标签:
有效等价类和无效等价类。
无效的等价类是指不合理,无意义或者不符合规格说明书的输入构成的集合。有效等价类反之。
一般的划分原则有
等价类的划分就是对可能的输入的分类过程,至于分类的标准,就是根据可能的输入来确定。1)如果规格说明对输入有明确的说明则按照规格的说明来分类;2)对于数值的输入,按照区间划分是最自然的分类方法;3)对于非数值的输入,可以按照关注的特点来分类。
比如"科技类参考书50-100册"这句话就提到了两个输入,书的种类和数量。对照1)可以知道书可以分为科技类和非科技类两种;对照1)和2)可以知道书的数量分为三个区间:(0,50),[50-100],(100,+∞);
|
有效等价类 |
编号 |
无效等价类 |
编号 |
|
科技类 |
1 |
非科技类 |
3 |
|
[50-100] |
2 |
(0,50) |
4 |
|
(100,+∞) |
5 |
可以根据上面的分类设计出测试用例
|
输入 |
期望输出 |
覆盖等价类 |
|
科技类 55册 |
合法输入 |
1,2 |
|
非科技类 55册 |
非法输入 |
3 |
|
科技类25册 |
非法输入 |
4 |
|
科技类 101册 |
非法输入 |
5 |
以上4个测试用例将等价类1-5全部覆盖。
覆盖有效等价类时,尽量多的将有效等价类放在一个测试用例中;覆盖无效等价类时,最好每次只放入一个无效等价类。因为这样出现错误的时候能很快的确定错误来源。
我觉得这是对等价类划分的一个大概的认识。
边界值分析法这里提到"大量的软件测试表明,故障往往出现在定义域或者值域的边界上,而不是在起内部。"虽然不知道这句话的来源是什么,不过放到自己身上想想确实是这样,写程序时大多数精力都放在了常见的情况的处理上,很少考虑到边界情况。推己及人,一般人也容易犯类似的问题吧。
边界分析测试
边界值分析法对测试用例一定的情况下设计测试用例提供了指导。大概的方法是这样的:
所以,n个变量时会有 4n+1种测试用例
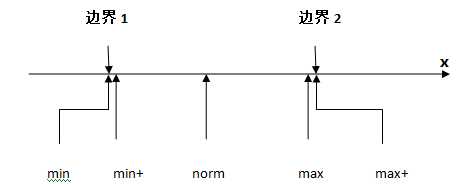
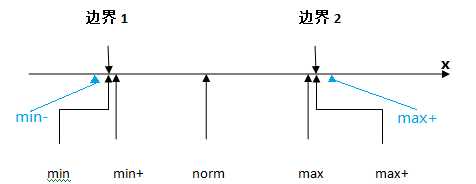
健壮性边界测试
健壮性边界测试考虑了超出极限的情况,就是加入了min-和max+两种情况。所以n个变量时会有 6n+1种测试用例。
但是,在实际中,max+不容易实现。
标签:
原文地址:http://www.cnblogs.com/test-tech/p/4347563.html