标签:
小弟今天运行了一个小小的关于map-reduce的WordCount 程序,经过一番捣腾收获可不小。在这里记录运行过程中所遇到的一些常见问题,有关于和其他版本不同的地方。
再伪分布式的开发环境下,在集成开发环境中写好了WordCount 程序,程序源代码如下:
TokenizerMapper 类:
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable count = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer st = new StringTokenizer(value.toString());
while (st.hasMoreTokens()) {
word.set(st.nextToken());
context.write(word, count);
}
}
}
IntSumReducer类的相关代码如下:
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable i : values) {
sum += i.get();// 对单词为key的计数统计
}
result.set(sum);// 每次set一下都会清空之前的值
context.write(key, result);
}
}
主方法中:
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
System.out.println("the length of otherArgs is:"+otherArgs.length+",\n---the parameters of input at the con is:" + args[0] + "----" + args[1]);
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);// jar 包中的主方法入口类
job.setMapperClass(TokenizerMapper.class);// 入口类中的mapper类
job.setReducerClass(IntSumReducer.class);// 入口类中的reducer类
job.setCombinerClass(IntSumReducer.class);// 进行数据lower ruducer的类
job.setOutputKeyClass(Text.class);// 设置好输出的key 的类型系统会将该类型作为key
job.setOutputValueClass(IntWritable.class);// 输出的数据类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));// 输入的文件目录
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// 输出的文件目录
System.exit(job.waitForCompletion(true) ? 0 : 1);// 若系统运行成功, 则返回0 ,否则返回1
}
打好jar包后,将wordcount.jar 拷贝到linux 系统的 /usr/hddemo 目录下,在开启集成的条件下,完成以下准备工作:
1、在hdfs 根目录下创建一个input目录,用于map 作业启动时数据的输入源,即map任务需要数据就将到该目录下进行读取并使用默认的TextInoutFormat进行解析
2、在hadoop 目录下创建一个目录,用来准备输入的一些文件,我这里使用的目录是 input ,其中是将hadoop的一些配置文件放于这里,进行文件拷贝的命令如下所示:
cp ./etc/hadoop/*.xml ./input
3、文件准备好了,就要上传到hdfs的文件系统中去,因为刚刚我们所创建的目录是在自己的本地文件系统下,我们要将这些文件上传到hadoop 的文件系统中去,hadoop 才能找得到数据源,使用一下命令进行文件的上传
bin/hadoop fs -put ./input/*.xml input 上传成功如下图所示: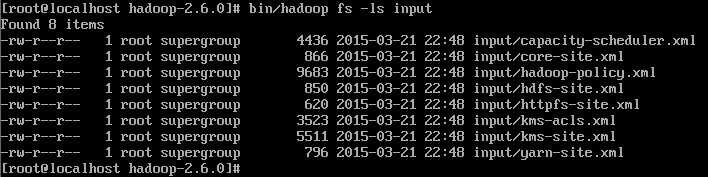
4、我的wordcount.jar 是放在./usr/hddemo 目录下,如下图所示:

5、一切工作准备就绪,接下来就是见证奇迹的时刻,按照视频或者网上的方法是使用一下命令,小弟见到,嘿,资料还蛮丰富的,于是就快速的敲完命令:
一下是运行一个wordcount 任务的命令:bin/hadoop jar /usr/hddemo/wordcount.jar 包名.WordCount input output
说明:input 指定的是执行map任务是的数据源所在目录,output 是指定reduce任务 执行完后将结果输出的目录
一按下 enter 键 ,出乎意料的结果出现了:

这下就奇怪了,按照老师的方法来写的,参照网上的快照给做的,怎么我就出这么一个奇葩的结果呢?这就晕了---,仔细阅读代码后,发现输入的参数 不等于2,所以应用程序就退出了。这是什么原因呢?于是我就尝试着将输入参数的长度打印出了,发现为3,如上图上示,而且把第一个参数和第二个参数打印出来,结果发现并不像我们想象的一样, 程序中指定输入两个参数,而我们输入了三个参数,肯定是多输入了,查看命令行,发现.jar 后面确实是带了三个参数,难道是这里出现了问题,而且打印的第一参数和第二个参数和输入的顺序一样,这才发现原来是这里除了问题,那到底哪个参数不要呢?不指定主类,hadoop 他找到的吗?删掉一个input 或者output ,那也可定是不行的,那到底哪个参数是不需要的呢?于是带着猜疑的想法,先将主类的路劲给删除 跑一边吧,于是有输入一下的命令:
bin/hadoop jar /usr/hddemo/wordcount.jar input output
结果奇迹就出现了:程序快乐的跑起来了,也不再闷闷不言了,哈哈,然后查看hdfs 上的out目录,果然有相应输出,这就是reduce任务执行完后的输出:如下所示:

最后闭上眼睛 静静的等待 bin/hadoop fs -cat output/* 输出执行的结果:
结果终于如愿啦:
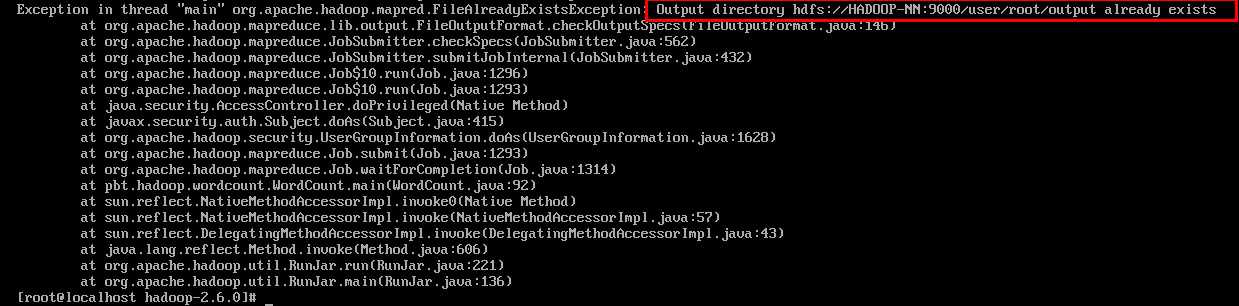
通过以上可以发现,hadoop 2.6 版本当命令行执行作业时,不需要指定主类的具体名称,而是直接指定输入的数据目录和输出的数据目录即可,最后需要注意,如果输出的目录output在hdfs 上已经有了,则会运行不成功,抛出一下异常:
至此,一个hadoop 的WordCount 程序就这样如痴如醉的跑起来,希望给hadoop的过客有很大的帮助!
关于hadoop 2.6 运行WordCount 应该注意的问题
标签:
原文地址:http://www.cnblogs.com/pbting/p/4355765.html