标签:
------------------------------------------------------------------------------------
搜索分为两种:
1. 对结构化数据搜索:SQL语句对数据库中存储的内容进行查询。
2. 对非结构化数据搜索:文本,图片,全文搜索。
全文检索分为两类:
1. 顺序扫描:如SQL中的LIKE查询或regexp正则查询。
2. 索引扫描:将非结构化数据提取部分(如:词组)后进行重组,使其机构化,这些提取出的数据即索引。
使用索引的全文检索包括两个过程:
1. 索引创建(Index):将内容中的词组 与 文本的ID提取出来,创建一张索引表。
2. 搜索索引(Search):将搜索内容拆分成词组,去索引表中匹配ID,查出文本内容。
如何创建索引:
1. 将需要创建索引的文档交给分词组件(Tokenizer);
分词组件所做的事:将文档生成单独的单词,去除标点符号,去除停词(the, a, 的, 是);每种语言的分词组件都有一个停词集合,
经过分词组件后得到的结果成为词元。
2. 将得到的词元(Token)传给语言处理组件(Linguistic Processer);
语言处理组件对得到的词元进行同语言处理:如,英文变为小写(Lowercase),将单词缩减为词根形式,如“cars”到“car”等(stemming),将单词转变为词根形式,如“drove”到“drive”(lemmatization),
3. 将得到的词(Term)传给索引组件(Indexer);
索引组件主要做以下几件事:利用得到的词(Term)和文档ID,创建一个字典,对字典按字母顺序排序,合并相同的词成为文档倒排(Posting List)链表。
如何对索引进行搜索:
1. 输入查询语句,提交给Sphinx。
2. Sphinx对查询语句进行词法分析,语法分析及语言处理。
3. 搜索索引,得到符合语法树的文档。
4. 根据得到的文档和查询语句的相关性,对结果排序。
Sphinx是SQL Parse Index(查询词组索引)缩写,基于SQL的全文检索引擎。Coreseek支持中文的全文检索引擎。
Sphinx的优点:
高速的建立索引(在当代CPU上,可达到10M/秒)
高性能的搜索(在2-4G的文本数据上,平均每次检索响应时间小于0.1秒)
可处理海量数据(目前已知可以处理超过100GB的文本数据,在单一CPU的系统上可处理100M的文档);
提供了优秀的相关度算法,基于短语相似度和统计BM2的复合Ranking方法;
支持分布式搜索;
提供文档片段(摘要以及高亮)生成功能;
可作为MySQL的存储引擎提供搜索服务;
支持布尔、短语、词语相似度等多种检索方式;
文档支持多个全文检索字段(最大不超过32个);
Sphinx的缺点:
必须要有主键
主键必须为整形
不负责数据存储
配置不灵活
Sphinx的使用:
1. 下载Sphinx:
wget http://sphinxsearch.com/files/sphinx-2.2.8-release.tar.gz
编译安装:
cd /public/sphinx-2.2.8
./configure --prefix=/usr/local/sphinx --with-mysql=/usr/local/mysql
(rpm安装的mysql: ./configure --prefix=/usr/local/sphinx --with-mysql=/usr)
make && make install
安装完毕得到四个目录:
bin:存放命令,indexer索引组件,searchd进程
etc:配置文档
var:存放索引表
创建数据库表:
show database; //查看所有数据库
create database test;
create table post(
id int unsigned auto_increment primary key,
title varchar(255) not null default ‘‘,
content text default NULL
)engine=myisam default charset=utf8;
desc post; //查看表结构
insert into post(title, content) values("linux", "linux11111");
2. 配置Sphinx:
cd /usr/local/sphinx/etc/
cp sphinx.conf.dist sphinx.conf //备份配置文件,防止改错
vim sphinx.conf
配置文件结构:
# 主数据源,(main名字可更改)
source main{
type = mysql #数据库类型
sql_host = localhost #MySQL主机IP
sql_user = test #MySQL用户名
sql_pass = #MySQL密码
sql_db = test #MySQL数据库
sql_port = 3306 #MySQL端口
sql_sock = /tmp/mysql.sock #Linux下需要开启,指定sock文件
sql_query_pre = SET NAMES utf8 #MySQL检索编码
sql_query_pre = SET SESSION query_cache_type=OFF #关闭缓存
sql_query = \ #获取数据的SQL语句
SELECT id, title, content FROM post
#sql_attr_uint = group_id #对排序字段进行注释, 默认使用sphinx的文档表,这里不需要
#sql_attr_timestamp = date_added #对排序字段进行注释
}
# 增量数据源, 继承主数据源
source main throttled : main{
}
# 主索引,(main名字可更改)
index main{
source = main
path = /usr/local/sphinx/var/data/main
}
# 增量索引
index test1 stemmed : test1{
}
# 分布式索引,distributed index
index dist1{
}
# 实时索引,realtime index
index rt{
}
# 索引器,(调整最小内存到最佳)
indexer{
mem_limit = 256M #内存大小限制,默认128M,推荐256M
#其它用默认即可
}
# 服务进程,(监听端口号)
searched{
#全部默认即可,默认端口号就是9312
}
# 公共配置
common{
}
:set nu //显示行号,:set nonu取消行号
:311,314s/^/#/g //注释增量数据源
:628,632s/^/#/g //注释增量索引
:639,696s/^/#/g //注释分布式索引
3. 创建索引:
创建索引命令:indexer
-c 指定配置文件
--all 对所有索引重新编制索引
--rotate 用于轮换索引,在不停止服务的时候(searchd运行时)增加索引;searchd运行时不加会报错。
--merge 合并索引,增量索引合并到主索引的时候用
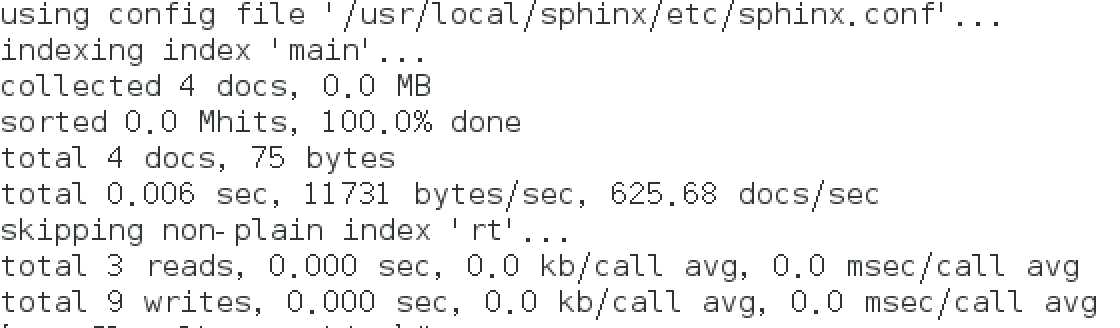
生成全部索引: /usr/local/sphinx/bin/indexer -c /usr/local/sphinx/etc/sphinx.conf --all
或生成指定索引: /usr/local/sphinx/bin/indexer -c /usr/local/sphinx/etc/sphinx.conf main
(1)如果这里出现报错:
【ERROR: index ‘main‘: sql_connect: Can‘t connect to local MySQL server through socket ‘/tmp/mysql.sock‘】
没找到/tmp/mysql.sock, 通过find / -name mysql.sock -print查找到位置,在配置sphinx.conf里更改正确。
如:mysql_sock = /var/lib/mysql/mysql.sock 保存退出。
(2)继续创建索引,警告:
【WARNING: Attribute count is 0: switching to none docinfo】
改sphinx.conf里的docinfo = none就没有警告了。(http://sphinxsearch.com/docs/current.html#conf-docinfo)
创建索引出现如下提示,表示生成成功:
Link:http://www.cnblogs.com/farwish/p/3961962.html
@黑眼诗人 <farwish.com>
标签:
原文地址:http://www.cnblogs.com/farwish/p/3961962.html