标签:
纯文本不适合记录二进制类型的数据,在这种情况看下,Hadoop的SequenceFile类非常合适,为二进制键值对提供了一种持久的数据结构
1.SequenceFile的写操作
通过createWriter()静态方法可以创建SequenceFile对象,并返回SequenceFile.Writer实例
该静态方法需要指定待写入的数据流(FSDataOutputStream或FileSystem对象和Path对象),Configuration对象,以及键和值得类型
一旦拥有SequenceFile.Writer实例,就可以通过append()方法在文件末尾附加键值对
写入SequenceFile对象,程序如下:
package com.lcy.hadoop.io;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
public class SequenceFileWriteDemo {
private static final String [] DATA={
"One,two,buckle my shoe",
"Three,four,shut the door",
"Five,six,pick up sticks",
"Seven,eight,lay them straight",
"Nine,ten,a big fat hen"
};
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
String uri=args[0];
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri);
IntWritable key=new IntWritable();
Text value=new Text();
SequenceFile.Writer writer=null;
try{
writer=SequenceFile.createWriter(fs,conf,path,key.getClass(),value.getClass());
for(int i=0;i<100;i++){
key.set(100-i);
value.set(DATA[i%DATA.length]);
System.out.printf("[%s]\t%s\t%s\n",writer.getLength(),key,value);
writer.append(key, value);
}
}finally{
IOUtils.closeStream(writer);
}
}
}
运行程序:

运行结果:
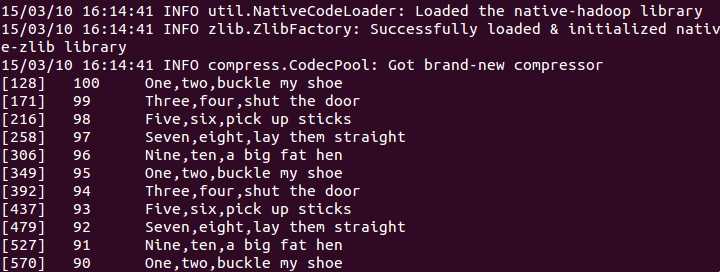
......

2.SequenceFile的读操作
从头到尾读取顺序文件就是创建SequenceFile.Reader实例后反复调用next()方法迭代读取记录
如果next()方法返回的是非null对象,则可以从该数据流中读取键值对
程序如下:
package com.lcy.hadoop.io;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
public class SequenceFileReadDemo {
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
String uri=args[0];
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri);
SequenceFile.Reader reader=null;
try{
reader=new SequenceFile.Reader(fs, path, conf);
Writable key=(Writable)ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value=(Writable)ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position=reader.getPosition();
while(reader.next(key,value)){
String syncSeen=reader.syncSeen()?"*":" ";
System.out.printf("[%s%s]\t%s\t%s\n",position,syncSeen,key,value);
position=reader.getPosition();
}
}finally{
IOUtils.closeStream(reader);
}
}
}
运行程序:

运行结果:

......

该程序的一个特性是能够显示顺序文件中同步点的位置信息
同步点:指数据读取的实例出错后能够再一次与记录边界同步的数据流中的一个位置 [2026*]
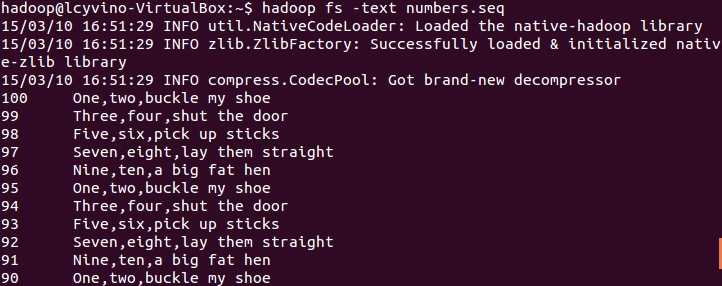
3.通过命令行接口显示SequenceFile
hadoop fs 命令有一个 -text 选项可以以文本形式显示顺序文件
标签:
原文地址:http://www.cnblogs.com/Murcielago/p/4326554.html