标签:
clc;clear;
D=500;N=10000;thre=10e-8;zeroRatio=0.6;
X = randn(N,D);
r=rand(1,D);
r=sign(1-2*r).*(2+2*r);
perm=randperm(D);r(perm(1:floor(D*zeroRatio)))=0;
Y = X*r‘ + randn(N,1)*.1; % small added noise
lamda=1;stepsize=10e-5;
%%% y=x*beta‘
%%% Loss=0.5*(y-x*beta‘)_2++lamda|beta|
%%%% GD
%%% al_y/al_beta=sigma(x_i*(x_i*beta‘-y_i)+fabs(lamda))
beta=zeros(size(r));
pre_error=inf;new_error=0;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta‘-Y(j,:));
end
beta=beta-stepsize*(tmp+lamda);
new_error=lamda*norm(beta,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta‘)*(Y(j,:)-X(j,:)*beta‘);
end
disp(new_error)
end
% %%%% Proximal GD
% Loss=0.5*(y-x*beta‘)_2++lamda|beta|=g(x)+h(x)
% 左边可导 x_{t+1}=x_{t}-stepsize*sigma(x_i*(x_i*beta‘-y_i)
% X_{t+1}=prox_{l1-norm ball}(x_{t+1})=
disp(‘pgd‘)
beta_pgd=zeros(size(r));
pre_error=inf;new_error=0;
while abs(pre_error-new_error)>thre
pre_error=new_error;
tmp=0;
for j=1:length(Y)
tmp=tmp+X(j,:)*(X(j,:)*beta_pgd‘-Y(j,:));
end
newbeta=beta_pgd-stepsize*(tmp+lamda); add=stepsize*lamda;
pidx=newbeta>add;beta_pgd(pidx)=newbeta(pidx)-add;
zeroidx=newbeta<abs(add);beta_pgd(zeroidx)=0;
nidx=newbeta+add<0;beta_pgd(nidx)=newbeta(nidx)+add;
new_error=lamda*norm(beta,1);
for j=1:length(Y)
new_error=new_error+(Y(j,:)-X(j,:)*beta‘)*(Y(j,:)-X(j,:)*beta‘);
end
disp(new_error)
end
PGD的代码说明见下图
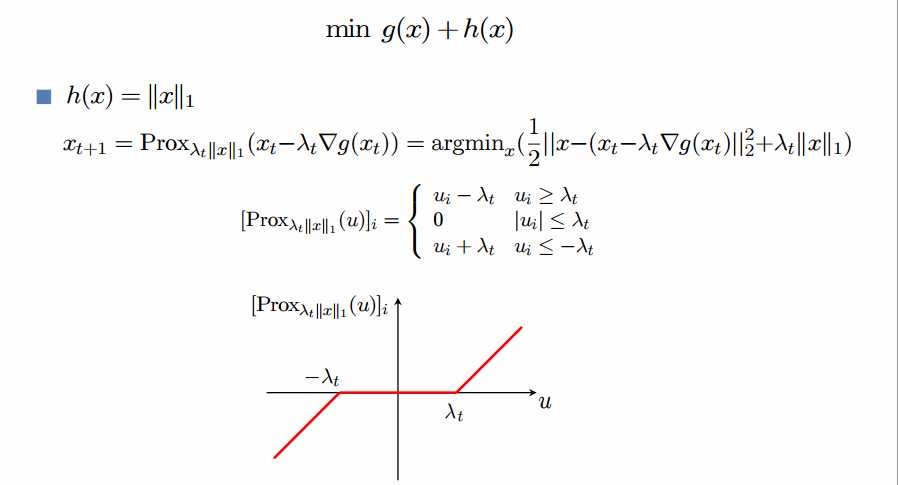
PGD主要是project那一步有解析解,速度快
subGradent收敛速度O(1/sqrt(T))
关于subGradent descent和Proximal gradient descent的迭代速度
标签:
原文地址:http://www.cnblogs.com/sylar120/p/4379378.html