标签:
最近在公司搞一个项目重构迁移问题,旧项目一直在线上跑,重构的项目则还没上线。重构之后数据库表结构,字段,类型等都有变化,而且重构的数据库由oracl改为mysql。这样就设计到数据迁移问题,别人推荐下用了kettle。由于资料比较少,刚开始搞了半天没成功过一次。现在终于有点开窍了,记录下以备后用,同时给用到的同学一点帮助也好,现在还是刚用的第二天,所以写的太浅显,望莫耻笑。
1、数据类型转换
由于大多数的数据结构都差不多,所以大多转换就如下图所示:
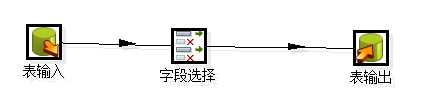
如果有字段变化在在“字段选择”中做映射,如我原来库中字段为UUID,在新库中字段叫ID

由于新的mysql中所有日期类型都采用时间戳来存储,所以在数据转换的时候也要考虑。这里在查询数据的时候,也就是“表输入”时候进行数据转换,首先写了一个oracle的函数:
create or replace function oracle_to_unix(in_date IN DATE) return number is begin return( (in_date -TO_DATE(‘19700101‘,‘yyyymmdd‘))*86400 - TO_NUMBER(SUBSTR(TZ_OFFSET(sessiontimezone),1,3))*3600); end oracle_to_unix;
然后在查询数据的时候调用此函数进行转换:
select oracle_to_unix(CREATE_DATE) as create_date from t_1
这样就完成了oracle date类型到时间戳的转换了。
2、增加ID
在老的系统上有需要表都没有ID,这样在迁移数据的时候就需要同时生成ID,这里采用的是kellten“增加序列”来自动生成ID,转换过程如下
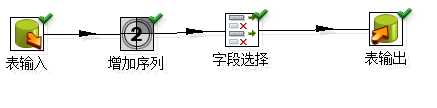
在增加序列中“值的名称”填入“表输出”中表的ID字段名称,或者随便写一个,在“字段选择”中进行映射即可,这里我直接写的ID。

3、性能提升
在测试迁移过程中,一开始的数据速度竟然是20多条/s,真是让人抓狂,3000W的数据这要迁移到明年了。。。,网上搜索了下,修改如下链接参数可以提高效率:
useServerPrepStmts=false rewriteBatchedStatements=true useCompression=true
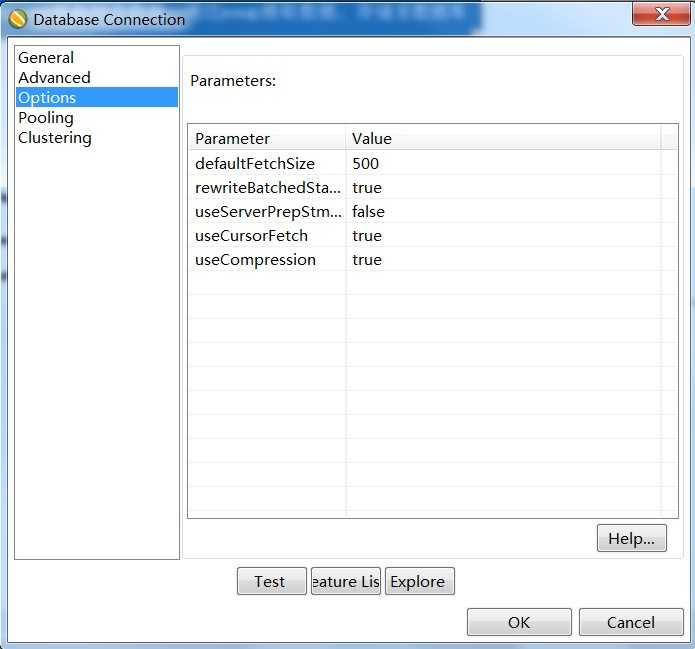
设置上试了下果然是鸟枪换炮啊,立马速度增加到2000条/S
暂时记录到此,后续有问题再更新。
标签:
原文地址:http://www.cnblogs.com/lcxdever/p/4335358.html