标签:
前文 .NET框架源码解读之MYC编译器 和 MYC编译器源码分析之程序入口 分别讲解了 SSCLI 里示例编译器的架构和程序入口,本文接着分析它的词法分析部分的代码。
词法解析的工作都由Tok类处理,其构造函数接受一个Io对象做文件处理,下面是Tok构造函数的源码:
public Tok(Io ihandle) { io = ihandle; // 初始化Token(字符归类)字典 InitHash(); // initialize the tokens hashtable // 读入文件的第一个字符 io.ReadChar(); // 逐个扫描文件里的字符,获取 // 第一个字符归类(Token) scan(); }
构造函数中第一个函数调用InitHash的目的是将关键字和操作符解析成更容易识别的字符类型识别号 - Token,这样做的目的是为了便于语法解析器parser处理。例如,对于下面这条C语句:
int foo(int a)
与其让语法解析器去逐个处理单个字符,词法解析器的作用是将去上面一行语句归类成类似下面的格式:
T_INT T_IDENT ‘(‘ T_INT T_IDENT ‘)’
因为T_INT,T_IDENT都是一个整数型常量,而’(‘这样的单个字符也可以当作整数型常量对待,这样语法解析器在分析语法的时候工作会更轻松些。所以在InitHash函数里,其把编程语言里所有的关键字和多字符操作符(如左移赋值操作符 <<=)都设置了类型标识号(Token),在Tok对象的scan()函数扫描源文件时,会逐一在这个字典里查询关键字的标识号:
public void InitHash() { // 为字符类型识别号对照表 – tokens分配空间 tokens = new Hashtable(); AddTok(T_LEFT_ASSIGN, "<<="); // ... ... AddTok(T_IF, "if"); // ... ... AddTok(T_STATIC, "static"); AddTok(T_INT, "int"); // ... ... }
而对应的每个标识号(Token)的定义,则可以在Tok.cs源文件的最上面找到:
public const int T_LEFT_ASSIGN = 10001; // ... ... public const int T_IF = 20001; // ... ... public const int T_STATIC = 30002; // ... ... public const int T_INT = 40003; // ... ... public const int T_IDENT = 50001; public const int T_DIGITS = 50002; public const int T_UNKNOWN = 99999; public const int T_EOF = -1;
字符类型识别号对照表初始化完毕后,语法分析器就可以调用Tok对象的scan函数进行语法处理了,scan函数每次只处理并返回一个字符类型:
public void scan() { // 跳过注释、换行符、空格等字符 skipWhite(); // 先判断当前读取的字符是不是一个字母 // 如果是字母开头的话,要么是关键字, // 要么就是变量名 if (Char.IsLetter(io.getNextChar())) // 逐个扫描后面的字符,直到识别出关键字 // 或者变量名为止才退出 LoadName(); // 如果当前的字符是 0 - 9的数字 else if (Char.IsDigit(io.getNextChar())) // 扫描完后面的数字并归类 LoadNum(); // 如果是操作符,扫描完后面的操作符字符串 else if (isOp(io.getNextChar())) LoadOp(); // 如果文件已经读取完毕了 else if (io.EOF()) { // 返回特殊的识别符 T_EOF,表示文件读取完毕 value = null; token_id = T_EOF; } else { // 这个字符不是一个合法的字符,归类成T_UNKNOWN // T_UNKNOWN没有被任何语法引用 // 如果语法分析器在扫描语法的过程中 // 看到这个识别符,很有可能是源码里有语法错误 value = new StringBuilder(MyC.MAXSTR); value.Append(io.getNextChar()); token_id = T_UNKNOWN; io.ReadChar(); } skipWhite(); // 条件编译,如果是myc.exe是调试版本,则在命令行里 // 打印出当前识别的字符类型,便于myc.exe的开发者排错 #if DEBUG Console.WriteLine("[tok.scan tok=["+this+"]"); #endif }
scan函数是Tok对象里最核心的函数,它实际上是完成前面myc语法里这些词法规则(还有隐含的关键字和操作符识别):
letter ::= "A-Za-z"; digit ::= "0-9"; name ::= letter { letter | digit }; integer ::= digit { digit };
我们再通过说明LoadName函数来解释词法分析的细节:
void LoadName() { // 缓存读取到的字符 value = new StringBuilder(MyC.MAXSTR); skipWhite(); // 错误验证 - 确保第一个字符是字母 if (!Char.IsLetter(io.getNextChar())) throw new ApplicationException("?Expected Name"); // 后面跟着的字符只能是数字或者字母 while (Char.IsLetterOrDigit(io.getNextChar())) { // 缓存字符,以便判断是变量名,还是关键字 value.Append(io.getNextChar()); // 从源文件里读取下一个字符 io.ReadChar(); } // 在字符类型识别表里查询读取到的词组是不是关键字 token_id = lookup_id(); // 不是关键字的话,那么就是变量名(或函数名) if (token_id <= 0) token_id = T_IDENT; skipWhite(); }
上面基本上就是词法分析的关键代码了,不过在说明的时候,我特意跳过了构造函数的 io.ReadChar()这个函数,这个函数从字面意义上看是读取一个字符,但实际上从源文件一个字符一个字符的读取效率实在是太低了,因此一般都是从源文件里读取一大段字符并缓存在内存里,提高效率:
// Io.cs – ReadChar函数 public void ReadChar() { // 判断是不是读到文件末尾了 if (_eof) // if already eof, nothing to do here return; // 如果缓存还没有实例化,或者缓存里的字符 // 已经处理完毕了,创建一个新的缓存 // 对于老的缓存数组,丢给垃圾回收机制处理 if (ibuf == null || ibufidx >= MyC.MAXBUF) { ibuf = new char[MyC.MAXBUF]; _eof = false; // 从源文件里读取一大块内容到缓存里 ibufread = rfile.Read(ibuf, 0, MyC.MAXBUF); ibufidx = 0; if (buf == null) buf = new StringBuilder(MyC.MAXSTR); } // 从缓存里读取下一个字符 look = ibuf[ibufidx++]; // 判断这次读取时,是否已经到源文件末尾了 if (ibufread < MyC.MAXBUF && ibufidx > ibufread) _eof = true; /* * track the read characters */ // 保存当前读取的字符,以便在生成IL源文件的时候 // 可以把C源码跟生成的IL源码对应起来 buf.Append(look); // 如果碰到换行,更新行号,行号在报告语法错误 // 的时候会用到,告知具体语法出错的行号便于 // 程序员找到错误 if (look == ‘\n‘) bufline++; }
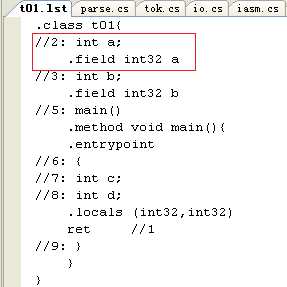
在Io.ReadChar函数里,会保存读取的C源码,当要生成IL源文件的时候,这个信息用来保存C语句跟IL语句的对应关系,如用下面的命令编译myc里自带的测试源码文件:

效果如下图:
标签:
原文地址:http://www.cnblogs.com/vowei/p/4337922.html