标签:
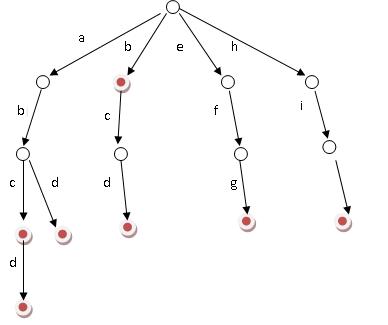
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
可以看出:
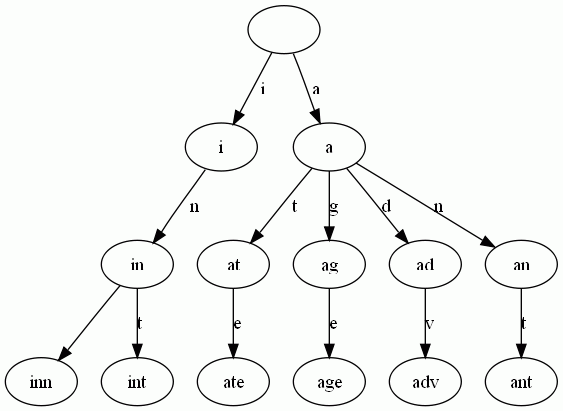
Trie的数据结构定义:

next是表示每层有多少种类的数,如果只是小写字母,则26即可,若改为大小写字母,则是52,若再加上数字,则是62了,这里根据题意来确定。
v可以表示一个字典树到此有多少相同前缀的数目,这里根据需要应当学会自由变化。
Trie的查找(最主要的操作):
(1) 每次从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索; (3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
这里给出生成字典树和查找的模版:
生成字典树:
void createTrie(char *str)
{
int len = strlen(str);
Trie *p = root, *q;
for(int i=0; i<len; ++i)
{
int id = str[i]-'0';
if(p->next[id] == NULL)
{
q = (Trie *)malloc(sizeof(Trie));
q->v = 1; //初始v==1
for(int j=0; j<MAX; ++j)
q->next[j] = NULL;
p->next[id] = q;
p = p->next[id];
}
else
{
p->next[id]->v++;
p = p->next[id];
}
}
p->v = -1; //若为结尾,则将v改成-1表示
}
接下来是查找的过程了:
int findTrie(char *str)
{
int len = strlen(str);
Trie *p = root;
for(int i=0; i<len; ++i)
{
int id = str[i]-'0';
p = p->next[id];
if(p == NULL) //若为空集,表示不存以此为前缀的串
return 0;
if(p->v == -1) //字符集中已有串是此串的前缀
return -1;
}
return -1; //此串是字符集中某串的前缀
}对于上述动态字典树,有时会超内存,比如 HDOJ 1671 Phone List,这是就要记得释放空间了:
int dealTrie(Trie* T)
{
int i;
if(T==NULL)
return 0;
for(i=0;i<MAX;i++)
{
if(T->next[i]!=NULL)
deal(T->next[i]);
}
free(T);
return 0;
}标签:
原文地址:http://blog.csdn.net/u014082714/article/details/44746549