标签:
高级迭代器可以实现多种有价值功能。本节将展示如何利用高级迭代器和标准Thrust算法处理一个更广泛的类问题。
对于那些熟悉的Boost C ++库的开发者,他们会发现Thrust的高级迭代器与Boost迭代器库非常相似。
constant_iterator常量迭代器最明显的特点,是每次解引用时,都会返回一个相同的值。下面的例子我们将一个常量迭代器的初始值设置为10。
1 #include <thrust/iterator/constant_iterator.h> 2 ... 3 // create iterators 4 thrust::constant_iterator<int> first(10); 5 thrust::constant_iterator<int> last = first + 3; 6 7 first[0] // returns 10 8 first[1] // returns 10 9 first[100] // returns 10 10 11 // sum of [first, last) 12 thrust::reduce(first, last); // returns 30 (i.e. 3 * 10)
当需要输入恒值序列时,常量迭代器将会是最便捷、高效的解决方案。
如果一个序列需要不断增长的值,计数迭代器将是一个很好的选择。下面的例子将计数迭代器的初始值设定为10,并像数组一样访问该迭代器。
1 #include <thrust/iterator/counting_iterator.h> 2 ... 3 // create iterators 4 thrust::counting_iterator<int> first(10); 5 thrust::counting_iterator<int> last = first + 3; 6 first[0] // returns 10 7 first[1] // returns 11 8 last[0] // returns 13 9 first[100] // returns 110 10 11 // sum of [first, last) 12 thrust::reduce(first, last); // returns 33 (i.e. 10 + 11 + 12)
虽然常量迭代器和计数迭代器可以以数组形式访问,但实际上它们并不需要存储器开销。每次解引用某个迭代器时,它会生成对应的值,并将该值返回给调用函数。
transform_iterator在算法部分的教程中讲到过kernel融合,比如将transform算法和reduce算法,组合成单一的transform_reduce操作。
即使没有专门的transform_xxx算法类型,转换迭代器同样可以实现一样的功能。
下面的例子展示了另一种融合transformation算法和 reduction算法的方式。
1 #include <thrust/iterator/transform_iterator.h> 2 // initialize vector 3 thrust::device_vector<int> vec(3); 4 vec[0] = 10; vec[1] = 20; vec[2] = 30; 5 6 // create iterator (type omitted) 7 ... first = thrust::make_transform_iterator(vec.begin(), negate<int>()); 8 ... last = thrust::make_transform_iterator(vec.end(), negate<int>()); 9 10 first[0] // returns -10 11 first[1] // returns -20 12 first[2] // returns -30 13 14 // sum of [first, last) 15 thrust::reduce(first, last); // returns -60 (i.e. -10 + -20 + -30)
简单起见,这里省略了第一个和最后一个迭代器的类型。转换迭代器的缺点之一,是它指向的迭代器类型很长。
针对这个问题,通常的解决方法是:只把make_transform_iterator放在被调用算法的参数里。例如:
// sum of [first, last) thrust::reduce(thrust::make_transform_iterator(vec.begin(), negate<int>()), thrust::make_transform_iterator(vec.end(), negate<int>()));
这样就避免了创建变量来存储第一个和最后一个迭代器。
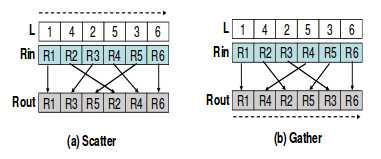
permutation_iterator上一节展示了如何使用转换迭代器融合transformation算法和另一种算法,从而避免不必要的内存操作。类似的,排列迭代器可以将分散(scatter)、聚集(gather)操作和Thrust算法进行融合,甚至和其他高级迭代器也可以。
下面的示例演示如何将聚合操作和reduction算法进行融合:
1 #include <thrust/iterator/permutation_iterator.h> 2 ... 3 // gather locations 4 thrust::device_vector<int> map(4); 5 map[0] = 3; 6 map[1] = 1; 7 map[2] = 0; 8 map[3] = 5; 9 10 // array to gather from 11 thrust::device_vector<int> source(6); 12 source[0] = 10; 13 source[1] = 20; 14 source[2] = 30; 15 source[3] = 40; 16 source[4] = 50; 17 source[5] = 60; 18 19 // fuse gather with reduction: 20 // sum = source[map[0]] + source[map[1]] + ... 21 int sum = thrust::reduce(thrust::make_permutation_iterator(source.begin(), map.begin()), 22 thrust::make_permutation_iterator(source.begin(), map.end()));
这里使用了make_permutation_iterator函数来构建排列迭代器。make_permutation_iterator的第一个参数是聚合操作的源数组,第二个参数是索引数组。
两次调用的make_permutation_iterator函数中,第一个参数是一样的,但是第二个参数是不同的,用来定义索引数组的开头和结尾。
当排列迭代器作为一个函数的输出序列时,它相当于分散操作与该函数的融合。
通常排列迭代器允许对序列的特定的值进行操作,而不是对整个序列进行操作。
注:
zip_iterator最好的迭代器总是放在最后!Zip迭代器是一个非常实用的小工具:它将多个输入序列用来产生一个元组(tuple)序列。
下面的示例是将整型序列和字符型序列“压缩”成一个元组序列,并且计算这个元组的最大值。
1 #include <thrust/iterator/zip_iterator.h> 2 ... 3 // initialize vectors 4 thrust::device_vector<int> A(3); 5 thrust::device_vector<char> B(3); 6 A[0] = 10; A[1] = 20; A[2] = 30; 7 B[0] = ‘x‘; B[1] = ‘y‘; B[2] = ‘z‘; 8 9 // create iterator (type omitted) 10 first = thrust::make_zip_iterator(thrust::make_tuple(A.begin(), B.begin())); 11 last = thrust::make_zip_iterator(thrust::make_tuple(A.end(), B.end())); 12 13 first[0] // returns tuple(10, ‘x‘) 14 first[1] // returns tuple(20, ‘y‘) 15 first[2] // returns tuple(30, ‘z‘) 16 17 // maximum of [first, last) 18 thrust::maximum< tuple<int,char> > binary_op; 19 thrust::tuple<int,char> init = first[0]; 20 thrust::reduce(first, last, init, binary_op); // returns tuple(30, ‘z‘)
zip迭代器之所以非常实用,是因为大多数算法只能容纳一个输入序列,或者最多可以容纳两个。zip迭代器将多个独立的序列合并成一个单一的元组序列,使更多算法能够处理这些序列。
如何利用zip迭代器和for_each函数实现三元transformation,请参阅代码实例arbitrary_transformation。只要仿照这个代码实例做一些简单扩展,就可以实现多个输出序列的transformation。
zip迭代器除了方便,还能使程序更有效地运行。例如,在CUDA里,将三维空间的点储存为float3型的数组是糟糕的,因为在访问操作时不能合并存储器的访问。
使用zip迭代器,可以将三个坐标分别存储在三个不同的数组中,这样就可以合并访存。在这种情况下使用zip迭代器创建一个包含三维向量的(虚拟)数组,再作为thrust算法的参数。
更多细节请参阅代码实例dot_products_with_zip。
注:a是结构体数组,b是数组结构体。zip迭代器可以创建一个数组结构体,可以实现合并访存。

参考:
2.Efficient Gather and Scatter Operations on Graphics Processors
【译】Thrust快速入门教程(四) —— Fancy Iterators
标签:
原文地址:http://www.cnblogs.com/zerolover/p/4343116.html