标签:
本文目的
?
最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken)。感觉需要记录点什么,才对得起自己。下面的内容主要是关于Spark核心—RDD的相关的使用经验和原理介绍,作为个人备忘,也希望对读者有用。
?
为什么选择Spark
?
原因如下
?
Spark计算性能虽然明显比Hadoop高效,但并不是我们技术选型的主要原因,因为现有基于Hadoop +hive的计算性能已经足够了。
?
?
基石哥—RDD
?
整个spark衍生出来的工具都是基于RDD(Resilient Distributed Datesets),如图:
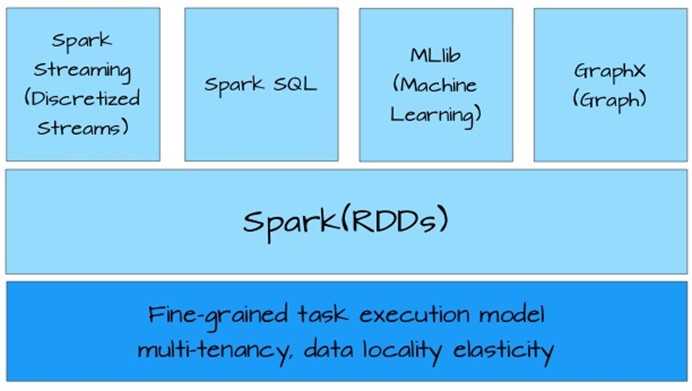
RDD是一个抽象的数据集,提供对数据并行和容错的处理。初次始使用RDD时,其接口有点类似Scala的Array,提供map,filter,reduce等操作。但是,不支持随机访问。刚开始不太习惯,但是逐渐熟悉函数编程和RDD 的原理后,发现随机访问数据的场景并不常见。
?
为什么RDD效率高
?
Spark官方提供的数据是RDD在某些场景下,计算效率是Hadoop的20X。这个数据是否有水分,我们先不追究,但是RDD效率高的由一定机制保证的:
总而言之,RDD高效的主要因素是尽量避免不必要的操作和牺牲数据的操作精度,用来提高计算效率。
?
变量分享
?
RDD使用中,很重要的场景就是变量分享,举个例子:
var my_var = … // 外部变量 my_rdd.map(x => x + my_var) |
在上面的例子中,my_rdd是一个RDD[Int]对象,在进行map操作时,RDD会将函数{x => x+my_var}打包成一个java对象,然后序列化,并且分发到my_rdd所在的节点上。但是,my_var是一个外部变量,这种变量是否也会传到其他节点上呢?这取决于实际情况。
?
比如这个例子,
var my_var = 5 my_rdd.map(x => x + my_var) |
此时,my_var = 5是会被一起打包,并发送到其他节点上。
?
再看这个例子,
var my_var = read_user_input my_rdd.map(x => x + my_var) |
此时,编译没有问题,但是运行时会报错,声称找不到my_var。其解决方案如下,
var bc_ my_var = spark_context.broadcast(read_user_input) my_rdd.map(x => x + bc_my_var.value) |
显示的通过广播的方式,将变量送到其他节点,这样在运行时,外部变量就可以被正确访问。
?
原则:编译时可以找到外部变量的值,那么将会被打包到RDD函数中;否则,那些只有在运行时才能确定的外部变量,必须通过广播机制,显示的发送到其他节点。
?
参考资料
标签:
原文地址:http://www.cnblogs.com/bourneli/p/4320878.html