标签:
SSAS的维度特性(Attribute)有以下三个属性(Property):KeyColumn, NameColumn, ValueColumn,下图所示为AW的Date维度对这三个Column属性的设置,而我们利用向导生成的维度默认只有KeyColumn设置,如果没有手动设置NameColumn的话,其值默认等于KeyColumn,如果没有手动设置ValueColumn的话,其值默认等于NameColumn。通常来说维度表数据量不大时使用向导生成SSAS维度不会有什么问题,而如果维度表数据量稍大,例如上千万级别的维度表,就不得不好好优化下了。
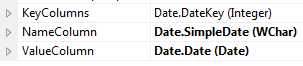
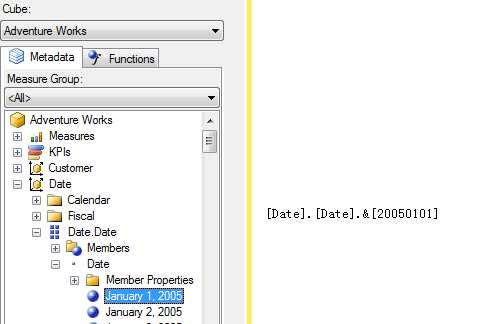
首先我们得先理解这三个Column属性,在SSMS里打开一个MDX查询,数据源是AW Cube, 展开Date维度,定位到一个Date成员[January 1, 2005],并拖放到右边的脚本编辑窗口,可以看到生成的脚本是[Date].[Date].&[20050101],数据源展现的成员名称[January 1, 2005]就是NameColumn,拖出来生成的脚本显示的成员名称[20050101]就是KeyColumn。
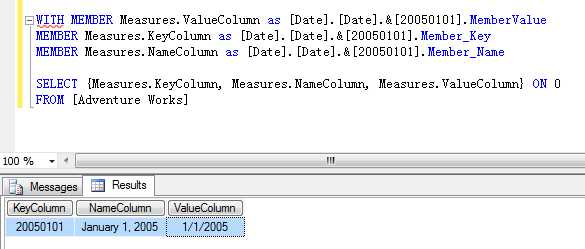
我们再执行下面一段脚本,看到[Date].[Date].&[20050101]这个成员的三个Column属性对应的值如图所示
WITH MEMBER Measures.ValueColumn as [Date].[Date].&[20050101].MemberValue
MEMBER Measures.KeyColumn as [Date].[Date].&[20050101].Member_Key
MEMBER Measures.NameColumn as [Date].[Date].&[20050101].Member_Name
SELECT {Measures.KeyColumn, Measures.NameColumn, Measures.ValueColumn} ON 0
FROM [Adventure Works]
再对比下属性编辑框里的设置来理解
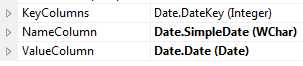
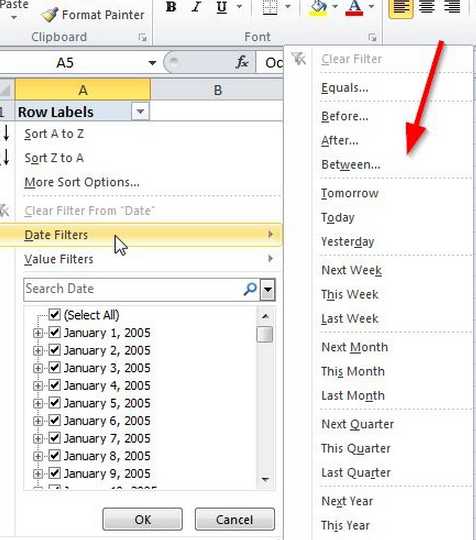
我们看到KeyColumn是int整型,用于唯一标识维度属性的成员;NameColumn是WChar字符串,用于在客户端为用户展现friendly的名称;ValueColumn是Date日期类型,通常用于存储额外信息以便创建Calculation时使用,也可用于客户端做智能分析,例如设置ValueColumn为Date日期类型时,Excel客户端右键菜单里会多出一个Date Filters的日期智能过滤菜单
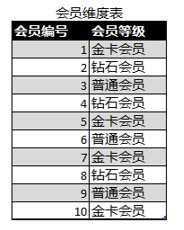
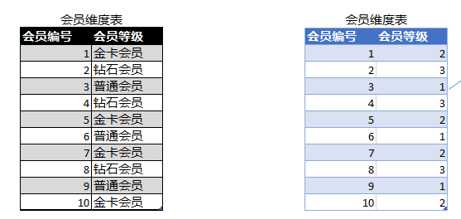
假设我们有下面这么一张会员维度表,并按向导生成默认的SSAS维度,那么会员等级(DimAccount.tier_varchar)这个属性的三个Column默认设置如下,KeyColumn是字符串类型,NameColumn和ValueColumn未做设置,默认等于KeyColumn
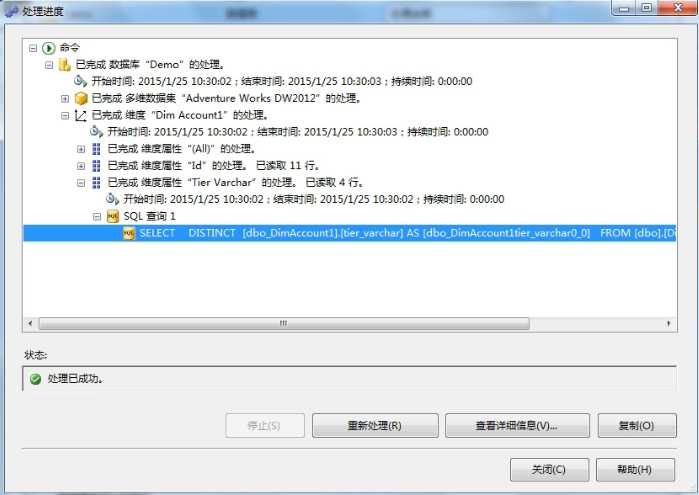
再来看下处理这个维度时需要去数据库做什么事情,复制下图所示的脚本到SSMS,看到是要对会员维度表的会员等级字段进行去重查询

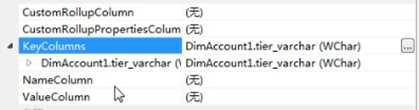
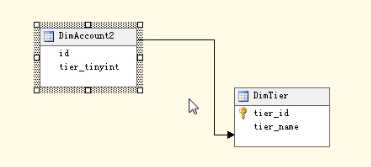
接下来我们对会员维度表做一些改动,把数据结构修改成下图所示的效果,会员等级不再使用varchar类型,改用tinyint,并添加一张字典表,记录下每个会员等级编号对应的等级名称

如果数据库里没有设置这两张表的主外键关系的话,可以在SSAS数据源视图里指定关系如下
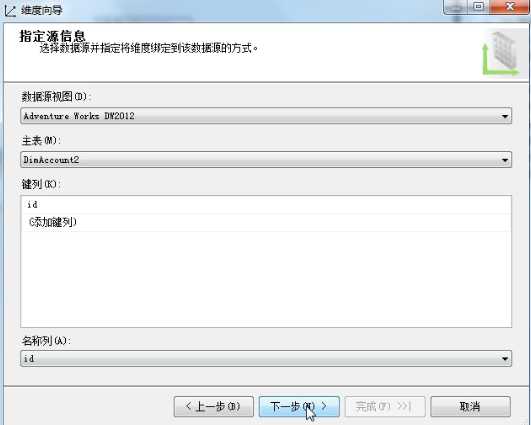
创建DimAccount2维度时,向导会提示存在相关表DimTier,默认勾选不做改动
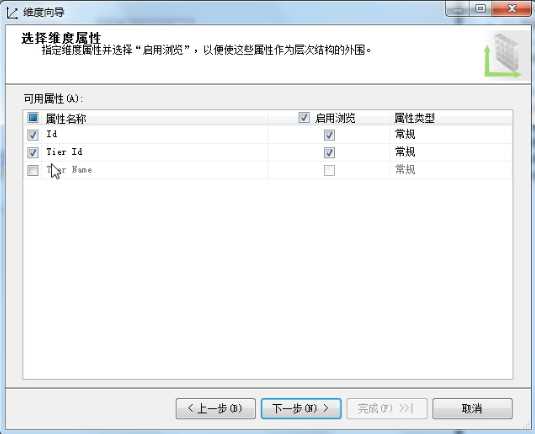
在进行到选取可用属性时,保持默认只选中Tier Id不做改动,切记不要选中Tier Name,主要就是想用这个tinyint类型的Tier Id,后面可以将其改名为Tier Name
下图为向导生成的DimAccount2维度Tier属性的三个Column设置,看到KeyColumn为tinyint类型,NameColumn和ValueColumn默认为空,如果此时部署处理维度,那么客户端展现的Tier将都是数字,不具备可读性,所以这里我们要设置下NameColumn,指定名称列为tier_name,如此才能保证客户端能够展现出可读性的Tier

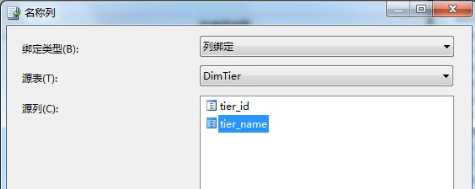

我们再看下处理DimAccount2维度时需要去数据库做什么事情,拷贝处理Tier Name(其实是Tier Id了)的脚本出来
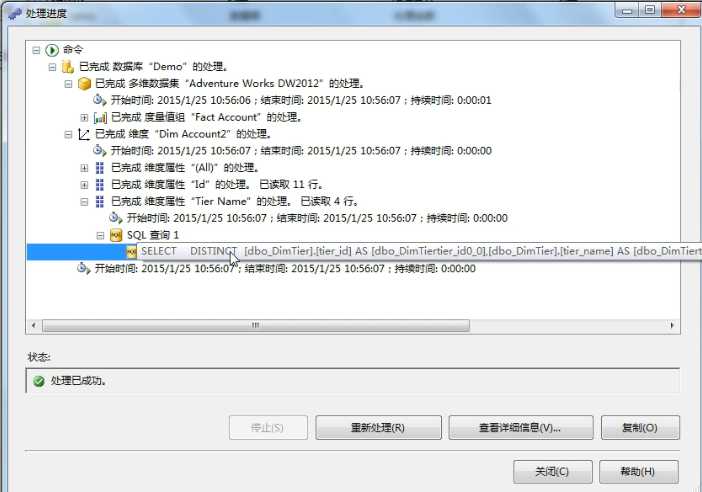
可以看到不同于DimAccount1的是,这里仅仅是对DimTier这张字典表的tier_id, tier_name进行去重查询,相对于会员表来说,这张字典表实在是小的可爱

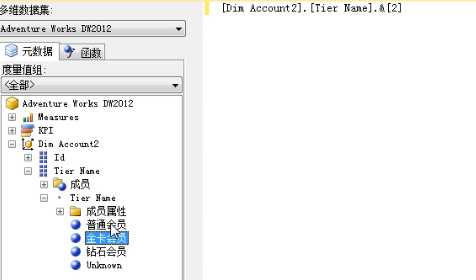
去SSMS里验证下,拖出金卡会员到脚本编辑框,看到显示的是[Tier Name].&[2],说明SSAS Dimension数据存储的确实是tinyint类型,直到需要客户端展现时才mapping到对应的Name字符串,这个mapping正是从Tier字典表检索到Name的。
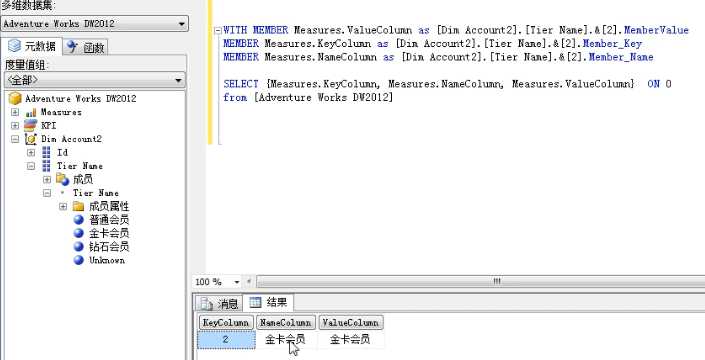
再用With Member验证下
我们来理解下优化原理,首先,要处理(process full)这两张会员维度表,是必须要去rdbms数据源做全表读取的,假设会员表有一千万行记录,并且类似会员等级这样的字段有10个,那么粗略一算,第一张以字符串设计的会员表需要占用磁盘800M的空间(未做表压缩),而第二张以tinyint设计的会员表仅仅占用100M的空间,也就是说SSAS要去数据库执行这两张会员表的全表查询,分别需要去磁盘读取800M和100M的数据,这个磁盘开销就有8倍之差了,之后数据加载到buffer pool内存缓冲区里,又会分别产生数倍之差的内存开销,最后再把这些数据处理到SSAS Cube Dimension里(也是磁盘文件),再次产生不等额的磁盘开销,此外还有Distinct去重计算,前者需要对会员维度这张大表做Tier去重,后者只需要对会员等级这张小的字典表做去重,显然运算量是不同重量级的,这些还只是处理过程中的开销,也许你是在夜里做的处理,不怎么care这些,那么查询的性能总归是要关心下的吧,Dimension Size必然也是会影响查询性能的。
补充一点,切忌滥用此优化方案,变字符串类型为较小的数字类型是为了节省空间,从而降低磁盘和内存开销,只有在重复度较高的字段上使用才有意义,如果字段本身的重复度很低,这么做反而会适得其反。

最后看下SSAS Performance Guide白皮书里怎么描述这个Benefits:
SSAS & Excel BI Tips正篇之二:性能调优之KeyColumn & NameColumn
标签:
原文地址:http://www.cnblogs.com/xpivot/p/4334759.html