标签:
我们继续研究kafka.utils包
八、KafkaScheduler.scala
首先该文件定义了一个trait:Scheduler——它就是运行任务的一个调度器。任务调度的方式支持重复执行的后台任务或是一次性的延时任务。这个trait定义了三个抽象方法:
1. startup: 启动调度器,用于接收调度任务
2. shutdown: 关闭调度器。一旦关闭就不再执行调度任务了,即使是那些晚于关闭时刻的任务。
3. schedule: 调度一个任务的执行。方法接收4个参数
3.1 任务名称
3.2 完全是副作用(side effect,返回Unit)的函数,用于任务调度时执行
3.3 延时时间
3.4 执行间隔,如果小于0,说明是一次性任务调度
3.5 延时时间单位,默认是毫秒
其次,该文件还定义了一个线程安全(使用@threadsafe标记)的KafkaScheduer实现了前面定义的Scheduler接口——该调度器主要是基于java concurrent包中的SchedulerThreadPoolExecutor类来实现线程池方式的任务调度。既然是线程池的方式,你在构造该类时需要提供线程数(threads),线程池中的线程名字前缀(threadNamePrefix,默认是kakfa-scheduler-)以及指定是否是后台守护进程(daemon),即这些线程不会阻塞JVM关闭。
该类定义了还定义了2个字段:一个是ScheduledThreadPoolExecutor对象持有该线程池,并标记为@volatile,保证对该对象的读取不走寄存器,直接内存读取,保证内存可见性。;另一个是AtomicInteger的schedulerThreadId,与线程池线程前缀一起组成和线程名称。AtomicInteger类型保证了对该变量的访问是线程安全的。KafkaScheduler实现了Scheduler trait,所以必须要实现startup、shutdown和schedule方法:
1. startup: 如果调度器正常关闭类字段executor应该总是null,所以在startup方法开始需要先判断executor是否为空,如果不为空抛出异常说明调度器可能已经运行。否则创建具有threads个线程的线程池,并设置线程池关闭后不再执行任何类型的调度任务(包括重复调度执行的后台任务和一次性的延迟调度任务)。之后创建一个线程工厂来初始化那些线程。这里用到了包中Utils.scala中的newThread方法来创建线程。后面谈到Utils.scala时我们再说。
2. ensureStarted: 一个纯副作用的函数,只会被用在shutdown方法中。主要目的就是确保调度器已经启动。就是单纯地判断executor是否为空,如果为空抛出异常。
3. shutdown: 在确保调度器是启动状态的前提下,调用ScheduledThreadPoolExecutor.shutdown方法并设置了1天的超时时间(注意,这里的1天是硬编码方式,不支持配置的方式),以阻塞的方式来等待shutdown请求被完整地执行。按照《Java concurrency in practice》的理论,这其实是一个阻塞方法(blocking method),严格来说应该允许用户发起中断机制,可能是开发人员觉得shutdown不会运行很长时间。当然也许是我说错了:)
4. schedule:调度器最重要的逻辑代码。在确保调度器已启动(调用ensureStarted)的前提下,调用Utils.scala的runnable方法(同样,我们后面再说)将指定的函数封装到一个Runnable对象中。然后判断调度任务的类型(如果period参数大于0,说明是需要重复调度执行的任务;反之是一次性的延时任务)调用ScheduledThreadPoolExecutor的不同方法(scheduleAtFixedRate或schedule)来执行这个runnable
九、Log4jController.scala
看名字就知道和Log4j管理相关。代码结构也很清晰:一对伴生对象(companion object)和一个私有trait。先说那个private trait:Log4jControllerMBean。既然是trait,通常都是类似于Java的接口,定义一些抽象方法:
1. getLoggers: 返回一个日志器名称的列表List[String]
2. getLogLevel: 获取日志级别
3. setLogLevel: 设置日志级别。不过与普通的setter方法不同的是,该方法返回一个boolean,原因后面在其实现类里面说。
既然定义了trait,自然也要有实现它的具体类:Log4jController——允许在运行时动态地修改log4j的日志级别。该类还提供了2个辅助私有方法:newLogger和existingLogger,加上实现Log4jControllerMBean声明的3个抽象方法,一共是5个方法:
1. newLogger: 创建一个日志器logger,可能是root logger,更可能是普通的logger。
2. existingLogger: 根据loggerName返回对应的logger
3. getLoggers: 返回当前的一组logger(也包括root logger),每个元素都是logger名称=日志级别这样的格式
4. getLogLevel: 根据给定的logger name获取对应的日志级别
5. setLogLevel: 设定日志级别。值得注意的是,如果loggerName为空或日志级别为空,返回false表明设置不成功
Log4jController object则很简单,只是初始化了一个Log4jController实例,并使用Utils.scala中的registerMBean方法将其注册到平台MBean服务器,注册名为kafka:type=kafka.Log4jController
十、Logger.scala
这个trait前面虽然没有怎么提及,但其实很多类都实现了这个trait。其名字含义就极具自描述性——就是操作日志的方法类。该trait还创建了一个logger对象——以lazy val的形式。Scala中的lazy表示延迟加载,只有第一次用到该logger时才初始化该值。因为很多类都实现了Logging trait,因此将logger作为一个lazy val是很有必要的,否则每次构造一个新的实现类实例时都要构建一个logger对象。这完全没必要,我们只有在用的时候在初始化岂不是很好吗?
另外,该trait还有一个logIdent字段,初始化为null,但因为是protected var,所以很明显是让实现该trait的子类来指定。从变量命名来看,似乎是表示日志标识符的格式。后面的代码中有大量的类都指定了不同的logIdent。
这个trait定义了大量的写日志方法,当然都是针对不同的日志级别,比如TRACE、DEBUG、INFO、WARN、ERROR和FATAL。有意思的是,每一个级别上都有一个swallow***方法——该方法会接收一个无返回值的函数(严格来说,返回值是Unit)然后运行该函数。如果碰到异常只是将异常记录下来,直接吞掉,而不是再次抛出。Utils.scala中的swallow方法帮忙实现了这个功能。鉴于Logging trait很多方法都是重复且很简单的,就不一一赘述了。
十一、Mx4jLoader.scala
该文件提供了一个object,主要启用JMX——使用-Dmx4jenable=true启用该特性。默认的ip地址和端口分别为0.0.0.0和8082。使用-Dmx4jport=8083和-Dmx4jaddress=127.0.0.1的方式来覆盖默认设置。在后面的KafkaServer中调用了Mx4jLoader.maybeLoad来加载JMX设置:
maybeLoad: 从名字来看——maybe load——也有可能不加载,要么是因为mx4j-tools jar包不在classpath下,要么是没有在配置文件中进行设置(默认也不是不开启的)。具体流程为:首先加载系统设置(Kafka实现了一个VerifiableProperties封装了java的Properties对象),然后查看是否存在kafka_mx4jenable属性。如果不存在直接返回false——表示不需要加载jmx。如果存在的话获取mx4jaddress和mx4jport属性。通过反射机制实例化HttpAdaptor对象实例以及XSLTProcessor对象实例(这两个类都是mx4j-tools提供的),然后对它们进行注册。如果中间过程捕获了ClassNotFoundException异常,直接返回false表明mx4j-tools jar包不在classpath;如果是MBean注册相关的异常,也返回false并抛出该异常。
十二、Os.scala
很短小精悍的一个object,只提供了name字符串和isWindows两个变量分别获取操作系统名称以及判断是否为Windows平台。
十三、Pool.scala
名字虽然是Pool(池),但字段pool的数据结构其实就是一个ConcurrentHashMap,更像是对ConcurrentHashMap数据结构做了一层封装,所以其提供的很多方法实现起来也都是直接调用ConcurrentHashMap的同名方法。而且也是泛型的——[K, V]。
值得注意的是, 这个类的构造函数接收一个Option[(K) => V]的参数类型,实际上就是Option[function],这个函数接收一个K类型的参数返回V类型的值,默认的类构造函数参数是None。它同时还提供了一个辅助构造函数,将一个Map中的[K,V]对赋值到这个类底层的HashMap上。
由于大多提供的方法都是调用标准的ConcurrentHashMap方法,我就不一一赘述了,但要特别地说一下getAndMaybePut方法:
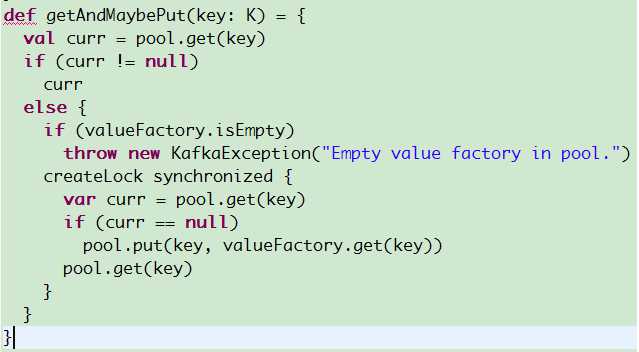
getAndMaybePut: 名字就很有自描述性——根据给定key获取value,如果不存在就增加这个key的记录——即从valueFactory中生成一个值增加到pool中,并返回该值。但是如果是增加的情况,value怎么取值呢?我们来看看代码。
从图中可以看到,代码先判断了valueFactory是否空,如果为空直接抛出异常。但其实我们可以先判断是否存在值,如果已经存在直接返回,即使valueFactory为空也没关系,因为我们此时不需要从valueFactory中生成一个值。因此我觉得可以讲代码改写为:
总之就是将valueFactory的非空判断推迟到需要使用它的时刻。还有一个需要注意的是,虽然这个方法使用了同步机制,但因为该类中还提供了其他的方法(比如put)可以对ConcurrentHashMap增加记录,因此getAndMaybePut返回的时候你可能会发现返回值与valueFactory计算的值不一样——这是因为另一个线程成功地插入了[key,value]对,当然这一切都是拜ConcurrentHashMap是基于CAS所赐。
十四、ReplicationUtils.scala
Kafka的消息要在集群间做持久化必须提供某种程度的冗余机制——即副本机制。类似于Hadoop,Kafka也有对应的副本因子(replication factor)。具体实现我们在谈及replication时候再说。这个文件提供的object只是副本机制使用的一个常用套件类。我们一个一个方法说:
1. parseLeaderAndIsr: ISR表示in-sync replicas,表示当前依然活跃(alive)且持有的状态与leader副本相差无多的一组副本。很自然地,我们需要定义与leader相差多少是我们能够承受的,可以通过两个参数配置:replica.lag.time.max.ms和replica.lag.max.messages。这个方法接收一个json格式的字符串,包含了leader、leader_epoch、一组isr列表和controller_epoch信息,解析之后返回一个LeaderIsrAndControllerEpoch对象。后者位于kafka.collections包中,就是一个简单的case类——主要目的是打印Leader和Isr的一些基本信息:包括id,时间epoch等——这些信息都要保存在ZooKeeper中。
2. checkLeaderAndIsrZkData: 顾名思义,检查给定zookeeper path上的leader和isr列表数据。使用ZkUtils.readDataMaybeNull读取对应路径上的数据(当然有可能是null),如果调用第一个方法parseLeaderAndIsr尝试做解析,如果成功元组(true, zookeeper版本),有任何异常出现则返回(false, -1)表明检查失败
3. updateLeaderAndIsr: 使用Zookeeper client对象更新保存于zk上的leader和isr信息。因为Kafka提供的副本机制是针对topic的分区而言的,所以该方法还接收一个partitionId。最后返回一个boolean值表明更新结果是否成功。代码逻辑也很清晰:先获取要更新的zookeeper路径,然后调用ZkUtils上的leaderAndIsrZkData方法组装新的json串,最后使用conditionUpdatePersistentPath方法执行更新操作。从名字来看这个更新是有条件的,也就是说有可能更新失败(比如path不存在,或当前版本不匹配等)。这两个方法等我们研究ZkUtils.scala时候再说。总之最后返回一个boolean表明更新是否成功。
总的来说,前两个方法主要服务于updateLeaderAndIsr方法,在kafka.cluster.Partition中也调用了updateLeaderAndIsr方法。
【原创】Kakfa utils源代码分析(二)
标签:
原文地址:http://www.cnblogs.com/huxi2b/p/4380155.html