标签:
elasticsearch是一款企业级的全文搜素引擎,基于java的Lucene库开发,完全采用RESTful接口面向用户,对分布式搜索支持非常好!
为了能实现分布式部署,我这里采用了两台群晖的nas,分别是x86和arm的架构,实践证明都是能运行起来的。
主机:群晖的DS415+,DS414j (https://www.synology.com)
版本:elasticsearch-1.5.0
先从apache的官方网站上下载elasticsearch的程序包
https://www.elastic.co/downloads/elasticsearch
这里有4种下载包,tar/zip/deb/rpm,我这里选择zip,在nas中解压后就能直接执行了。
需要注意的是,因为elasticsearch是用java编写的,所以运行的环境必须要有java的解释器,在群晖nas上默认是没有的,需要安装java的管理器,然后去oracle的官方网站上下载jre来安装到nas中去。
解压后,运行./bin/elasticsearch,过几秒钟就会把服务启动起来了,如果想要在background中运行,就采用./bin/elasticsearch -d的方式。
运行后,可以开打浏览器直接访问http://localhost:9200/ (这里localhost请替换成你的服务器地址)
运行成功可以看到如下内容:

顺便说一下,
echo ‘marvel.agent.enabled: false‘ >> ./config/elasticsearch.yml
如果是在foreground开启,那就直接ctrl+c就可以关闭node,如果不是,那么就用
http://localhost:9200/_shutdown 来关闭吧

you see ? employee/1 要带上1,一般就是用key
GET /megacorp/employee/1*PUT插入数据,GET获取数据,DELETE删除数据,HEAD查询是否存在数据,更新数据?用PUT覆盖就行了
如果是搜索所有的记录,那么就
GET /megacorp/employee/_search
如果是要用轻量级的搜索,那么就
GET /megacorp/employee/_search?q=last_name:Smith
如果要用更加复杂一点的搜索方法,可以使用The domain-specific language (DSL)
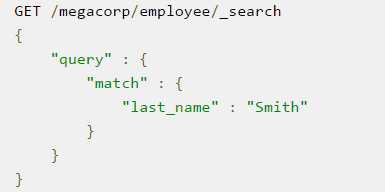
对于全文搜索来说,会匹配相关度的。可以精确匹配,也可以让关键词高亮
甚至可以做聚合分析和搜索嵌套
集群是这个搜索引擎的重头戏啊,通过在不同node上的shard部署,可以做到分布式搜索和容灾备份
创建index的时候,就可以指定分多少个shard,要冗余多少份
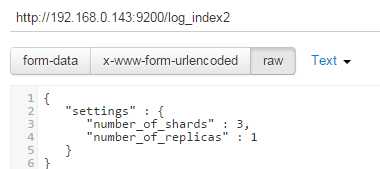
这里就指定了shards和replicas的数量,shards只在创建时指定,而replicas可以事后再修改的,默认都是一份rep
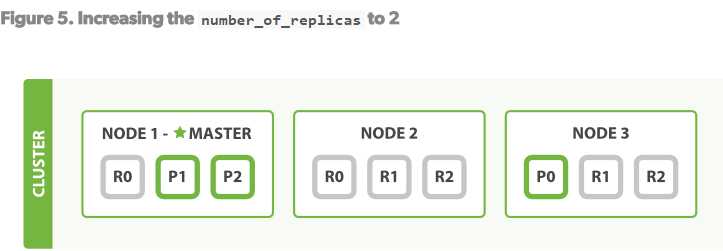
直接启动第二node的elasticsearch,然后会自动寻找到主节点进行replicas的拷贝的,完成后如下
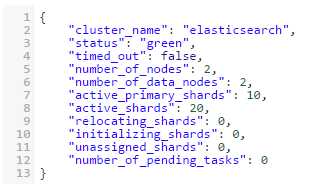
如果是1份拷贝,那么3台node就是
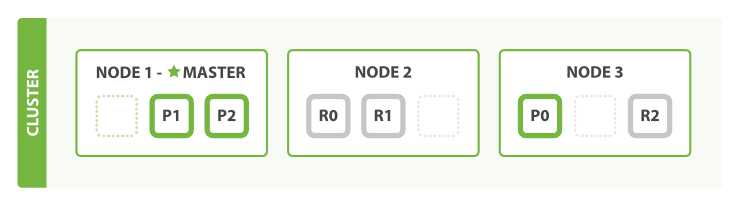
但是如果我们想scale更多,则可以提高rep的数量
如果是用URL方法去关闭某个node,则整个cluster就被关闭了,
如果是强制关闭某个node,那么就会降级成如下
集群会遇到些数据更新冲突等问题,
elasticsearch是通过_version这个metadata来检测是否出现更新冲突,如果冲突的就返回失败,由客户端自行决定
如何解决冲突,比如说再次获取最新数据,决定是否插入等。
因为引擎是为每个字段默认都建立了引索,所以如果是部分更新document,那么也是 retrieve-change-reindex process这个步骤 ,但是用自带update的API确保了在一个shards里完成这些步骤,减少到了网路耗时,这样也间接降低了更新冲突的可能性。
以下是目前官方所支持的客户端程序,通常都是封装好了,CRUD就像操作关系型数据库一样方便。
Clients & Integrations
标签:
原文地址:http://www.cnblogs.com/angular/p/4378046.html