标签:zookeeper
本质上来说,ZK也是一种分布式存储系统,下面就从分布式存储的角度来看下ZK的设计跟实现。
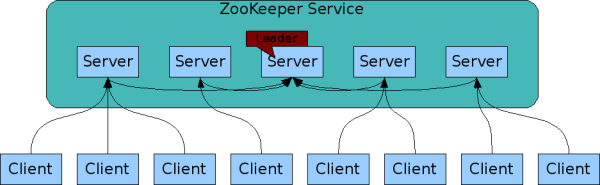
ZK采用的是无master设计(物理上,逻辑上还是有的),ZK客户端连接服务端的时候,需要传入一个连接字符串,
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly)
throws IOException
{
LOG.info("Initiating client connection, connectString=" + connectString
+ " sessionTimeout=" + sessionTimeout + " watcher=" + watcher);
watchManager.defaultWatcher = watcher;
ConnectStringParser connectStringParser = new ConnectStringParser(
connectString);
HostProvider hostProvider = new StaticHostProvider(
connectStringParser.getServerAddresses());
cnxn = new ClientCnxn(connectStringParser.getChrootPath(),
hostProvider, sessionTimeout, this, watchManager,
getClientCnxnSocket(), canBeReadOnly);
cnxn.start();
}也就是上面的connectString,最后连接到哪台机器,或者当前连接的机器挂掉需要重连,逻辑是在StaticHostProvider#next,
public InetSocketAddress next(long spinDelay) {
++currentIndex;
if (currentIndex == serverAddresses.size()) {
currentIndex = 0;
}
if (currentIndex == lastIndex && spinDelay > 0) {
try {
Thread.sleep(spinDelay);
} catch (InterruptedException e) {
LOG.warn("Unexpected exception", e);
}
} else if (lastIndex == -1) {
// We don‘t want to sleep on the first ever connect attempt.
lastIndex = 0;
}
return serverAddresses.get(currentIndex);
}serverAddresses并不是按我们传入的字符串排列,而是在构造StaticHostProvider时就被shuffle过了,
public StaticHostProvider(Collection<InetSocketAddress> serverAddresses)
throws UnknownHostException {
for (InetSocketAddress address : serverAddresses) {
InetAddress ia = address.getAddress();
InetAddress resolvedAddresses[] = InetAddress.getAllByName((ia!=null) ? ia.getHostAddress():
address.getHostName());
for (InetAddress resolvedAddress : resolvedAddresses) {
// If hostName is null but the address is not, we can tell that
// the hostName is an literal IP address. Then we can set the host string as the hostname
// safely to avoid reverse DNS lookup.
// As far as i know, the only way to check if the hostName is null is use toString().
// Both the two implementations of InetAddress are final class, so we can trust the return value of
// the toString() method.
if (resolvedAddress.toString().startsWith("/")
&& resolvedAddress.getAddress() != null) {
this.serverAddresses.add(
new InetSocketAddress(InetAddress.getByAddress(
address.getHostName(),
resolvedAddress.getAddress()),
address.getPort()));
} else {
this.serverAddresses.add(new InetSocketAddress(resolvedAddress.getHostAddress(), address.getPort()));
}
}
}
if (this.serverAddresses.isEmpty()) {
throw new IllegalArgumentException(
"A HostProvider may not be empty!");
}
Collections.shuffle(this.serverAddresses);
}所以路由规则,就是随机策略。
不过由于ZK对于一致性的设计(见下文),写操作需要由Leader节点处理,当非Leader节点(也就是Learner)接到写请求,需要转发给Leader,当然,对Client是透明的。读请求就直接本机处理了。
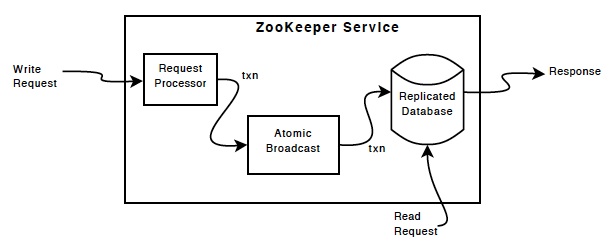
At the heart of ZooKeeper is an atomic messaging system that keeps all of the servers in sync.
所以所有服务器数据都是同步的(不过应该也只是最终一致,不是强一致,见下文),所以服务端不存在负载均衡的问题。而客户端的负载均衡,也就是服务路由,在上面已经说过了,就是随机策略。
ZK的核心其实是一个消息系统(ZAB,ZooKeeper Atomic Broadcast),用来保持ZK服务器的数据同步。大致过程如下(类似两段提交):
下面来看下每一步具体的一些点,Leader Election先跳过以后再说。Follower接收Leader消息的处理逻辑在Follower#processPacket,
protected void processPacket(QuorumPacket qp) throws IOException{
switch (qp.getType()) {
case Leader.PING:
ping(qp);
break;
case Leader.PROPOSAL:
TxnHeader hdr = new TxnHeader();
Record txn = SerializeUtils.deserializeTxn(qp.getData(), hdr);
if (hdr.getZxid() != lastQueued + 1) {
LOG.warn("Got zxid 0x"
+ Long.toHexString(hdr.getZxid())
+ " expected 0x"
+ Long.toHexString(lastQueued + 1));
}
lastQueued = hdr.getZxid();
fzk.logRequest(hdr, txn);
break;
case Leader.COMMIT:
fzk.commit(qp.getZxid());
break;
case Leader.UPTODATE:
LOG.error("Received an UPTODATE message after Follower started");
break;
case Leader.REVALIDATE:
revalidate(qp);
break;
case Leader.SYNC:
fzk.sync();
break;
}
}来看下上述第三步,Follower接收到Leader的Proposal后做了啥,FollowerZooKeeperServer#logRequest,
public void logRequest(TxnHeader hdr, Record txn) {
Request request = new Request(null, hdr.getClientId(), hdr.getCxid(),
hdr.getType(), null, null);
request.hdr = hdr;
request.txn = txn;
request.zxid = hdr.getZxid();
if ((request.zxid & 0xffffffffL) != 0) {
// 放到队列里面
pendingTxns.add(request);
}
// 接收到proposal就进行落盘操作了
syncProcessor.processRequest(request);
}也就是说,当Follower收到Leader的Proposal消息时,只是先将请求放进队列当中。下面来看下Follower收到COMMIT消息的操作,FollowerZooKeeperServer#commit,
/**
* When a COMMIT message is received, eventually this method is called,
* which matches up the zxid from the COMMIT with (hopefully) the head of
* the pendingTxns queue and hands it to the commitProcessor to commit.
* @param zxid - must correspond to the head of pendingTxns if it exists
*/
public void commit(long zxid) {
if (pendingTxns.size() == 0) {
LOG.warn("Committing " + Long.toHexString(zxid)
+ " without seeing txn");
return;
}
long firstElementZxid = pendingTxns.element().zxid;
if (firstElementZxid != zxid) {
LOG.error("Committing zxid 0x" + Long.toHexString(zxid)
+ " but next pending txn 0x"
+ Long.toHexString(firstElementZxid));
System.exit(12);
}
Request request = pendingTxns.remove();
commitProcessor.commit(request);
}commitProcessor.commit也是将请求放进队列中,
synchronized public void commit(Request request) {
if (!finished) {
if (request == null) {
LOG.warn("Committed a null!",
new Exception("committing a null! "));
return;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Committing request:: " + request);
}
committedRequests.add(request);
notifyAll();
}而CommitProcessor有个线程会将commited的消息扔给FinalRequestProcessor去执行真正的写操作。
说完Follower来看下Leader在上述第四步做了啥。Leader处理ack的代码在Leader#processAck,
/**
* Keep a count of acks that are received by the leader for a particular
* proposal
*
* @param zxid
* the zxid of the proposal sent out
* @param followerAddr
*/
synchronized public void processAck(long sid, long zxid, SocketAddress followerAddr) {
if (LOG.isTraceEnabled()) {
LOG.trace("Ack zxid: 0x{}", Long.toHexString(zxid));
for (Proposal p : outstandingProposals.values()) {
long packetZxid = p.packet.getZxid();
LOG.trace("outstanding proposal: 0x{}",
Long.toHexString(packetZxid));
}
LOG.trace("outstanding proposals all");
}
if ((zxid & 0xffffffffL) == 0) {
/*
* We no longer process NEWLEADER ack by this method. However,
* the learner sends ack back to the leader after it gets UPTODATE
* so we just ignore the message.
*/
return;
}
if (outstandingProposals.size() == 0) {
if (LOG.isDebugEnabled()) {
LOG.debug("outstanding is 0");
}
return;
}
// 已commit的proposal
if (lastCommitted >= zxid) {
if (LOG.isDebugEnabled()) {
LOG.debug("proposal has already been committed, pzxid: 0x{} zxid: 0x{}",
Long.toHexString(lastCommitted), Long.toHexString(zxid));
}
// The proposal has already been committed
return;
}
// 记录proposal的ack
Proposal p = outstandingProposals.get(zxid);
if (p == null) {
LOG.warn("Trying to commit future proposal: zxid 0x{} from {}",
Long.toHexString(zxid), followerAddr);
return;
}
p.ackSet.add(sid);
if (LOG.isDebugEnabled()) {
LOG.debug("Count for zxid: 0x{} is {}",
Long.toHexString(zxid), p.ackSet.size());
}
// 是否达到Quorum要求
if (self.getQuorumVerifier().containsQuorum(p.ackSet)){
if (zxid != lastCommitted+1) {
LOG.warn("Commiting zxid 0x{} from {} not first!",
Long.toHexString(zxid), followerAddr);
LOG.warn("First is 0x{}", Long.toHexString(lastCommitted + 1));
}
outstandingProposals.remove(zxid);
if (p.request != null) {
toBeApplied.add(p);
}
if (p.request == null) {
LOG.warn("Going to commmit null request for proposal: {}", p);
}
// 给follower发送COMMIT消息
commit(zxid);
// 给observer发送INFORM消息
inform(p);
// leader本地也要提交
zk.commitProcessor.commit(p.request);
if(pendingSyncs.containsKey(zxid)){
for(LearnerSyncRequest r: pendingSyncs.remove(zxid)) {
sendSync(r);
}
}
}
}Quorum有两种实现,默认是QuorumMaj,只要大于一半就算通过。另一种是带权重的实现,QuorumHierarchical。
接下来看下什么情况下会触发Leader的重新选举。最简单的,假如当前Leader节点挂掉了,Follower的主循环会结束,然后回到QuorumPeer的主循环并且将节点状态设置为ServerState.LOOKING,接下来就会进行下一波Leader Election了。另外,Leader的主循环会一直去检测当前Follower的数量是否满足Quorum要求,如果不满足也会将自己与Learner的连接关闭,并设置状态为ServerState.LOOKING,当然也会触发下一波Leader Election了。
while (true) {
Thread.sleep(self.tickTime / 2);
if (!tickSkip) {
self.tick++;
}
HashSet<Long> syncedSet = new HashSet<Long>();
// lock on the followers when we use it.
syncedSet.add(self.getId());
for (LearnerHandler f : getLearners()) {
// Synced set is used to check we have a supporting quorum, so only
// PARTICIPANT, not OBSERVER, learners should be used
// f.synced()会使用syncLimit配置项
if (f.synced() && f.getLearnerType() == LearnerType.PARTICIPANT) {
syncedSet.add(f.getSid());
}
f.ping();
}
if (!tickSkip && !self.getQuorumVerifier().containsQuorum(syncedSet)) {
//if (!tickSkip && syncedCount < self.quorumPeers.size() / 2) {
// Lost quorum, shutdown
shutdown("Not sufficient followers synced, only synced with sids: [ "
+ getSidSetString(syncedSet) + " ]");
// make sure the order is the same!
// the leader goes to looking
return;
}
tickSkip = !tickSkip;
}有多少Learner就会维护多少条LearnerHandler线程。
ZK3.5版本之前,扩容是很蛋疼的事情,需要rolling restart。到了3.5版本,终于可以进行动态配置。在原来的静态配置文件中,增加了一个配置项,dynamicConfigFile,例子如下,
## zoo_replicated1.cfg
tickTime=2000
dataDir=/zookeeper/data/zookeeper1
initLimit=5
syncLimit=2
dynamicConfigFile=/zookeeper/conf/zoo_replicated1.cfg.dynamic## zoo_replicated1.cfg.dynamic
server.1=125.23.63.23:2780:2783:participant;2791
server.2=125.23.63.24:2781:2784:participant;2792
server.3=125.23.63.25:2782:2785:participant;2793运行时通过reconfig命令可以修改配置。实现的逻辑也很简单,就是将配置存在了一个特殊的znode,/zookeeper/config。
另外当扩容后,可以通过ZooKeeper#updateServerList对客户端的连接进行rebalance,背后使用了一个概率算法,要达到的效果就是,既能减少连接的迁移,又能做到负载均衡,如果只是简单的重新shuffle一下扩容后的服务器进行重连,那么迁移的成本就有点高了。
ZK的数据文件参考之前的文章。
操作日志文件的实现是FileTxnLog,格式说明如下,
/**
* This class implements the TxnLog interface. It provides api‘s
* to access the txnlogs and add entries to it.
* <p>
* The format of a Transactional log is as follows:
* <blockquote><pre>
* LogFile:
* FileHeader TxnList ZeroPad
*
* FileHeader: {
* magic 4bytes (ZKLG)
* version 4bytes
* dbid 8bytes
* }
*
* TxnList:
* Txn || Txn TxnList
*
* Txn:
* checksum Txnlen TxnHeader Record 0x42
*
* checksum: 8bytes Adler32 is currently used
* calculated across payload -- Txnlen, TxnHeader, Record and 0x42
*
* Txnlen:
* len 4bytes
*
* TxnHeader: {
* sessionid 8bytes
* cxid 4bytes
* zxid 8bytes
* time 8bytes
* type 4bytes
* }
*
* Record:
* See Jute definition file for details on the various record types
*
* ZeroPad:
* 0 padded to EOF (filled during preallocation stage)
* </pre></blockquote>
*/至于快照文件,之前已经介绍过通过修改源码输出XML格式来看看了。
标签:zookeeper
原文地址:http://blog.csdn.net/kisimple/article/details/44116519