标签:
1 declare @table table( 2 company_id int ,--公司编号 3 quarter_num char(2),--季度 4 disti varchar(50),--分销商 5 num int --数量 6 ) 7 8 insert @table 9 values(1,‘Q1‘,‘D1‘,1),(1,‘Q1‘,‘D1‘,2) 10 ,(1,‘Q3‘,‘D2‘,1) 11 ,(1,‘Q4‘,‘D1‘,1) 12 ,(1,‘Q2‘,‘D1‘,1) 13 ,(2,‘Q1‘,‘D1‘,1) 14 ,(2,‘Q3‘,‘D1‘,3) 15 ,(2,‘Q4‘,‘D1‘,4) 16 ,(2,‘Q2‘,‘D1‘,2)
项目中经常遇到类似YTD(Year to Day,年初1-1至某天的统计)的查询。表结构如上图所示。
而在实际项目中,并不会刚刚好只按照时间这一个参数来分组,比如会增加上图中的disti字段,而此字段最大的特点为,每个公司并不一定都有此分销商的数据。
在查询时出现断层的问题,如下图第4行结果所示。
select b.company_id,b.quarter_num,b.disti,SUM(a.num) [YTQ] from @table a join (select distinct company_id,quarter_num,disti from @table )b on a.company_id=b.company_id and a.disti=b.disti and a.quarter_num<=b.quarter_num group by b.company_id,b.quarter_num,b.disti
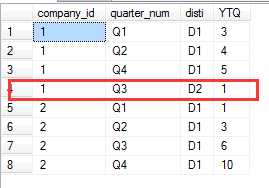
正常的需求是公司1,Q3应该有2行数据,D1分销商统计值为4,D2分销商统计值为1;Q4应该增加一条D2统计值为1的记录。
如果偏好于使用YTD查询,请注意在最开始构造基础数据时,囊括所有字段的所有值。
标签:
原文地址:http://www.cnblogs.com/daisy-popule/p/4340315.html