标签:
{
int a;
char b[20];
double c;
}
#define FIND( struc, e ) (size_t)&(((struc*)0)->e)
则FIND(student,a)等于0
FIND(student,b)等于4
FIND求一个结构体struc里某个变量相对struc的偏移量
? ?
size_t是一种数据类型
? ?
#define SECONDS_PER_YEAR (60*60*24*365)UL
? ?
意识到这个表达式将使一个16位机的整型数溢出,因此要用到长整型L,告诉编译器这是个长整型
? ?
预处理器将计算常数表达式,所以自己不必写出来
? ?
define不能以分号结尾
? ?
const的用法
? ?
定义常量,修饰函数的参数和返回值,甚至函数的定义体,
? ?
在const成员函数中,用mutable修饰成员变量名后,就可以修改类的成员变量了
? ?
sizeof
? ?
指针的大小是个定值,4个字节
? ?
32位系统数据类型的大小,字节即byte
char | 1 |
short | 2 |
int | 4 |
float | 4 |
long | 4 |
double | 8 |
? ?
结构体大小确认规则
? ?
结构体的对齐规则是先按数据类型自身进行对齐,然后再按整个结构体进行对齐,对齐值必须是2的幂,比如1,2, 4, 8, 16。如果一个类型按n字节对齐,那么该类型的变量起始地址必须是n的倍数。比如int按四字节对齐,那么int类型的变量起始地址一定是4的倍数
? ?
例子

? ?

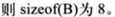
? ?
数据对齐
? ?

? ?
B和C由于变量顺序不同,造成数据是否对齐
? ?

? ?
问题:是只有类才是这样,还是结构体也是这样
? ?
答:结构体也是这样的
? ?
struct Test1
{
int i ;
double d ;
char c ;
};
所以整个结构体是 4(i) + 4(补齐)+ 8(d) + 1(c) = 17字节,注意!还没完,整个结构体还没有对齐,因为结构体中空间最大的类型是double,所以整个结构体按8字节对齐,那么最终结果就是17 + 7(补齐) = 24字节。
? ?
我们对Test1做一点改动
struct Test1
{
char c ;
int i ;
double d ;
};
这时Test1的大小就变成了16,而不是24了,节省了8个字节!可见结构体中成员的书写顺序对结构体大小的影响还是很大的,一个好的建议是,按照数据类型由小到大的顺序进行书写
? ?
构造函数与析构函数调用的顺序
? ?
构造函数的调用顺序总是如下:
1、基类构造函数。如果有多个基类,则构造函数的调用顺序是某类在类派生表中出现的顺序,而不是它们在成员初始化表中的顺序。
2、成员类对象构造函数。如果有多个成员类对象则构造函数的调用顺序是对象在类中被声明的顺序,而不是它们出现在成员初始化表中的顺序。
3、派生类构造函数。
? ?
析构函数的调用顺序与构造函数的调用顺序正好相反,将上面3个点反过来用就可以了
1、首先调用派生类的析构函数
2、其次再调用成员类对象的析构函数
3、最后调用基类的析构函数。
?
析构函数在下边3种情况时被调用:
1.对象生命周期结束,被销毁时(一般类成员的指针变量与引用都i不自动调用析构函数);
2.delete指向对象的指针时,或delete指向对象的基类类型指针,而其基类虚构函数是虚函数时;
3.对象i是对象o的成员,o的析构函数被调用时,对象i的析构函数也被调用。
? ?
例子
class Base
{
public:
Base(){ std::cout<<"Base::Base()"<<std::endl; }
~Base(){ std::cout<<"Base::~Base()"<<std::endl; }
};
? ?
class Base1:public Base
{
public:
Base1(){ std::cout<<"Base1::Base1()"<<std::endl; }
~Base1(){ std::cout<<"Base1::~Base1()"<<std::endl; }
};
? ?
class Derive
{
public:
Derive(){ std::cout<<"Derive::Derive()"<<std::endl; }
~Derive(){ std::cout<<"Derive::~Derive()"<<std::endl; }
};
? ?
class Derive1:public Base1
{
private:
Derive m_derive;
public:
Derive1(){ std::cout<<"Derive1::Derive1()"<<std::endl; }
~Derive1(){ std::cout<<"Derive1::~Derive1()"<<std::endl; }
};
? ?
int _tmain(int argc, _TCHAR* argv[])
{
Derive1 derive;
return 0;
}
? ?
运行结果是:
Base::Base()
Base1::Base1()
Derive::Derive()
Derive1::Derive1()
Derive1::~Derive1()
Derive::~Derive()
Base1::~Base1()
Base::~Base()
? ?
构造函数的调用顺序是;首先,如果存在基类,那么先调用基类的构造函数,如果基类的构造函数中仍然存在基类,那么程序会继续进行向上查找,直到找到它最早的基类进行初始化;如上例中类Derive1,继承于类Base与Base1;其次,如果所调用的类中定义的时候存在着对象被声明,那么在基类的构造函数调用完成以后,再调用对象的构造函数,如上例中在类Derive1中声明的对象Derive m_derive;最后,将调用派生类的构造函数,如上例最后调用的是Derive1类的构造函数。
? ?
C++中多态的机制,虚函数
? ?
C++明白指出,当derived class对象经由一个base class指针被删除,而该base class带着一个non-virtual析构函数,其结果未有定义---实际执行时通常发生的是对象的derived成分没被销毁掉。
? ?
看下面的例子:
class Base
{
public:
Base(){ std::cout<<"Base::Base()"<<std::endl; }
~Base(){ std::cout<<"Base::~Base()"<<std::endl; }
};
? ?
class Derive:public Base
{
public:
Derive(){ std::cout<<"Derive::Derive()"<<std::endl; }
~Derive(){ std::cout<<"Derive::~Derive()"<<std::endl; }
};
? ?
int _tmain(int argc, _TCHAR* argv[])
{
Base* pBase = new Derive();
//这种base classed的设计目的是为了用来"通过base class接口处理derived class对象"
delete pBase;
? ?
return 0;
}
? ?
输出的结果是:
Base::Base()
Derive::Derive()
Base::~Base()
从上面的输出结果可以看出,析构函数的调用结果是存在问题的,也就是说析构函数只作了局部销毁工作,这可能形成资源泄漏败坏数据结构等问题;那么解决此问题的方法很简单,给base class一个virtual析构函数;
? ?
class Base
{
public:
Base(){ std::cout<<"Base::Base()"<<std::endl; }
virtual ~Base(){ std::cout<<"Base::~Base()"<<std::endl; }
};
? ?
class Derive:public Base
{
public:
Derive(){ std::cout<<"Derive::Derive()"<<std::endl; }
~Derive(){ std::cout<<"Derive::~Derive()"<<std::endl; }
};
? ?
int _tmain(int argc, _TCHAR* argv[])
{
Base* pBase = new Derive();
delete pBase;
? ?
return 0;
}
? ?
输出结果是:
Base::Base()
Derive::Derive()
Derive::~Derive()
Base::~Base()
可能上面的输出结果正是我们所希望的吧,呵呵!由此还可以看出虚函数还是多态的基础,在C++中没有虚函数就无法实现多态特性;因为不声明为虚函数就不能实现"动态联编",所以也就不能实现多态啦!
? ?
sizeof
? ?
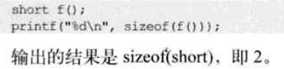
? ?

? ?

? ?
类都是一个指针,所以都是4
? ?
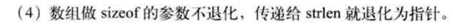
? ?

? ?

? ?

? ?

? ?
内联函数inline

? ?
标签:
原文地址:http://www.cnblogs.com/keedor/p/4377989.html