标签:
摘要:论文总结了近十年来partial retrieval of 3D shape的进展,给初学者一个初步的概念,并且将现有的方法按照不同的策略分类并分析了这些方法的特点,最后讨论了今后的发展方向。
1 绪论
介绍了partial retrieval的用途和研究进展,给出了流行的数据库。简要描述了global matching和partial matching的区别,也就是global matching考虑的是全局相似性,而partial matching忽略全局相似性而关注部分相似性。所以partial matching的难点就在于如何将3D模型分成有意义的部分。
2 定义
part-in-whole retrieval:目标为确定一个输入的形状是否为某一形状的一部分。
whole-in-whole retrieval by partial similarity: 通过匹配两个形状的部分相似性来确定全局的相似性。
算法特性需求(有效、高效且鲁棒):对不同类型的模型使用;转换不变;deformation 不变;高效且紧凑地提取局部几何特征;良好的数据结构以得到快速匹配的效果。
3 方法分类
基于局部描述子的方法:获取局部点的小的领域上的信息。然后计算没两个不同局部算子的相似度。可以用于拓扑复杂的模型,搜索的面片可以随机选择,不需要分割。
基于分段的方法:通过将3D准确的分成有意义的段(segmentation),然后计算每一个段的信息以及整体的结构信息。与人的直观想法相匹配。
基于视图的方法:从均匀分布的视点(也可以是不均匀的,例如视点熵等方法,Sipin注)生成3D模型的二维图形。然后匹配二维图形的相似度。支持2D图形作为检索输入(query)。
4 基于局部算子的部分匹配检索
局部描述子可以是从mesh的点计算的标量或者矢量。不同于描述3D形状的全局描述子,局部算子是基于一个点的局部区域的。所以他对局部的变形更加敏感,并且稳定地提取会更加困难。
决定局部区域的方式:欧式距离(易于计算,只需计算在以分析点为圆心的圆内的顶点)、测地环、局部视图上的点、无结构点云的K-最近邻点。
另外一个问题是怎样定义表面上点的描述子。关键是要找到视觉显著点,也在就是在形状突出的位置具有较大值,而在表面平缓的位置有较小值。
4.1 局部算子
Spin Image:由(p,n)计算得到
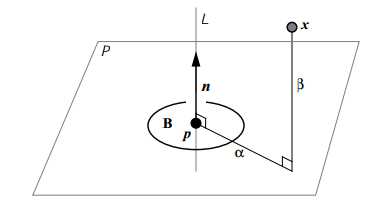
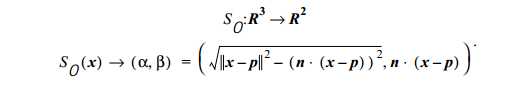
spin image的方法被证明是适用于表面缺失的检索。
Snapshot Descriptor:
Local Spherical Harmonics Descriptor:构建以质心为圆心的不同半径的同心圆,交于mesh表面。一个二进制的方程用来判断表面是否与圆相交。球面方程被分解为不同频率向量的harmonic function,用来描述分析点的局部区域。算子对旋转和平移变换鲁棒,但受非刚体变形影响。
Laplace-Beltrami Descriptor:先定义采样点的近邻区域。固定的面积-比值搜索策略用来规定尺度。局部区域的较大的特征值用来构建局部描述子。
Laplace-Beltrami:简言之就是实数函数的梯度的散度。具有对isomatric不变的特性。http://en.wikipedia.org/wiki/Spectral_shape_analysis
Heat Kernel Descriptor:同样是在表面使用Laplace-Beltrami算子。首先在表面以一个容易控制的尺度获取局部区域,然后计算Laplace-Beltrami算子值较大的特征值。这样就使得计算更加高效。缺点是不能够处理不同尺度的形状,所以需要预先尺度归一化。http://en.wikipedia.org/wiki/Heat_kernel_signature
3D Extension from Classical 2D Descriptor:列举了一些从2D算子扩展到3D算子的例子,如3D Harris,Mesh-DoG and HoG, geodesic scale space DoG, 3D SURF,Shape MSER, and 3D shape context, and 3D SIFT。
3D 算子的组合方式:
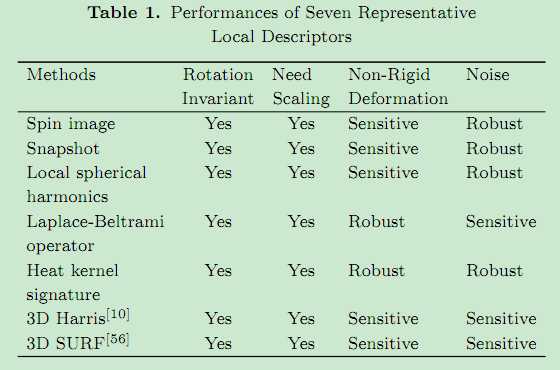
Disscussion:上述方法的特点如下表所示:
4.2 局部描述子的部分相似度度量
直接将成对的顶点进行比较会导致cost指数型增长。
Sparse Comparison:仅仅比较显著点会加快速度。于是有了计算表面上测地尺度空间的极值的方法。
Multi-Layer Comparison:以与分析点的距离为标准来分层计算相似度,这样就有效提高了效率。
Iterative Closest Point:通过降低不匹配的点对的权重来寻找最佳对应(correspondence)。
Descriptor Clustering and Vector Quantization:利用如K-means等方法来聚类相似的局部描述子。通过聚类结果来确定某特征属于哪一聚类中心。
Bag of Feature:灵感来自于Bag of Word。将特征统计为codeword,然后聚类,计算某一特征最近的codeword,统计特征到直方图。最终转化为直方图的比较。
Discussion:上述算法的提出是为了避免many-to-many的匹配。
5. 基于分段的部分形状检索
5.1 部分的定义
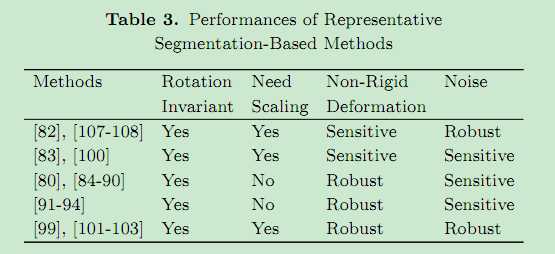
下表列出了各种分段方法的缺陷

5.2 部分的标记
从得到的部分中提取出特征
5.3 部分的组织
通过图、哈希表、词库、字典的方式来构建部分间的拓扑关系。
Subgraph Isomorphism:在整体图中搜索部分就转化为在更大的图中找到相等的子图。该方法但对于轻微的拓扑差异敏感。
Hash Table,Thesaurus and Vocabulary: 计算与Bag of words中的特征最接近的并将该query的特征归为该聚类中心。
Discussion:方法比较如下表所示:
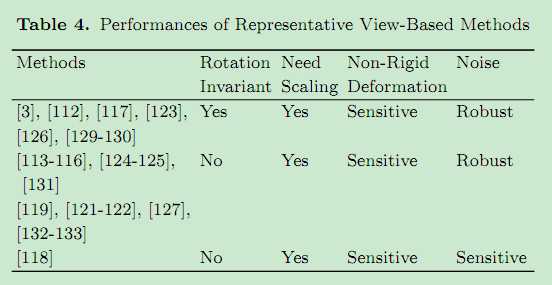
6. 基于视图的部分形状匹配
生成一系列的2D图像,将问题转化为2D图像的比较。
Discussion:基于视图的方法支持2D图像检索,2D手绘草图检索,扫描范围检索。2D检索的方法可以用在这种方法中。下表记录了基于视图的方法比较:
7. Conclusions
Evaluation:常见的评价标准:RP,NN,FT,ST,EM,DCG,NDCG。
Trends:(1)提高准确度。(2)在场景中识别出物体。(3)建立低层几何特征和高层语义信息间的关系。
[论文]A survey on partial retrieval of 3D shape
标签:
原文地址:http://www.cnblogs.com/sipin/p/4330332.html