 目标表 ), modified AS ( SELECT ID FROM srcModified ) SELECT ID FROM modified
步骤2:找出新增的用户,这里也只要找出用户ID,黄色区为较前一步新增的逻辑,下同。
1 ;WITH SrcModified AS ( 2 SELECT ID 3 , Mobile 4 , HousingAddr 5 FROM Raw.dbo.Raw_UserInfo -- 源表 6 EXCEPT 7 SELECT ID = RawID 8 , Mobile 9 , HousingAddr 10 FROM Dest.dbo.Dest_UserInfo -- 目标表 11 ), modified AS ( 12 SELECT ID FROM srcModified 13 ), toAdd AS ( SELECT ID FROM modified AS m -- 修改过的用户,并且在目标表中没有,就代表添加的用户 14 WHERE NOT EXISTS ( SELECT * FROM Dest.dbo.Dest_UserInfo AS dest 15 WHERE m.ID = dest.RawID) -- 用第三方ID关联 16 ) SELECT ID FROM toAdd
步骤3:找出修改过信息(手机号、住址等),这里同样用到我们的朋友 Except ,计算公式为:【变更的】 - 【添加的】 = 修改的
1 ;WITH SrcModified AS ( 2 SELECT ID 3 , Mobile 4 , HousingAddr 5 FROM Raw.dbo.Raw_UserInfo -- 源表 6 EXCEPT 7 SELECT ID = RawID 8 , Mobile 9 , HousingAddr 10 FROM Dest.dbo.Dest_UserInfo -- 目标表 11 ), modified AS ( 12 SELECT ID FROM srcModified 13 ), toAdd AS ( SELECT ID FROM modified AS m -- 修改过的用户,并且在目标表中没有,就代表添加的用户 14 WHERE NOT EXISTS ( 15 SELECT * FROM Dest.dbo.Dest_UserInfo AS dest 16 WHERE m.ID = dest.RawID -- 用第三方ID关联 17 ) 18 ) ,toModify AS ( SELECT ID 19 FROM modified 20 EXCEPT 21 SELECT ID 22 FROM toAdd 23 ) 24 SELECT * FROM toModify
步骤4:指出从源表中删除的用户。目标表中保存有源表的ID,方式与上面计算方式不同。
1 ;WITH SrcModified AS ( 2 SELECT ID 3 , Mobile 4 , HousingAddr 5 FROM Raw.dbo.Raw_UserInfo -- 源表 6 EXCEPT 7 SELECT ID = RawID 8 , Mobile 9 , HousingAddr 10 FROM Dest.dbo.Dest_UserInfo -- 目标表 11 ), modified AS ( 12 SELECT ID FROM srcModified 13 ), toAdd AS ( SELECT ID FROM modified AS m -- 修改过的用户,并且在目标表中没有,就代表添加的用户 14 WHERE NOT EXISTS ( 15 SELECT * FROM Dest.dbo.Dest_UserInfo AS dest 16 WHERE m.ID = dest.RawID -- 用第三方ID关联 17 ) 18 ) ,toModify AS ( SELECT ID 19 FROM modified 20 EXCEPT 21 SELECT ID 22 FROM toAdd 23 ) ,toDel AS ( SELECT d.ID 24 FROM Dest.dbo.dest_UserInfo AS d 25 WHERE NOT EXISTS ( SELECT * FROM Raw.dbo.Raw_UserInfo src 26 WHERE src.ID = d.RawID --目标表中保存有源表的ID 27 ) 28 ) SELECT * FROM toDel
步骤5: 汇总查出所有添加,修改,删除的用户信息, 得到的执行结果 opType ( 1: 新增,2:修改,3:删除 )
1 ;WITH SrcModified AS ( 2 SELECT ID 3 , Mobile 4 , HousingAddr 5 FROM Raw.dbo.Raw_UserInfo -- 源表 6 EXCEPT 7 SELECT ID = RawID 8 , Mobile 9 , HousingAddr 10 FROM Dest.dbo.Dest_UserInfo -- 目标表 11 ), modified AS ( 12 SELECT ID FROM srcModified 13 ), toAdd AS ( SELECT ID FROM modified AS m -- 修改过的用户,并且在目标表中没有,就代表添加的用户 14 WHERE NOT EXISTS ( 15 SELECT * FROM Dest.dbo.Dest_UserInfo AS dest 16 WHERE m.ID = dest.RawID -- 用第三方ID关联 17 ) 18 ) ,toModify AS ( SELECT ID 19 FROM modified 20 EXCEPT 21 SELECT ID 22 FROM toAdd 23 ) ,toDel AS ( SELECT d.ID 24 FROM Dest.dbo.dest_UserInfo AS d 25 WHERE NOT EXISTS ( SELECT * FROM Raw.dbo.Raw_UserInfo src 26 WHERE src.ID = d.RawID --目标表中保存有源表的ID 27 ) 28 ) ,allModified AS( 29 SELECT ID ,1 AS opType FROM toAdd --所有添加用户 30 UNION ALL 31 SELECT ID ,2 AS opType FROM toModify --修改过信息的用户 32 UNION ALL 33 SELECT ID ,3 AS opType FROM toDel --从源表中删除的用户 34 ) 35 SELECT ID, opType FROM allModified
关键步骤在这里都已经结束了,这一步拿到的数据是用户ID及发生过的操作(添加、修改、删除)信息,下一步就是关联源表,并取出所有信息
步骤6: 关联源表,取出所有信息,这时候几乎就可以为所欲为了,通过应用(使用SQL或者其它API)这些数据对目标表进行新增,删除。且更新(这里存在唯一的遗憾,因为分不出修改的哪个字段 <手机还是住址>,所以它会修改所有比较过(Except)的字段,不过可以通过控制这些比较的字段,并在最终更新时控制更新的范围,来减少不必要的更新,不过SQL比较擅长批处理,这种活交给C#或其它动态脚本做进一步处理也是可以的。在实际应用当中,经过处理后这种更新的东西每次性更新的数据是非常少的,所以带来的副作用可以忽略)。
以下 SQL 是最终版,这里是用户信息,其它(部门、职位)信息,使用方式一样:
1 ;WITH SrcModified AS ( 2 SELECT ID 3 , Mobile 4 , HousingAddr 5 FROM Raw.dbo.Raw_UserInfo -- 源表 6 EXCEPT 7 SELECT ID = RawID 8 , Mobile 9 , HousingAddr 10 FROM Dest.dbo.Dest_UserInfo -- 目标表 11 ), modified AS ( 12 SELECT ID FROM srcModified 13 ), toAdd AS ( SELECT ID FROM modified AS m -- 修改过的用户,并且在目标表中没有,就代表添加的用户 14 WHERE NOT EXISTS ( 15 SELECT * FROM Dest.dbo.Dest_UserInfo AS dest 16 WHERE m.ID = dest.RawID -- 用第三方ID关联 17 ) 18 ) ,toModify AS ( SELECT ID 19 FROM modified 20 EXCEPT 21 SELECT ID 22 FROM toAdd 23 ) ,toDel AS ( SELECT d.ID 24 FROM Dest.dbo.dest_UserInfo AS d 25 WHERE NOT EXISTS ( SELECT * FROM Raw.dbo.Raw_UserInfo src 26 WHERE src.ID = d.RawID --目标表中保存有源表的ID 27 ) 28 ) ,allModified AS( 29 SELECT ID ,1 AS opType FROM toAdd --所有添加用户 30 UNION ALL 31 SELECT ID ,2 AS opType FROM toModify --修改过信息的用户 32 UNION ALL 33 SELECT ID ,3 AS opType FROM toDel --从源表中删除的用户 34 ) 35 SELECT m.opType 36 , m.ID 37 , u.Mobile 38 , u.HousingAddr 39 FROM allModified as m 40 left join Raw.dbo.Raw_UserInfo as u on m.ID = u.ID
可能遇到的问题:
1. 在做集合操作(减Except、交Intersect、并Union)时,如果两个数据库的编码不一样,一个是中文的,一个是英文,或者其它就会提示不能比较的错误,这个时候使用在语句 中使用 collate 把各个列统一成一样的,就可以操作了,例如以下两个列的手机号在两个不同编码的库里,做集合操作时可以统一成中文的
1 select s.Mobile collate Chinese_PRC_CS_AS_KS_WS from src as s 2 Except 3 select d.Mobile collate Chinese_PRC_CS_AS_KS_WS from dest as d
2. 源表和目标表很可能会在不同服务器上,这个时候做集合操作也会非常慢,可以使用 select ... into 把数据放入临时表进行比较。
其它小技巧:
1. 一般我们为客户做迁移的时候,用户信息太多,而能拿到的测试的数据没有代表性,他们可能只会拿出某个部门,或者一小部分的数据给你做测试,但这样是不够的,如果客户只能提供一小部分,可以和客户商量使用 TableSample 查询部分信息,它可以随机抽取任意百分比的源信息,分部相对均匀,这样就可以保证一定的测试覆盖率。
2. 为了测试,我们不得考虑到各种情况,一个快速且小量而又不污染源表的方法,可以使用 + union all select 这种方式添加临时数据,这样很方便于测试,例如我想直接添加一个额外的用户,就可以:
select UserName from formal -- 正式的结果 union all select ‘额外的用户名称‘ as UserName -- 临时的测试用户
总结: 单就查询速度来说,这种方式效率并不高,因为每一个公用表达式都会扫描一次表,但这种方式比用中间语言(非SQL)把数据抽取出来,并使用各种 if ... else... 比较发生过修改过的字段信息要强得多,因为它是即时的批量查询,可以直接看到修改过的信息。
以上所有代码测试环境为MS SQL Server,Postgres应该是可以运行的,因为MySQL不支持公用表达式,可能要做相应的修改。
标签:
原文地址:http://www.cnblogs.com/mikedeng/p/ez_migrate.html