标签:
在上篇博客中,我们搭建了《配置高可用Hadoop平台》,接下来我们就可以驾着Hadoop这艘巨轮在大数据的海洋中遨游了。工欲善其事,必先利其器。是的,没错;我们开发需要有开发工具(IDE);本篇文章,我打算讲解如何搭建和使用开发环境,以及编写和讲解WordCount这个例子,给即将在Hadoop的海洋驰骋的童鞋入个门。上次,我在《网站日志统计案例分析与实现》中说会将源码放到Github,后来,我考虑了下,决定将《高可用的Hadoop平台》做一个系列,后面基于这个平台,我会单独写一篇来赘述具体的实现过程,和在实现过程中遇到的一些问题,以及解决这些问题的方案。下面我们开始今天的启航。
IDE:JBoss Developer Studio 8.0.0.GA (Eclipse的升级版,Redhat公司出的)
JDK:1.7(或1.8)
Hadoop2x-eclipse-plugin:这个插件,本地单元测试或自己做学术研究比较好用
插件下载地址:https://github.com/smartdengjie/hadoop2x-eclipse-plugin
由于JBoss Developer Studio 8基本适合于Retina屏,所以,我们这里直接使用JBoss Developer Studio 8,JBoss Developer Studio 7对Retina屏的支持不是很完美,这里就不赘述了。
附上一张IDE的截图:

下面我们开始安装插件,首先展示首次打开的界面,如下图所示:
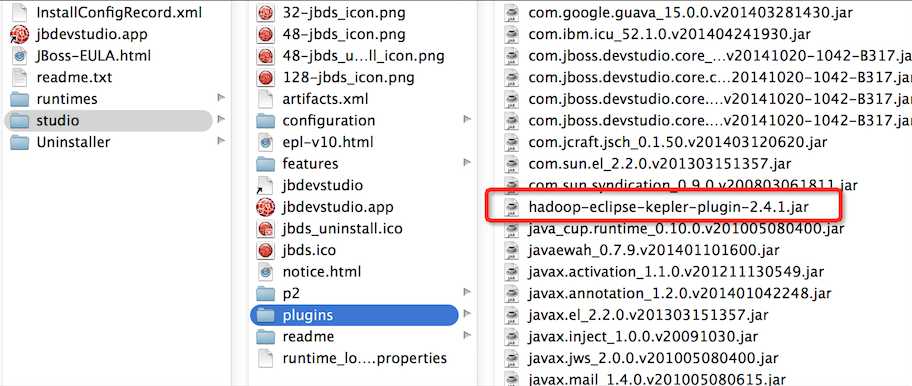
然后,我们到上面给的Github的地址,clone整个工程,里面有编译好的jar和源码,可自行选择(使用已存在的和自己编译对应的版本),这里我直接使用编译好的版本。我们将jar放到IDE的plugins目录下,如下图所示:
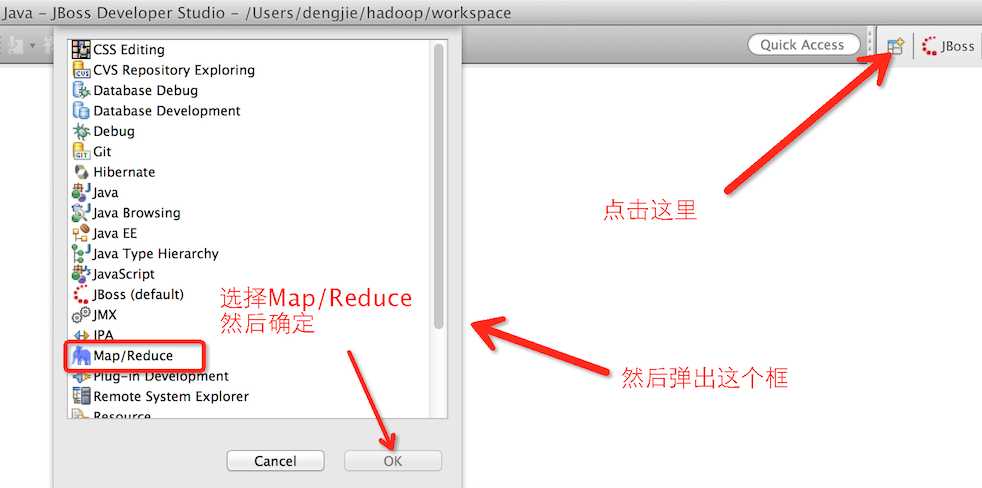
接着,我们重启IDE,界面出现如下图所示的,即表示插件添加成功,若没有,查看IDE的启动日志,根据异常日志定位出原因。
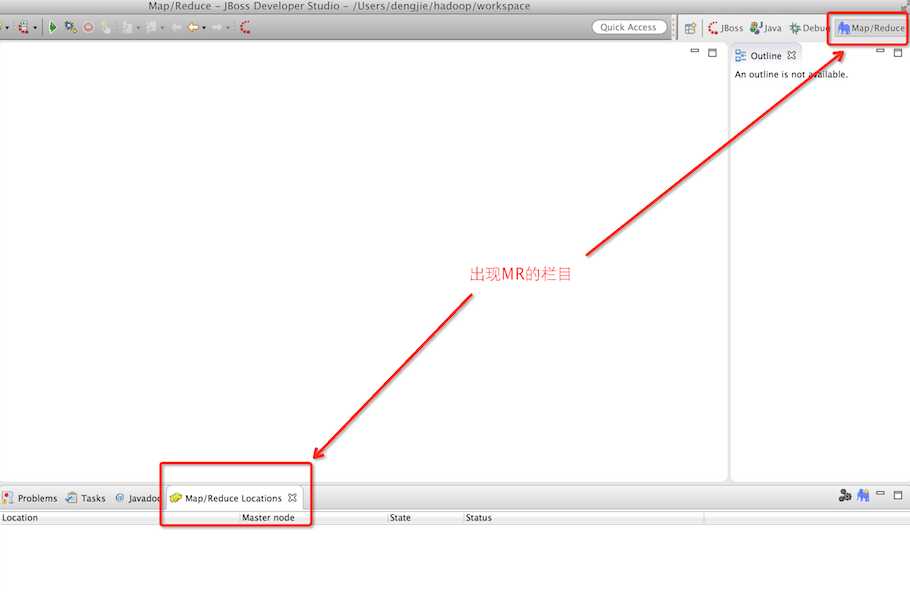
配置信息如下所示(已在图中说明):
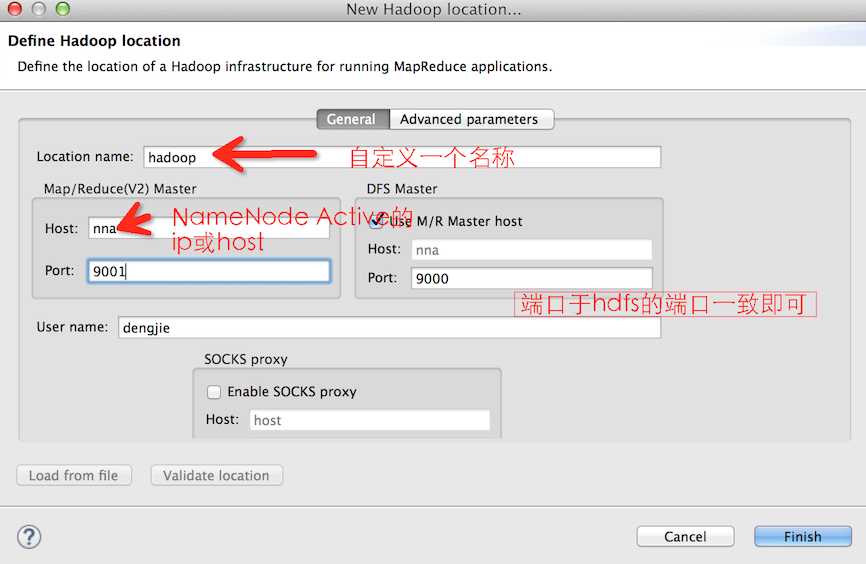
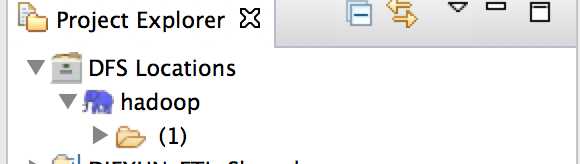
添加本地的hadoop源码目录:
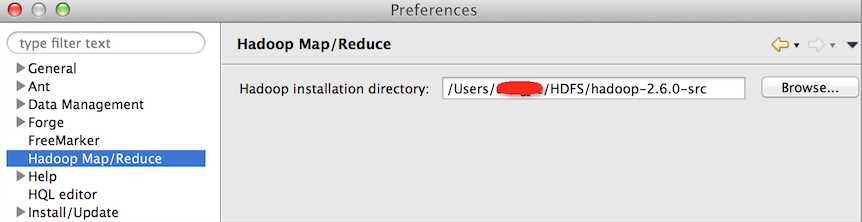
到这里,IDE和插件的搭建就完成了,下面我们进入一段简单的开发,hadoop的源码中提供了许多example让我学习,这里我以WordCount为例子来说明:
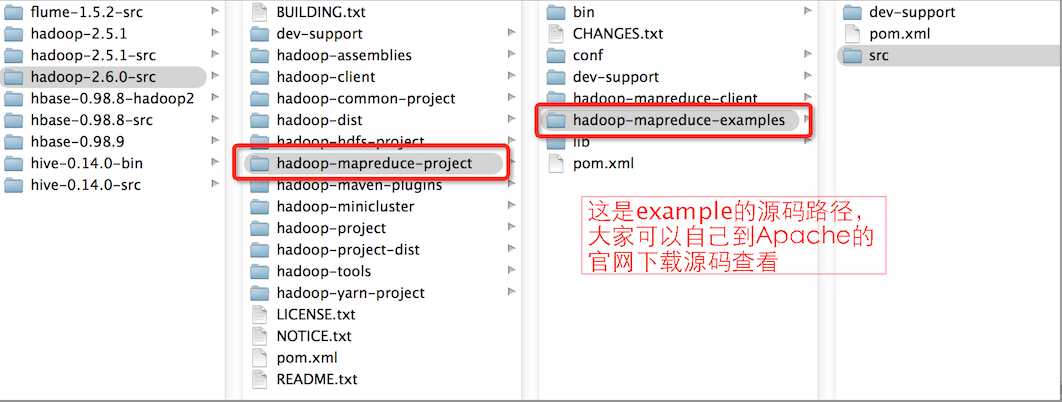
首先我们看下hadoop的源码文件目录,如下图所示:
package cn.hdfs.mr.example; import java.io.IOException; import java.util.Random; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import cn.hdfs.utils.ConfigUtils; /** * * @author dengjie * @date 2015年03月13日 * @description Wordcount的例子是一个比较经典的mapreduce例子,可以叫做Hadoop版的hello world。 * 它将文件中的单词分割取出,然后shuffle,sort(map过程),接着进入到汇总统计 * (reduce过程),最后写道hdfs中。基本流程就是这样。 */ public class WordCount { private static Logger log = LoggerFactory.getLogger(WordCount.class); public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); /* * 源文件:a b b * * map之后: * * a 1 * * b 1 * * b 1 */ public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString());// 整行读取 while (itr.hasMoreTokens()) { word.set(itr.nextToken());// 按空格分割单词 context.write(word, one);// 每次统计出来的单词+1 } } } /* * reduce之前: * * a 1 * * b 1 * * b 1 * * reduce之后: * * a 1 * * b 2 */ public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } @SuppressWarnings("deprecation") public static void main(String[] args) throws Exception { Configuration conf1 = new Configuration(); Configuration conf2 = new Configuration(); long random1 = new Random().nextLong();// 重定下输出目录1 long random2 = new Random().nextLong();// 重定下输出目录2 log.info("random1 -> " + random1 + ",random2 -> " + random2); Job job1 = new Job(conf1, "word count1"); job1.setJarByClass(WordCount.class); job1.setMapperClass(TokenizerMapper.class);// 指定Map计算的类 job1.setCombinerClass(IntSumReducer.class);// 合并的类 job1.setReducerClass(IntSumReducer.class);// Reduce的类 job1.setOutputKeyClass(Text.class);// 输出Key类型 job1.setOutputValueClass(IntWritable.class);// 输出值类型 Job job2 = new Job(conf2, "word count2"); job2.setJarByClass(WordCount.class); job2.setMapperClass(TokenizerMapper.class); job2.setCombinerClass(IntSumReducer.class); job2.setReducerClass(IntSumReducer.class); job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(IntWritable.class); // FileInputFormat.addInputPath(job, new // Path(String.format(ConfigUtils.HDFS.WORDCOUNT_IN, "test.txt"))); // 指定输入路径 FileInputFormat.addInputPath(job1, new Path(String.format(ConfigUtils.HDFS.WORDCOUNT_IN, "word"))); // 指定输出路径 FileOutputFormat.setOutputPath(job1, new Path(String.format(ConfigUtils.HDFS.WORDCOUNT_OUT, random1))); FileInputFormat.addInputPath(job2, new Path(String.format(ConfigUtils.HDFS.WORDCOUNT_IN, "word"))); FileOutputFormat.setOutputPath(job2, new Path(String.format(ConfigUtils.HDFS.WORDCOUNT_OUT, random2))); boolean flag1 = job1.waitForCompletion(true);// 执行完MR任务后退出应用 boolean flag2 = job1.waitForCompletion(true); if (flag1 && flag2) { System.exit(0); } else { System.exit(1); } } }
这篇文章就和大家分享到这里,如果在研究的过程有什么问题,可以加群讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
标签:
原文地址:http://www.cnblogs.com/smartloli/p/4335171.html