标签:
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-class.html,转载请注明源地址。
hadoop中自带的org.apache.hadoop.io包中有广泛的writable类可供选择,它们形成下图所示的层次结构:
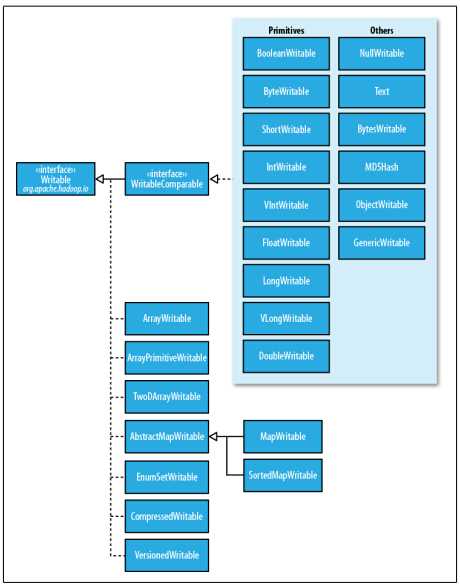
java基本类型的Writable封装器
Writable类对java基本类型提供封装,short和char除外,所有的封装包含get()和set()两个方法用于读取或设置封装的值
java基本类型的Writable类

除char类型以外,所有的原生类型都有对应的Writable类,并且通过get和set方法可以他们的值。IntWritable和LongWritable还有对应的变长VIntWritable和VLongWritable类。固定长度还是变长的选用类似与数据库中的char或者vchar,在这里就不赘述了。
Text类型使用变长int型存储长度,所以Text类型的最大存储为2G.
Text类型采用标准的utf-8编码,所以与其他文本工具可以非常好的交互,但要注意的是,这样的话就和java的String类型差别就很多了。
检索的不同
Text的chatAt返回的是一个整型,及utf-8编码后的数字,而不是象String那样的unicode编码的char类型。
public void testTextIndex(){ Text text=new Text("hadoop"); Assert.assertEquals(text.getLength(), 6); Assert.assertEquals(text.getBytes().length, 6); Assert.assertEquals(text.charAt(2),(int)‘d‘); Assert.assertEquals("Out of bounds",text.charAt(100),-1); }
Text还有个find方法,类似String里indexOf方法:
public void testTextFind() { Text text = new Text("hadoop"); Assert.assertEquals("find a substring",text.find("do"),2); Assert.assertEquals("Find first ‘o‘",text.find("o"),3); Assert.assertEquals("Find ‘o‘ from position 4 or later",text.find("o",4),4); Assert.assertEquals("No match",text.find("pig"),-1); }
当uft-8编码后的字节大于两个时,Text和String的区别就会更清晰,因为String是按照unicode的char计算,而Text是按照字节计算。我们来看下1到4个字节的不同的unicode字符

4个unicode分别占用1到4个字节,u+10400在java的unicode字符重占用两个char,前三个字符分别占用1个char.
我们通过代码来看下String和Text的不同
import java.io.*; import org.apache.hadoop.io.*; import org.apache.hadoop.util.StringUtils; import junit.framework.Assert; public class textandstring { public static void string() throws UnsupportedEncodingException { String str = "\u0041\u00DF\u6771\uD801\uDC00"; Assert.assertEquals(str.length(), 5); Assert.assertEquals(str.getBytes("UTF-8").length, 10); Assert.assertEquals(str.indexOf("\u0041"), 0); Assert.assertEquals(str.indexOf("\u00DF"), 1); Assert.assertEquals(str.indexOf("\u6771"), 2); Assert.assertEquals(str.indexOf("\uD801\uDC00"), 3); Assert.assertEquals(str.charAt(0), ‘\u0041‘); Assert.assertEquals(str.charAt(1), ‘\u00DF‘); Assert.assertEquals(str.charAt(2), ‘\u6771‘); Assert.assertEquals(str.charAt(3), ‘\uD801‘); Assert.assertEquals(str.charAt(4), ‘\uDC00‘); Assert.assertEquals(str.codePointAt(0), 0x0041); Assert.assertEquals(str.codePointAt(1), 0x00DF); Assert.assertEquals(str.codePointAt(2), 0x6771); Assert.assertEquals(str.codePointAt(3), 0x10400); } public static void text() { Text text = new Text("\u0041\u00DF\u6771\uD801\uDC00"); Assert.assertEquals(text.getLength(), 10); Assert.assertEquals(text.find("\u0041"), 0); Assert.assertEquals(text.find("\u00DF"), 1); Assert.assertEquals(text.find("\u6771"), 3); Assert.assertEquals(text.find("\uD801\uDC00"), 6); Assert.assertEquals(text.charAt(0), 0x0041); Assert.assertEquals(text.charAt(1), 0x00DF); Assert.assertEquals(text.charAt(3), 0x6771); Assert.assertEquals(text.charAt(6), 0x10400); } public static void main(String[] args) { // TODO Auto-generated method stub text(); try { string(); } catch(UnsupportedEncodingException ex) { } } }
这样一比较就很明显了。
1.String的length()方法返回的是char的数量,Text的getLength()方法返回的是字节的数量。
2.String的indexOf()方法返回的是以char为单元的偏移量,Text的find()方法返回的是以字节为单位的偏移量。
3.String的charAt()方法不是返回的整个unicode字符,而是返回的是java中的char字符
4.String的codePointAt()和Text的charAt方法比较类似,不过要注意,前者是按char的偏移量,后者是字节的偏移量
在Text中对unicode字符的迭代是相当复杂的,因为与unicode所占的字节数有关,不能简单的使用index的增长来确定。首先要把Text对象转换为java.nio.ByteBuffer对象,然后再利用缓冲区对Text对象反复调用bytesToCodePoint方法,该方法能获取下一代码的位置,并返回相应的int值,最后更新缓冲区中的位置。通过bytesToCodePoint()方法可以检测出字符串的末尾,并返回-1值。看一下示例代码:
import java.io.*; import java.nio.ByteBuffer; import org.apache.hadoop.io.*; import org.apache.hadoop.util.StringUtils; import junit.framework.Assert; public class textandstring { public static void main(String[] args) { // TODO Auto-generated method stub Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00"); ByteBuffer buf = ByteBuffer.wrap(t.getBytes(), 0, t.getLength()); int cp; while(buf.hasRemaining() && (cp = Text.bytesToCodePoint(buf)) != -1) { System.out.println(Integer.toHexString(cp)); } } }
运行结果:
41
df
6771
10400
标签:
原文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-class.html