标签:
转载请注明: TheViper http://www.cnblogs.com/TheViper
模型就以贴吧为例
var themeModel = modelBase._mongoose.model(‘theme‘,modelBase._schema({ theme_name:String, posts:[{ post_id:String, title:String, content:String, time:Number, user:{type:objectId,ref:‘user‘}, img_list:[String], suppost:Boolean, post_ref:String, comments:[{ content:String, time:Number, from:{type:objectId,ref:‘user‘}, to:{type:objectId,ref:‘user‘} }] }] }),‘theme‘);
这里模型故意弄的复杂点,其实就是多点嵌套。实际开发时请根据不同场景,性能,扩展等因素综合考虑。
mongodb其实查询性能是比不上常见的关系数据库的,只是写的性能要好些,另外,no sheme模型让模型可以很灵活,就像上面那样,可以一个collection就包含关系数据库的几个表.所以这里就着重用它的优点来看看。
下面解释下上面的model:
最上面是主题theme,比如什么吧。然后是主题,一个theme有很多主题。接着是回复,也是一个主题有多个回复。最后是评论,又是一个回复有多个评论。
具体到上面的代码,我为了偷懒,就把主题和回复和并在一起了,这就不严谨了,因为百度贴吧的回复是没有title的,而主题是必须有的,这里就不管这么多了,反正只是个演示。
注意到有个字段是post_ref,如果post是主题,那post_ref就和post_id是一样的值;如果是回复,那post_ref就是它的上级,也就是主题的post_id.suppost是true,表示是主题;false表示是主题的回复。另外还有个表是user(id,name)就不列了。
我胡乱弄了点数据
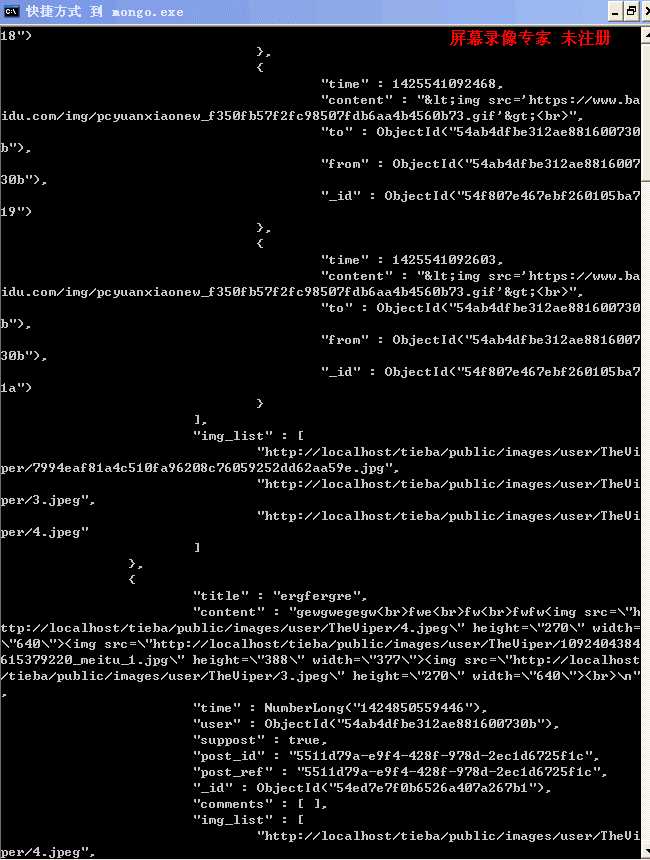
1.查询主题
return function(fn){ themeModel.aggregate().unwind(‘posts‘).match({‘posts.post_ref‘:post_id,‘posts.user‘:suppost_user}) .sort({"posts.time":1}).skip(skip).limit(limit).group({_id:"$_id",posts:{$push:"$posts"}}).exec() .then(function(theme){ return themeModel.populate(theme,[{path:‘posts.user‘,select:‘name‘},{path:‘posts.comments.from‘,select:‘name‘}, {path:‘posts.comments.to‘,select:‘name‘}]); }).then(function(theme){ fn(null,theme); }); };
可以看到这里用了mongodb的aggregation。关于aggregation,这里有一个sql to aggregation mapping chart
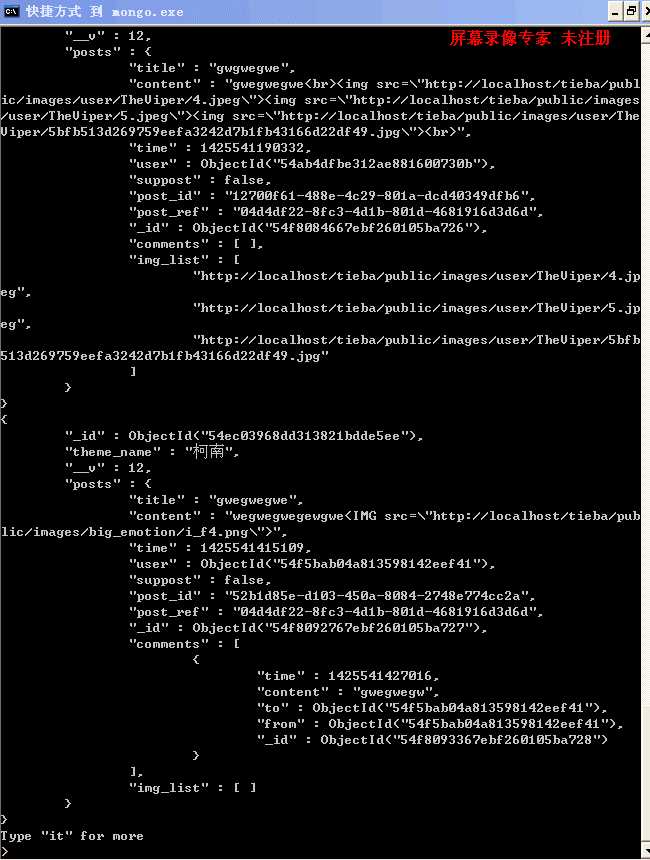
可以看到unwind把最上级也就是主题的theme_name,_id分别添加到posts里面的每一个项.这个就是解决mongodb多级嵌套的神器,后面可以看到每个场景都用到了这个unwind.另外aggregate是严格按照顺序执行,也就是unwind()在这里必须在最前面,否则没有效果。
执行完unwind后就会发现后面的match({‘posts.suppost‘:suppost}),sort({"posts.time":-1})就很简单了,因为现在不是数组,而是对象了,直接用.运算符取就可以取到嵌套的字段了。
$group可以想成sql里面的group by,但是有些不一样,$group实际上是让你自定义聚合后需要返回哪些字段,因此$group里面至少要有_id,哪怕是group({_id:null})也可以。
后面的posts:{$push:"$posts"}是将posts每一项重新添加到新的posts数组,这里一定要写出"$posts".
然后exec()返回Promise,再在then里面对字段里面与user集合有关联的字段进行填充(populate),取出user集合里面的name.
这里是瀑布流
2.查询回复
this.getPostByPostId=function(post_id,skip,limit){ return function(fn){ themeModel.aggregate().unwind(‘posts‘).match({‘posts.post_ref‘:post_id}) .sort({"posts.time":1}).skip(skip).limit(limit).group({_id:"$_id",posts:{$push:"$posts"}}).exec() .then(function(theme){ return themeModel.populate(theme,[{path:‘posts.user‘,select:‘name‘},{path:‘posts.comments.from‘,select:‘name‘}, {path:‘posts.comments.to‘,select:‘name‘}]); }).then(function(theme){ fn(null,theme); }); }; };
可以看到和第一个相比,查询条件变成了‘posts.post_id‘:post_id,其他的都差不多
3.获取主题总数
this.getSuppostCount=function(theme_name){ return function(fn){ themeModel.aggregate().unwind(‘posts‘).match({theme_name:theme_name,‘posts.suppost‘:true}) .group({_id:null,count:{$sum:1}}).exec() .then(function(theme){ fn(null,theme); }); }; };

4.获取回复总数
this.getPostCount=function(theme_name,post_id){ return function(fn){ themeModel.aggregate().unwind(‘posts‘).match({‘posts.post_ref‘:post_id}) .group({_id:"$_id",count:{$sum:1}}).exec() .then(function(post){ fn(null,post); }); }; };

5.插入评论
this.insertComment=function(from,to,content,time,theme_name,post_id){ return themeModel.update({theme_name:theme_name,‘posts.post_id‘:post_id},{$push:{‘posts.$.comments‘:{ from:from, to:to, content:content, time:time }}}); };
由于是多级嵌套,所以这里实际是update.注意,这里$push的对象是posts.$.comments,而不是posts.comments.$在这里是个占位符,官方文档说的很详细。
另外,$是个占位符意外着update的条件必须要能够确定posts.$ ,所以在这里条件中必须要有‘posts.post_id‘:post_id。
暂时更新这么多,以后如果有新的发现,会不定期更新此文。
标签:
原文地址:http://www.cnblogs.com/TheViper/p/4317660.html